机器学习实战第七章 - 利用AdaBoost元算法提高分类性能
2018-03-08 17:10
711 查看
一,AdaBoost概述
AdaBoost是adaptive boosting(自适应boosting)的缩写。AdaBoost是一种Boosting族的集成学习方法。弱学习器之间是强依赖序列化的,即不同的学习器是通过串行训练而获得的,每个新分类器都根据已训练出来的分类器的性能来进行训练。Boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。
AdaBoost特点如下:
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型。
二,AdaBoost具体流程:基于错误提升分类器的性能
1,具体流程
训练数据中的每个样本并赋予其一个权重, 这些权重构成了样本权重向量D。一开始这些样本权重都是初始化为相等值。首先在训练数据上训练出一个弱分类器,并计算弱分类器的错误率,然后在同一数据集再次训练弱分类器。
在分类器的第二次训练当中,将会重新调整每个样本的权重, 其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。
最终的分类结果是所有弱分类器的线性加权求和的结果,其中每个弱分类器的权重α是基于每个弱分类器的错误率来进行计算的。具体如下:
错误率ε定义如下:
ε=错误分类样本数所有样本分类数
则α的计算公式如下(由最小化指数损失函数得到):
α=12ln1−εε
函数图像如下:
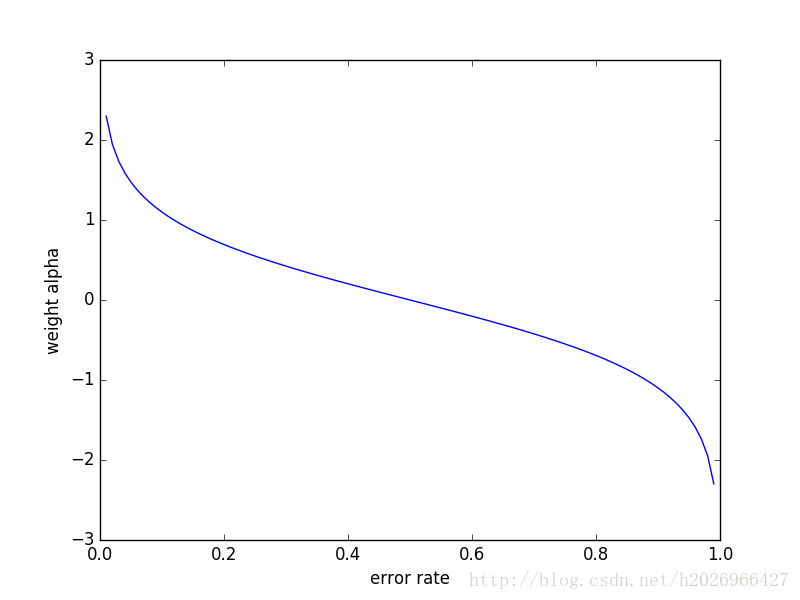
即错误率越大权重越小。
计算出α之后,就可以对样本权重向量进行更新,上一次正确分类的样本权重降低,错误分类的样本权重升高。
正确分类的样本权重更改为:
D(t+1)i=D(t)ie−αSum(D)
错误分类的样本权重更改为:
D(t+1)i=D(t)ieαSum(D)
这些计算公式也是由最小化分类误差确定的,具体推导过程省略。
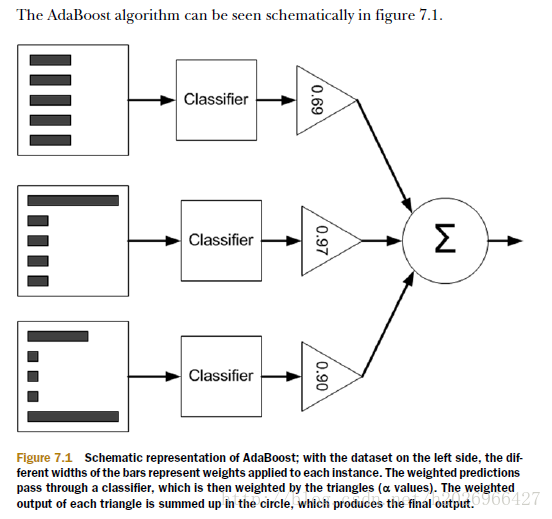
在计算出D之后,AdaBoost又开始进入下一轮迭代。AdaBoost会不断重复训练和调整权重,直至训练错误率为0或弱分类器的数目达到用户的指定值为止。
如下图所示:
2,伪代码

三,AdaBoost的实现
1,基于单层决策树构建弱分类器
单层决策树也成决策树桩,是最简单的一种决策树。构建伪代码如下:

Python代码如下:
def buildStump(dataArray,classLabels,D):
dataMat = mat(dataArray)
labelsMat = mat(classLabels).T
m,n = shape(dataMat)
numSteps = 10.0
bestStump = {}
minError = inf
bestclasEst = mat(zeros((m,1)))
for i in range(n):
rangeMin = dataMat[:,i].min()
rangeMax = dataMat[:,i].max()
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = rangeMin+float(j)*stepSize
predictedVal = ones((m,1))
if inequal == 'lt':
predictedVal[dataMat[:,i]<=threshVal] = -1.0
else:
predictedVal[dataMat[:,i]>threshVal] = -1.0
errorArr = ones((m,1))
errorArr[predictedVal==labelsMat] = 0
weightedError = float(D.T*errorArr)
print("dimen:%d,thresh:%.2f,thresh inequal:,%s,weighted error: %.3f"%(i,threshVal,inequal,weightedError))
if weightedError < minError:
minError = weightedError
bestclasEst = predictedVal.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestclasEst单层决策树只需要保存Dim、ThreshVal、InEquality和alpha即可。
单层决策树的生成函数是决策树的一个简化版本,也就是所谓的弱分类器,下面就将使用多个弱分类器来构建AdaBoost算法。
2,AdaBoost算法的实现
伪代码如下:
Python代码如下:
def adaBoostTrainsDS(dataArr,classLabels,numIt=40):
weakClassArr = []
dataMat = mat(dataArr)
m = shape(dataMat)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataMat,classLabels,D)
alpha = 0.5*log((1-error)/max(error,1e-16))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = multiply(-alpha*mat(classEst),mat(classLabels).T)
D = multiply(D,exp(expon))
D = D/D.sum()
aggClassEst += alpha*classEst
aggError = multiply(sign(aggClassEst)!=mat(classLabels).T,ones((m,1)))
errorRate = aggError.sum()/m
print('the total error is:%.2f'%(errorRate))
if errorRate==0:
break
return weakClassArr用户需要指定训练的迭代次数。
3,测试算法:基于AdaBoost的分类
Python代码如下:def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): retArray = ones((shape(dataMatrix)[0],1)) if threshIneq=='lt': retArray[dataMatrix[:,dimen]<=threshVal] = -1.0 else: retArray[dataMatrix[:,dimen]>threshVal] = -1.0 return retArray def adaClassify(datToClass,classifierArr): dataMat = mat(datToClass) m = shape(dataMat)[0] aggClassEst = mat(zeros((m,1))) for i in range(len(classifierArr)): classEst = stumpClassify(dataMat,classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq']) aggClassEst += classEst*classifierArr[i]['alpha'] print(aggClassEst) return sign(aggClassEst)
4,在一个难的数据集上应用AdaBoost
读文件数据的代码:def loadDataSet(filename):
numFeat = len(open(filename).readline().split('\t'))-1
fr = open(filename)
dataArr = []
classLabels = []
for line in fr.readlines():
lineArr = line.strip().split('\t')
featureArr = []
for j in range(numFeat):
featureArr.append(float(lineArr[j]))
dataArr.append(featureArr)
classLabels.append(float(lineArr[-1]))
dataMat = mat(dataArr)
return dataMat,classLabels使用AdaBoost进行预测的过程如下:
>>> datArr,labelArr = adaboost.loadDataSet('horseColicTraining2.txt')
>>> classifierArray = adaboost.adaBoostTrainDS(datArr,labelArr,10)
total error: 0.284280936455
total error: 0.284280936455
.
.
total error: 0.230769230769
>>> testArr,testLabelArr = adaboost.loadDataSet('horseColicTest2.txt')
>>> prediction10 = adaboost.adaClassify(testArr,classifierArray)
To get the number of misclassified examples type in:
>>> errArr=mat(ones((67,1)))
>>> errArr[prediction10!=mat(testLabelArr).T].sum()
16.0
>>> 16/67
0.23880597014925373四,AdaBoost总结
通常情况下,AdaBoost会达到一个稳定的测试错误率,而并不会随着弱分类器数目的增多而增加。很多人认为,AdaBoost和SVM是监督机器学习中最强大的两种方法。
AdaBoost这种针对错误的调节能力正是它的强大之处。
总之,AdaBoost算法十分强大,它能快速处理其他分类器很难处理的数据集。

相关文章推荐
- 机器学习实战笔记-利用AdaBoost元算法提高分类性能
- 机器学习实战代码详解(七)利用AdaBoost元算法提高分类性能
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
- 机器学习实战(七)利用AdaBoost元算法提高分类性能
- 机器学习实战(7) ——利用AdaBoost元算法提高分类性能(python实现)
- AdaBoost元算法如何提高分类性能——机器学习实战
- 读书笔记:机器学习实战【第7章:利用Adaboost元算法提高分类性能】
- 第七章 利用AdaBoost元算法提高分类性能
- 机器学习之利用AdaBoost元算法提高分类性能
- 代码注释:机器学习实战第7章 利用AdaBoost元算法提高分类性能
- 【机器学习实战-python3】Adaboost元算法提高分类性能
- 机器学习实战-利用AdaBoost元算法提高分类性能
- [完]机器学习实战 第七章 利用AdaBoost元算法提高分类性能
- 利用adaboost元算法提高分类性能
- 机器学习实战读书笔记----利用Adaboost元算法提高分类性能
- 《机器学习实战》学习笔记:利用Adaboost元算法提高分类性能
- 利用AdaBoost元算法提高分类性能
- 机器学习实战——利用AdaBoost元算法提高分类性能
- 利用AdaBoost元算法提高分类性能
- 《机器学习实战》笔记之七——利用AdaBoost元算法提高分类性能