python爬取豆瓣图书Top250
2017-03-19 21:41
483 查看
平台
python3.5windows 10
目标结构
最近想学习一下python爬虫,所以目标定在豆瓣读书top250。结构简单,没有js加载的内容等,感觉比较适合入门新手来爬取。首先看一下top250的网页结构,chrome浏览器,通过F12查看。
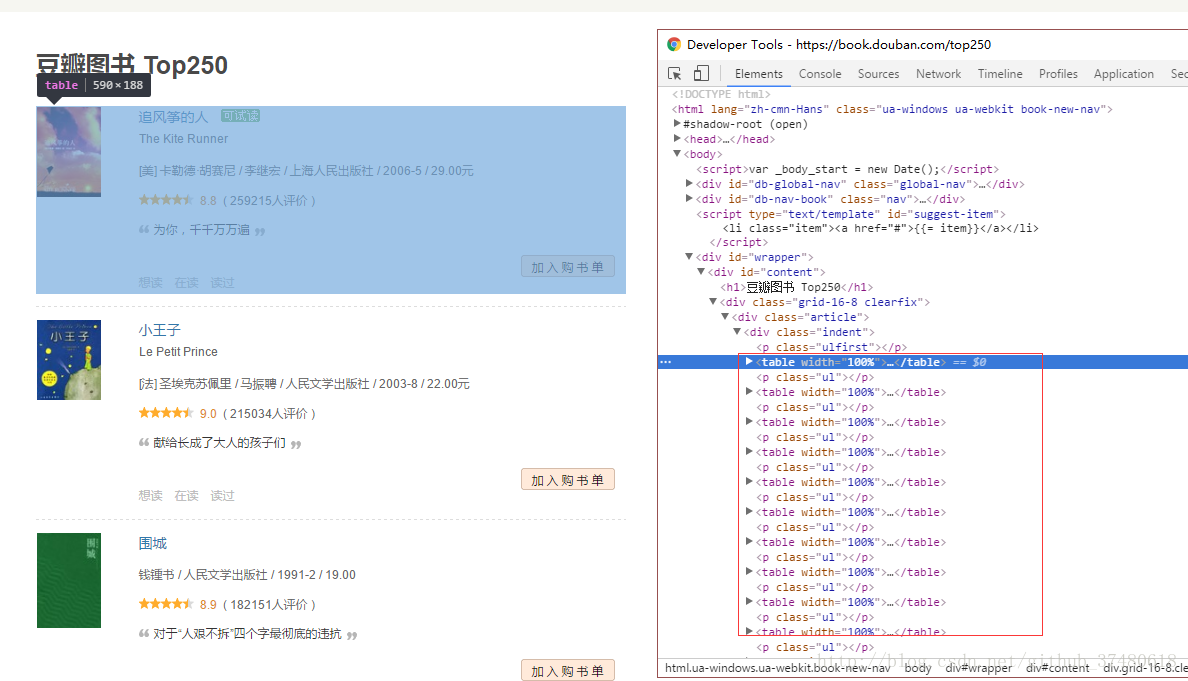
可以看到每本书的条目,对应的网页里是一个table的标签。继续点开箭头,可以看到一本书中具体的内容结构:

准备爬取的内容主要是书名、别名、信息、评分、人数、描述
以《追风筝的人》为例:
书名:追风筝的人
别名:The Kite Runner
信息:[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元
评分:8.8
人数:259215
描述:为你,千千万万遍
爬取
主要使用了三个python库,requests,lxml,BeautifulSouprequests库主要是获取网页的内容和结构
lxml库用来解析网页
BeautifulSoup则是用来抽取网页中的文本信息
贴上代码:
#!/usr/bin/env python
# encoding: utf-8
import re
import requests
from bs4 import BeautifulSoup
def book(target_url):
books = []
book = requests.get(target_url) #使用requests返回网页的整体结构
soup = BeautifulSoup(book.text, 'lxml') # 使用lxml作为解析器,返回一个Beautifulsoup对象
table = soup.findAll('table', {"width": "100%"}) #找到其中所有width=100%的table标签),即找到所有的书
for item in table: #遍历table,一个item代表一本书
name = item.div.a.text.strip() #找到书名
r_name = name.replace('\n', '').replace(' ', '') #通过看网页的HTML结构,可以发现书名后是有换行以及空格的,将这些全部通过replace替换去除
tmp2 = item.div.span #判断是否存在别名
if tmp2:
name2 = tmp2.text.strip().replace(':', '') #因为是通过div.span判断别名 有些书的别名前面有个冒号,比如《三体系列》
else:
name2 = r_name #无别名就使用原始的名称
url = item.div.a['href'] #获取书的链接
info = item.find('p', {"class": "pl"}).text #获取书的信息
score = item.find('span', {"class": "rating_nums"}).text.strip() #获取分数
nums = item.find('span', {"class": "pl"}).text.strip() # 获取评价人数
num = re.findall('(\d+)人评价', nums)[0] # 通过正则取具体的数字
if item.find('span', {"class": "inq"}): # 判断是否存在描述
desc = item.find('span', {"class": "inq"}).text.strip()
else:
desc = 'no description'
books.append((r_name, name2, url, info, score, num, desc)) #以元组存入列表
return books #返回一页的书籍
for n in range(10):
url1 = 'https://book.douban.com/top250?start=' + str(n*25) #top250的网页,每页25本书,共10页,“start=”后面从0开始,以25递增
tmp = book(url1)
with open('booktop250.xls', 'a', encoding='utf-8') as d: #新建一个文件存放数据,模式取'a',表示在后面追加;编码一定要写上,因为win下新建文件,默认是gbk编码,但是前面返回的结构是unicode的,会报编码错误
for i in tmp:
print(i[0]+"\t"+i[1]+"\t"+i[2]+"\t"+i[3]+"\t"+i[4]+"\t"+i[5]+"\t"+i[6], file=d)最后保存的文件是xls文件,直接打开的话,会是乱码。解决方法是,用记事本这个xls文件,然后另存为的时候,编码方式选ANSI,这样就能打开xls文件了。当然如果直接使用txt文件保存的话,就不需要这么麻烦。
最后的抓取的结果如下:

补充材料
Requests文档BeautifulSoup文档
均为中文

相关文章推荐
- python爬虫实现获取豆瓣图书的top250的信息-beautifulsoup实现
- 简单的python爬虫爬豆瓣图书TOP250
- [Python爬虫]2.豆瓣图书Top250
- python 爬虫实战(一)爬取豆瓣图书top250
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
- 【Python数据分析】Python3操作Excel-以豆瓣图书Top250为例
- Python 采用Scrapy爬虫框架爬取豆瓣电影top250
- python爬豆瓣电影Top250
- [Python爬虫]1.豆瓣电影Top250
- python爬取豆瓣电影Top250
- Python+Scrapy 爬取豆瓣电影排行榜Top250
- Python爬虫豆瓣电影top250
- Python 3.5爬取豆瓣top250—优化(面向对象编程)
- python第一只爬虫:爬豆瓣top250
- 爬取豆瓣图书Top250书籍信息
- python中lxml+cssselect爬取豆瓣电影Top250
- Python爬虫----抓取豆瓣电影Top250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- [151116 记录] 使用Python3.5爬取豆瓣电影Top250