统计学总结之Bias(偏差),Error(误差),和Variance(方差)的区别
2017-03-18 18:17
603 查看
参考:
http://blog.csdn.net/qq_16365849/article/details/50635700 http://mp.weixin.qq.com/s?__biz=MzI5OTQ1Njc0NQ==&mid=2247484595&idx=1&sn=722924207949982c3ae47bc5f8c39a5c&chksm=ec970535dbe08c23a7203b7c37d5a3bf98d5b81476be3a03c6f4cd17e192f54c49b7bdda79a0&mpshare=1&scene=1&srcid=0318xfwQm9ax3MysC9TVbiE2#rd
目录(?)[-]
Bias偏差Error误差和Variance方差的区别
1概念
2bias与Variance的区别
3解决bias和Variance问题的方法
variance :则度量了在面对同样规模的不同训练集时分散程度。(一个高的方差意味着一个弱的匹配,数据比较分散)

靶心为某个能完美预测的模型,离靶心越远,则准确率随之降低。靶上的点代表某次对某个数据集上学习某个模型。纵向上,高低的bias:高的Bias表示离目标较远,低bias表示离靶心越近;横向上,高低的variance,高的variance表示多次的“学习过程”越分散,反之越集中。
所以bias表示预测值的均值与实际值的差值;而variance表示预测结果作为一个随机变量时的方差。
一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合。
偏差:
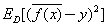
方差:
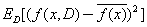
首先 Error = Bias + Variance
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望(平均值)之间的误差,即模型的稳定性,数据是否集中。
方差是多个模型间的比较,而非对一个模型而言的;偏差可以是单个数据集中的,也可以是多个数据集中的。

①在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
一种方法叫做K-fold Cross Validation (K折交叉验证), K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。
当K值大的时候,我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候,我们会有更多的Bias(偏差), 更少的Variance。
cross-validation很大一个好处是避免对test dataset的二次overfitting。k-fold一般取k=5/10比较常见,当然也可以根据你的需要(看样本量怎么可以整除啦之类的),也要看电脑和软件的运算能力。
②Boosting通过样本变权全部参与,故Boosting 主要是降低 bias(同时也有降低 variance 的作用,但以降低 bias为主);而 Bagging 通过样本随机抽样部分参与(单个学习器训练),故bagging主要是降低 variance。
③High bias解决方案:
1)与领域专家交流来获取更多信息,据此增加更多熟人特征
2)以非线性方式对现有特征进行组合
3)使用更复杂模型,比如神经网络中的层等
High Variance:
如果问题是由于我们过度高估模型复杂度而导致的high Variance,那么可以把一些影响小的特征去掉来降低模型复杂度。此时也无需收集更多数据。
为什么说朴素贝叶斯是高偏差低方差?
它简单的假设了各个特征之间是无关的,是一个被严重简化了的模型。所以,对于这样一个简单模型,大部分场合都会bias部分大于variance部分,也就是高偏差,低方差
http://blog.csdn.net/qq_16365849/article/details/50635700 http://mp.weixin.qq.com/s?__biz=MzI5OTQ1Njc0NQ==&mid=2247484595&idx=1&sn=722924207949982c3ae47bc5f8c39a5c&chksm=ec970535dbe08c23a7203b7c37d5a3bf98d5b81476be3a03c6f4cd17e192f54c49b7bdda79a0&mpshare=1&scene=1&srcid=0318xfwQm9ax3MysC9TVbiE2#rd
目录(?)[-]
Bias偏差Error误差和Variance方差的区别
1概念
2bias与Variance的区别
3解决bias和Variance问题的方法
Bias(偏差),Error(误差),和Variance(方差)的区别
1)、概念:
bias :度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(一个高的偏差意味着一个坏的匹配)variance :则度量了在面对同样规模的不同训练集时分散程度。(一个高的方差意味着一个弱的匹配,数据比较分散)
靶心为某个能完美预测的模型,离靶心越远,则准确率随之降低。靶上的点代表某次对某个数据集上学习某个模型。纵向上,高低的bias:高的Bias表示离目标较远,低bias表示离靶心越近;横向上,高低的variance,高的variance表示多次的“学习过程”越分散,反之越集中。
所以bias表示预测值的均值与实际值的差值;而variance表示预测结果作为一个随机变量时的方差。
一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合。
偏差:
方差:
2)、bias与Variance的区别:
首先 Error = Bias + Variance Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望(平均值)之间的误差,即模型的稳定性,数据是否集中。
方差是多个模型间的比较,而非对一个模型而言的;偏差可以是单个数据集中的,也可以是多个数据集中的。
3)、解决bias和Variance问题的方法:
①在训练数据上面,我们可以进行交叉验证(Cross-Validation)。 一种方法叫做K-fold Cross Validation (K折交叉验证), K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。
当K值大的时候,我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候,我们会有更多的Bias(偏差), 更少的Variance。
cross-validation很大一个好处是避免对test dataset的二次overfitting。k-fold一般取k=5/10比较常见,当然也可以根据你的需要(看样本量怎么可以整除啦之类的),也要看电脑和软件的运算能力。
②Boosting通过样本变权全部参与,故Boosting 主要是降低 bias(同时也有降低 variance 的作用,但以降低 bias为主);而 Bagging 通过样本随机抽样部分参与(单个学习器训练),故bagging主要是降低 variance。
③High bias解决方案:
1)与领域专家交流来获取更多信息,据此增加更多熟人特征
2)以非线性方式对现有特征进行组合
3)使用更复杂模型,比如神经网络中的层等
High Variance:
如果问题是由于我们过度高估模型复杂度而导致的high Variance,那么可以把一些影响小的特征去掉来降低模型复杂度。此时也无需收集更多数据。
为什么说朴素贝叶斯是高偏差低方差?
它简单的假设了各个特征之间是无关的,是一个被严重简化了的模型。所以,对于这样一个简单模型,大部分场合都会bias部分大于variance部分,也就是高偏差,低方差

相关文章推荐
- 统计学总结之Bias(偏差),Error(误差),和Variance(方差)的区别
- 统计学总结之Bias(偏差),Error(误差),和Variance(方差)的区别
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?(转)
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
- 机器学习:Bias(偏差),Error(误差),和Variance(方差)
- 机器学习基础(一)机器学习中的Bias(偏差),Error(误差),和Variance(方差)
- 机器学习中的误差(Error)、偏差(Bias)与方差(Variance)
- Bias(偏差),Error(误差),Variance(方差),和K-fold Cross Validation的关系(机器学习核心)
- 模型评估与选择 ( Bias(偏差),Error(误差),和Variance(方差) )
- 机器学习入门系列03,Error的来源:偏差和方差(bias 和 variance)
- 机器学习入门系列03,Error的来源:偏差和方差(bias和variance)
- 模型选择之诊断偏离bias和方差variance的区别
- 偏差,方差,训练误差,测试误差的区别