机器学习(周志华) 习题3.5 个人笔记
2017-03-12 10:06
316 查看
3.5 编程实现线性判别分析,并给出西瓜数据集3.0a上的结果。
附上代码:# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
data = [[0.697,0.460,1],
[0.774,0.376,1],
[0.634,0.264,1],
[0.608,0.318,1],
[0.556,0.215,1],
[0.403,0.237,1],
[0.481,0.149,1],
[0.437,0.211,1],
[0.666,0.091,0],
[0.243,0.267,0],
[0.245,0.057,0],
[0.343,0.099,0],
[0.639,0.161,0],
[0.657,0.198,0],
[0.360,0.370,0],
[0.593,0.042,0],
[0.719,0.103,0]] # 2 attributes(column),17 instances(row)
data = np.array([i[:-1] for i in data])
X0 = np.array(data[:8])
X1 = np.array(data[8:])
miu0 = np.mean(X0,axis=0).reshape((-1,1))
miu1 = np.mean(X1,axis=0).reshape((-1,1))
cov0 = np.cov(X0,rowvar=False)
cov1 = np.cov(X1,rowvar=False)
scatter_w = np.mat(cov0 + cov1)
omiga = scatter_w.I * (miu0-miu1)
plt.scatter(X0[:,0],X0[:,1],label='+')
plt.scatter(X1[:,0],X1[:,1],label='-')
plt.plot([0,1],[0,-omiga[0]/omiga[1]],label='y')
plt.legend()
plt.show()
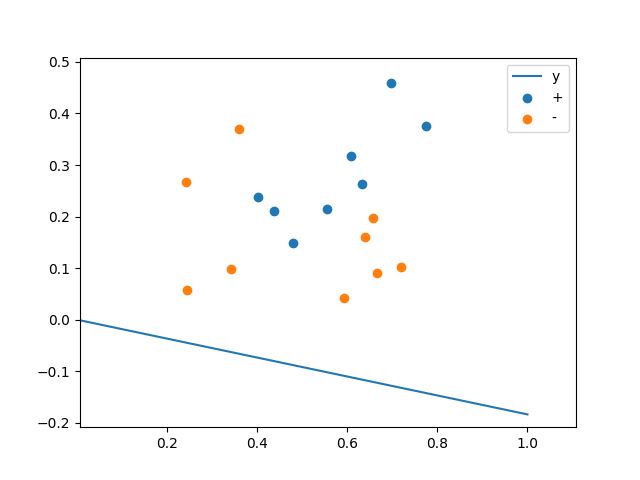
下图为所得到的超平面(本题为二维数据,因而超平面为线),由此可见,LDA对上述数据集的分类错误率为3/17。

相关文章推荐
- 《机器学习》(周志华) 习题3.1-3.3个人笔记
- 机器学习(周志华) 习题7.3 个人笔记
- 绪论(2)--周志华机器学习学习笔记与课后习题
- 绪论(1)--周志华机器学习学习笔记与课后习题
- 绪论(3)--周志华机器学习学习笔记与课后习题
- 机器学习(周志华版) 第一章习题1.1个人解答
- 《机器学习》周志华 习题答案3.5
- 《机器学习》周志华 习题答案 10.1
- 机器学习基石之Theory of Generalization的个人理解笔记
- 『机器学习——周志华』学习笔记——第一章
- 『机器学习——周志华』学习笔记——第二章:模型评估与选择
- 《机器学习》周志华 习题答案9.4
- 《机器学习》周志华 习题答案3.6
- 《机器学习(周志华)》习题10.1 答案
- 《机器学习》周志华 习题答案7.3
- 《机器学习》周志华 习题答案8.3
- 《机器学习》周志华第四章笔记
- 机器学习 周志华 读书笔记 习题1.2
- 《机器学习 (周志华)》习题7.3答案
- 《机器学习(周志华)》P19-习题1.1