基于spark之上的即席分析-卓越性能
2017-03-06 16:37
239 查看
为探索性分析与即席分析而设计
YDB全称延云YDB:是一个基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的秒级性能表现,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引:精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark直接对YDB检索结果集分析计算,同样场景让Spark性能加快百倍。
1. 稽查布控场景性能
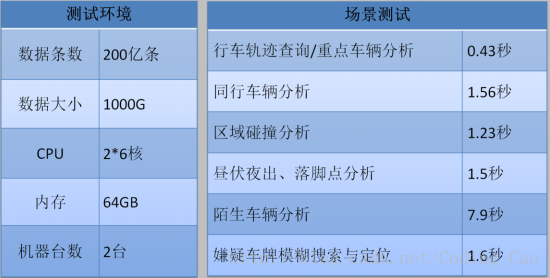
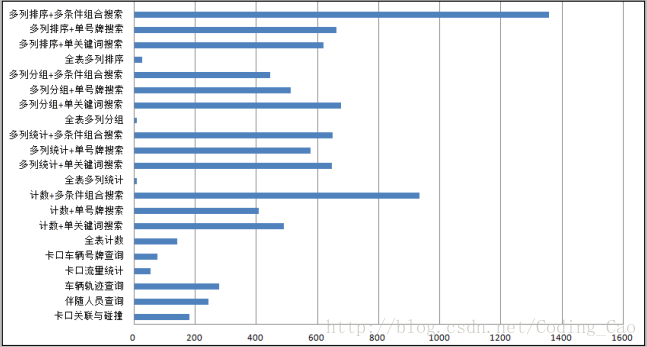
2. 卓越的检索与分析性能
与 Spark txt 性能对比(提升倍数)
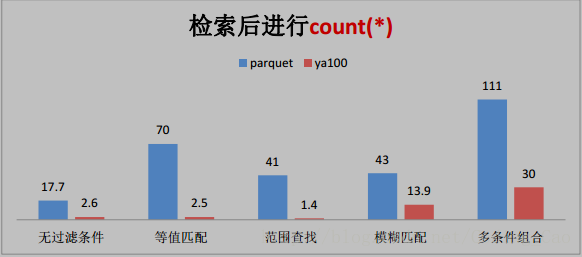
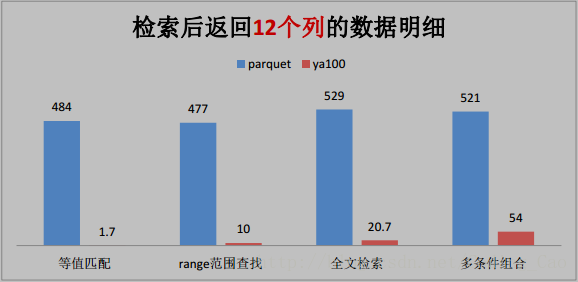
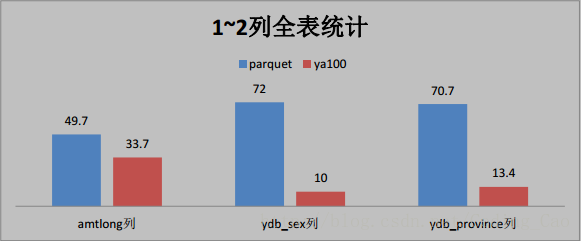
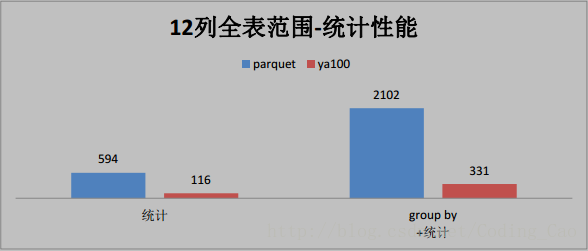
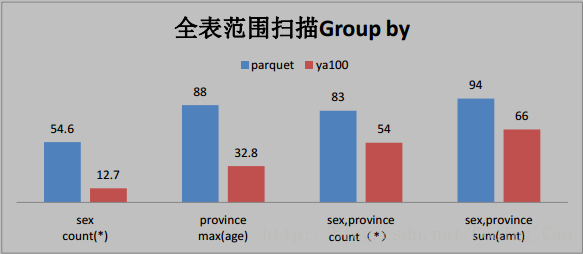
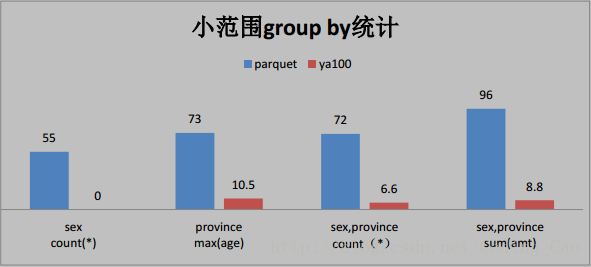
与 Parquet 格式对比(单位为秒)
与 Oracle 性能对比

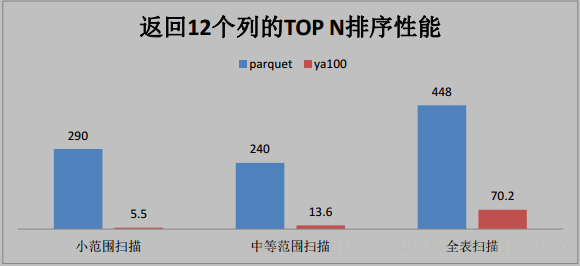
3. 卓越的排序性能
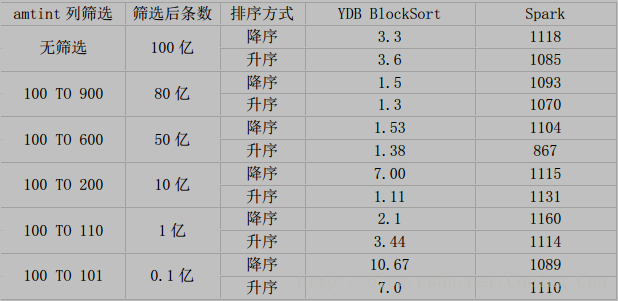
按照时间逆序排序可以说是很多日志系统的硬指标。在延云 YDB 系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为 BlockSort,目前支持 tlong、 tdouble、 tint、 tfloat 四种数据类型。
由于 BlockSort 是借助搜索的索引来实现的,所以采用 BlockSort 的排序,不需要暴力扫描,性能有大幅度的提升。
BlockSort 的排序,并非是预计算的方式,可以进行全表进行排序,也可以基于任意的过滤筛选条件进行过滤排序。
详细测试地址: http://blog.csdn.net/qq_33160722/article/details/54447022
300亿条数据的排序演示视频 http://blog.csdn.net/qq_33160722/article/details/54834896
测试结果(时间单位为秒)
YDB全称延云YDB:是一个基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的秒级性能表现,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引:精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark直接对YDB检索结果集分析计算,同样场景让Spark性能加快百倍。
1. 稽查布控场景性能
2. 卓越的检索与分析性能
与 Spark txt 性能对比(提升倍数)
与 Parquet 格式对比(单位为秒)
与 Oracle 性能对比
3. 卓越的排序性能
按照时间逆序排序可以说是很多日志系统的硬指标。在延云 YDB 系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为 BlockSort,目前支持 tlong、 tdouble、 tint、 tfloat 四种数据类型。
由于 BlockSort 是借助搜索的索引来实现的,所以采用 BlockSort 的排序,不需要暴力扫描,性能有大幅度的提升。
BlockSort 的排序,并非是预计算的方式,可以进行全表进行排序,也可以基于任意的过滤筛选条件进行过滤排序。
详细测试地址: http://blog.csdn.net/qq_33160722/article/details/54447022
300亿条数据的排序演示视频 http://blog.csdn.net/qq_33160722/article/details/54834896
测试结果(时间单位为秒)

相关文章推荐
- 基于spark之上的即席分析-卓越性能
- 基于spark之上的即席分析-日志分析场景
- 基于spark之上的即席分析-spark内存泄漏及源码调优
- 基于spark之上的即席分析-日志分析场景
- 基于spark之上的即席分析-spark内存泄漏及源码调优
- 记一次基于Unity的Profiler性能分析
- 第10章 基于linux服务器的性能分析与优化 (笔记)
- 基于GPU上的非结构化网格应用的性能分析和改进[1]
- 基于linux服务器的性能分析与优化(五)
- 基于Linux服务器的性能分析与优化2
- 基于Linux服务器的性能分析与优化
- LR 杂记--LoadRunner基于事务进行性能分析
- 基于linux服务器的性能分析与优化(四)
- (2)基于Linux服务器的性能分析与优化
- 基于Web应用的性能分析及优化案例
- 基于Linux服务器的性能分析与优化(2)
- 基于Jave EE和AJAX的办公自动化系统架构设计和基准性能分析
- 基于Linux服务器的性能分析与优化(1)
- 基于linux服务器的性能分析与优化(三)
- 基于STK的升级丹麦眼镜蛇雷达系统性能分析