基于spark之上的即席分析-spark内存泄漏及源码调优
2017-03-06 15:56
274 查看
spark 内存泄露
高并发情况下的内存泄露的具体表现很遗憾, spark 的设计架构并不是为了高并发请求而设计的,我们尝试在网络条件不好的集群下,进行 100 并发的查询,在压测 3 天后发现了内存泄露。
a) 在进行大量小 SQL 的压测过程中发现,有大量的 activejob 在 spark ui 上一直处于 pending 状态,且永远不结束,如下图所示
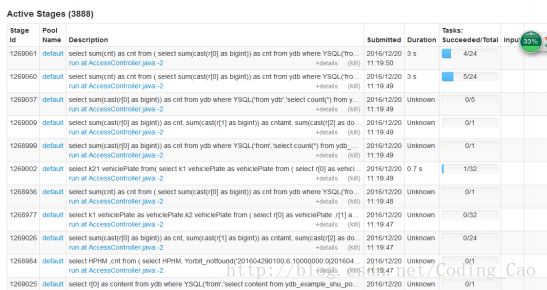
b) 并且发现 driver 内存爆满
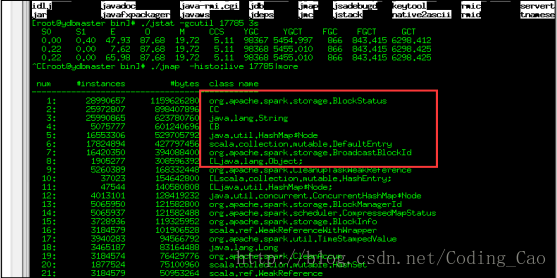
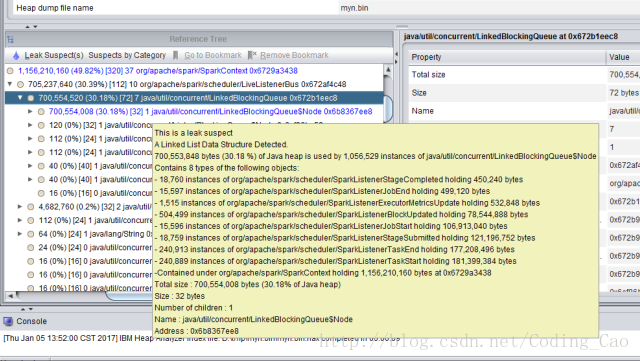
c) 用内存分析分析工具分析了下
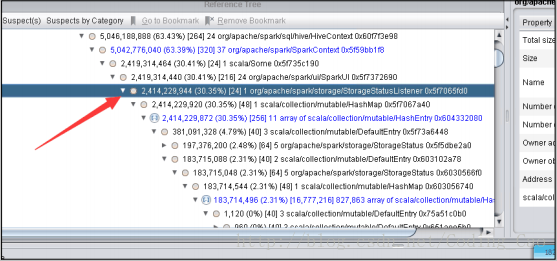
高并发下 AsynchronousListenerBus 引起的 WEB UI 的内存泄露
短时间内 SPARK 提交大量的 SQL ,而且 SQL里面存在大量的 union与 join的情形,会创建大量的 event对象,使得这里的 event 数量超过 10000 个 event ,一旦超过 10000 个 event 就开始丢弃 event,而这个 event 是用来回收 资源的,丢弃了 资源就无法回收了。 针对 UI 页面的这个问题,我们将这个队列长度的限制给取消了。
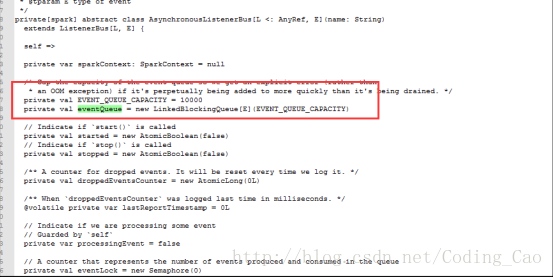
AsynchronousListenerBus 本身引起的内存泄露
抓包发现
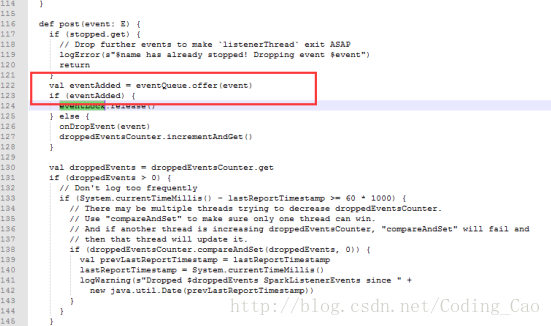
这些 event 是通过 post 方法传递的,并写入到队列里
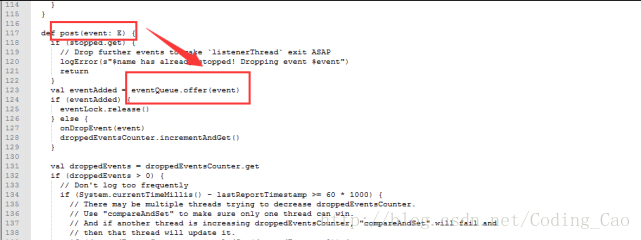
但是也是由一个单线程进行 postToAll 的

但是在高并发情况下,单线程的 postToAll 的速度没有 post 的速度快,会导致队列堆积的event 越来越多,如果是持续性的高并发的 SQL 查询,这里就会导致内存泄露
接下来我们在分析下 postToAll 的方法里面,那个路径是最慢的,导致事件处理最慢的逻辑是那个?

可能您都不敢相信,通过 jstack 抓取分析,程序大部分时间都阻塞在记录日志上
可以通过禁用这个地方的 log 来提升 event 的速度
log4j.logger.org.apache.spark.scheduler=ERROR

高并发下的 Cleaner 的内存泄露
说到这里, Cleaner 的设计应该算是 spark 最糟糕的设计。 spark 的 ContextCleaner 是用于回收与清理已经完成了的 广播 boradcast,shuffle 数据的。但是高并发下,我们发现这个地方积累的数据会越来越多,最终导致 driver 内存跑满而挂掉。
a)我们先看下,是如何触发内存回收的

没错,就是通过 System.gc() 回收的内存,如果我们在 jvm 里配置了禁止执行 System.gc,这个逻辑就等于废掉(而且有很多 jvm 的优化参数一般都推荐配置禁止 system.gc 参数)
b)clean 过程
这是一个单线程的逻辑,而且每次清理都要协同很多机器一同清理,清理速度相对来说比较慢,但是SQL 并发很大的时候,产生速度超过了清理速度,整个 driver 就会发生内存泄露。而且 brocadcast 如果占用内存太多,也会使用非常多的本地磁盘小文件,我们在测试中发现,高持续性并发的情况下本地磁盘用于存储 blockmanager 的目录占据了我们 60%的存储空间。

我们再来分析下 clean 里面,那个逻辑最慢

真正的瓶颈在于 blockManagerMaster 里面的 removeBroadcast,因为这部分逻辑是需要跨越多台机器的。
针对这种问题,我们在 SQL 层加了一个 SQLWAITING 逻辑,判断了堆积长度,如果堆积长度超过了我们的设定值,我们这里将阻塞新的 SQL 的执行。堆积长度可以通过更改 conf 目录下的 ya100_env_default.sh 中的ydb.sql.waiting.queue.size 的值来设置。

–建议集群的带宽要大一些,万兆网络肯定会比千兆网络的清理速度快很多。
–给集群休息的机会,不要一直持续性的高并发,让集群有间断的机会。
–增大 spark 的线程池,可以调节 conf 下的 spark-defaults.conf 的如下值来改善。

线程池与 threadlocal 引起的内存泄露
发现 spark, hive, lucene 都非常钟爱使用 threadlocal 来管理临时的 session 对象,期待 SQL 执行完毕后这些对象能够自动释放,但是与此同时 spark 又使用了线程池,线程池里的线程一直不结束,这些资源一直就不释放,时间久了内存就堆积起来了。
针对这个问题,延云修改了 spark 关键线程池的实现,更改为每 1 个小时,强制更换线程池为新的线程池,旧的线程数能够自动释放。
文件泄露
您会发现,随着请求的 session 变多, spark 会在 hdfs 和本地磁盘创建海量的磁盘目录,最终会因为本地磁盘与 hdfs 上的目录过多,而导致文件系统和整个文件系统瘫痪。在 YDB 里面我们针对这种情况也做了处理。
deleteONExit 内存泄露


为什么会有这些对象在里面,我们看下源码


JDO 内存泄露
多达 10 万多个 JDOPersistenceManager





listerner 内存泄漏
通过 debug 工具监控发现,spark 的 listerner 随着时间的积累,通知(post)速度运来越慢发现所有代码都卡在了 onpostevent 上

jstack 的结果如下

研究下了调用逻辑如下,发现是循环调用 listerners,而且 listerner 都是空执行才会产生上面的 jstack 截图

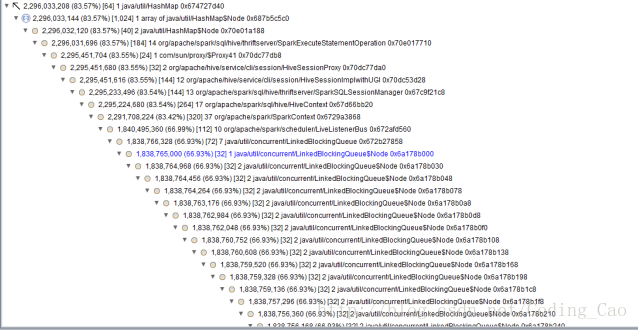
通过内存发现有 30 多万个 linterner 在里面

发现都是大多数都是同一个listener,我们核对下该处源码

最终定位问题
确系是这个地方的 BUG ,每次创建 JDBC 连接的时候 , spark 就会增加一个 listener, 时间久了, listener就会积累越来越多 针对这个问题 我简单的修改了一行代码,开始进入下一轮的压测

spark 源码调优
测试发现,即使只有 1 条记录,使用 spark 进行一次 SQL 查询也会耗时 1 秒,对很多即席查询来说 1秒的等待,对用户体验非常不友好。针对这个问题,我们在 spark 与 hive 的细节代码上进行了局部调优,调优后,响应时间由原先的 1 秒缩减到现在的 200~300 毫秒。以下是我们改动过的地方
1. SessionState 的创建目录 占用较多的时间

另外使用 hadoop namenode HA 的同学会注意到,如果第一个 namenode 是 standby 状态,这个地方会更慢,就不止一秒,所以除了改动源码外,如果使用 namenode ha 的同学一定要注意,将 active 状态的 node 一定要放在前面。
2. HiveConf 的初始化过程占用太多时间
频繁的 hiveConf 初始化,需要读取 core-default.xml, hdfs-default.xml, yarn-default.xml, mapreduce-default.xml, hive-default.xml 等多个xml 文件,而这些xml 文件都是内嵌在 jar 包内的。
第一,解压这些 jar 包需要耗费较多的时间,第二每次都对这些 xml 文件解析也耗费时间。



广播 broadcast 传递的 hadoop configuration 序列化很耗时
configuration 的序列化,采用了压缩的方式进行序列化,有全局锁的问题configuration 每次序列化,传递了太多了没用的配置项了, 1000 多个配置项,占用 60 多 Kb。我们剔除了不是必须传输的配置项后,缩减到 44 个配置项, 2kb 的大小。

对 spark 广播数据 broadcast 的 Cleaner 的改进
由于 SPARK-3015 的 BUG, spark 的 cleaner 目前为单线程回收模式。
大家留意 spark 源码注释

其中的单线程瓶颈点在于广播数据的 cleaner,由于要跨越很多台机器,需要通过 akka 进行网络交互。
如果回收并发特别大, SPARK-3015 的 bug 报告会出现网络拥堵,导致大量的 timeout 出现。
为什么回收量特变大呢? 其实是因为 cleaner 本质是通过 system.gc() ,定期执行的,默认积累 30 分钟或者进行了 gc 后才触发 cleaner,这样就会导致瞬间,大量的 akka 并发执行,集中释放,网络不瞬间瘫痪才不怪呢。
但是单线程回收意味着回收速度恒定,如果查询并发很大,回收速度跟不上 cleaner 的速度,会导致 cleaner 积累很多,会导致进程 OOM( YDB 做了修改,会限制前台查询的并发)。
不论是 OOM 还是限制并发都不是我们希望看到的,所以针对高并发情况下,这种单线程的回收速度是满足不了高并发的需求的。
对于官方的这样的做法,我们表示并不是一个完美的 cleaner 方案。并发回收一定要支持,
只要解决 akka 的 timeout 问题即可。
所以这个问题要仔细分析一下, akka 为什么会 timeout,是因为 cleaner 占据了太多的资源,那么我们是否可以控制下 cleaner 的并发呢?比如说使用 4 个并发,而不是默认将全部的并发线程都给占满呢?这样及解决了 cleaner 的回收速度,也解决了 akka 的问题不是更好么?
针对这个问题,我们最终还是选择了修改 spark 的 ContextCleaner 对象,将广播数据的回收改成多线程的方式,但现在了线程的并发数量,从而解决了该问题。

相关文章推荐
- 基于spark之上的即席分析-spark内存泄漏及源码调优
- 基于spark实现的CRF模型的使用与源码分析
- 基于spark之上的即席分析-卓越性能
- 基于spark之上的即席分析-卓越性能
- Spark MLlib LDA 基于GraphX实现原理及源码分析
- 基于spark之上的即席分析-日志分析场景
- sparkstreaming直连kafka源码分析(基于spark1.6)
- (版本定制)第5课:基于案例分析Spark Streaming流计算框架的运行源码
- 基于spark之上的即席分析-日志分析场景
- Spark资源调度机制源码分析--基于spreadOutApps及非spreadOutApps两种资源调度算法
- TreeMap源码分析——基础分析(基于JDK1.6)
- HashSet及LinkedHashSet源码分析(基于JDK1.6)
- 浅析android锁屏开机绘制流程(基于android4.0源码分析)
- TreeMap源码分析——深入分析(基于JDK1.6)
- 基于mjpg-streamer-r63的源码分析之:基础知识详细解释[二]
- 基于XMPP协议的aSmack源码分析【3】register过程分析
- HashMap源码分析(基于JDK1.6)
- ArrayList源码分析(基于JDK1.6)
- 基于XMPP协议的aSmack源码分析【1】
- 基于mjpg-streamer-r63的源码分析之:基础知识详细解释[二]