数据科学工程师面试宝典系列---数据挖掘算法原理
2017-03-02 18:24
826 查看
1.课程概述
1.1定义
技术定义:数据挖掘(data mining)就是从大量变的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
商业定义:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。
1.2研究对象
数据
—关系型数据库,事务性数据库,面向对象的数据框
—数据仓库,多维数据库
—空间数据
—工程数据
—文本和多媒体数据
—时间相关的数据
—万维网(半结构化的html,结构化的XML)
1.3目的
描述:了解数据中潜在的规律
预测:用历史预测未来
1.4应用领域
解决典型商业问题:
—数据库营销(database marketing)
—客户群体划分(customer segmentation & classification)
—背景分析(profile analysis)
—交叉销售(cross-selling)
—客户流失性分析(credit analysis)
—客户信用记分(credit scoring)
—欺诈侦测(fraud detection)
—...等等
1.5实施步骤
教科书步骤:

实际业务应用的步骤:
情况一:有数据,没想法
数据探索(了解缺失值情况和数据类型...),数据预处理(),明确挖掘任务(),选择技术方案(),结果信息()。
情况二:有想法,没数据
明确挖掘任务(),收集数据(),数据预处理(),选择技术方案(),结果信息()
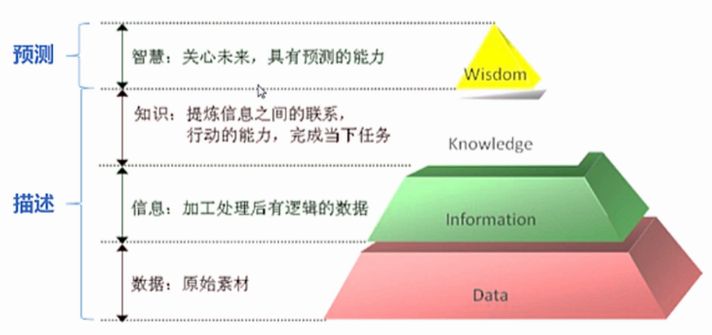
DIKW体系(Data-to-Information-to-Knowledge-to-Wisdom)
1.6技术原理
-关联分析
-分类
-聚类
-异常检测
-...其他
2.数据预处理
数据预处理(data preprocessing):是指在主要的处理以前对数据进行的一些处理。
—数据质量问题:数据太乱,数据质量差,影响后续数据挖掘结果的准确性。
—数据数量问题:数据太多,导致后续数据挖掘过程的开销太大,但未必能较大提高挖掘结果质量;数据太少,某些数据挖掘中需 要的关键属性缺少,影响数据挖掘结果的准确性。
数据质量问题
—数据不完整:缺少某些属性或某些感兴趣的属性。
—数据不正确或含噪声:包含错误或存在偏离期望的值。
—数据不一致:如用于商品分类的部门编码存在差异。
—数据时效性差:如进行近期预测,数据却是一年前的数据。
—数据可信度不高:曾经出现过错误数据,导致新数据可信度差。
—数据不可解释:使用了其他特殊编码,无法知道数据所表达的含义。
数据数量问题
—存储类型太多:存在不同的数据库中,数据结构不同。
—属性太多:数据的变量太多。
—条目太多:数据记录的条数太多。
—分类变量类别多:某个离散性变量类别很多。
—关键属性缺少:数据挖掘过程中所需的关键属性太少。
—数据层次太少:汇总数据较多,导致数据数量较少。
数据预处理技术
—数据清洗:解决数据质量太乱的问题
—数据压缩:解决数据数量太多的问题
—数据构造:解决数据数量太少的问题

2.1数据清理
缺失数据
处理缺失数据的步骤:
—步骤1:识别缺失数据
-NA代表缺失值,不可得到这个数;
-NaN代表不可能的值,不是一个数;
-Inf,-Inf分别代表正无穷和负无穷。
—步骤2:探究缺失数据
-缺失数据的比例
-缺失数据集中程度
-缺失数据的机制:
-完全随机缺失(MCAR):若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失。(简单删除)
-随机缺失(MAR):若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺 失。(建立回归模型进行预测)
-非随机缺失(NMAR):若缺失数据不属于MCAR或MAR,则数据为非随机缺失。(模型选择法和模式混合法)
—步骤3:处理缺失数据
-删除法:观测样本删除,变量删除,完全变量分析,无回答权重。
-填补法:单变量填补(简单随机填补,均值填补,回归填补,热平台和冷平台,随机回归填补法等),多变量填补(多 重填补法等)。
噪声数据
噪声数据(noisy data)定义:无意义的数据(meaningless data)。
噪声数据产生的原因:硬件故障、编程错误或者语音或光学字符识别程序中的乱码;拼写错误、行业简称和俚语也会阻碍机器读取。
噪声数据处理原则:不是所有的噪声数据都要处理掉,必须事先判断出这些离群的点是否会阻碍后面的数据挖掘任务,部分情况下噪声数据是需要保留的重要信息。
噪声数据处理方法:分箱、回归、聚类等。

不一致数据
不一致数据:编码使用的不一致,数据表示的不一致。
不一致数据处理方法:通常需要人工检测,当发现一定规律时可以通过编程进行替换和修改;若存在不一致的数据是无意义数据,可以使用缺失值处理方法进行相应处理。
2.2数据压缩
数据集成
—对象匹配:注意数据结构,确保源系统中的函数依赖和参照约束与目标系统中的匹配。
—属性冗余:通过相关分析判断属性间的依赖关系,标称数据使用X2检验,数值型属性数据使用相关系数和协方差。
—元组重复:进行元组级重复检测。
—数据值冲突:使用一系列的数据变换来统一或纠正数据。
数据归约
—维规约:减少所要考虑得随机变量或属性个数,如特征子集选择,主成分分析,傅里叶变换等。
(1)特征子集的选择
—嵌入方法:特征选择作为数据挖掘算法的一部分。(构造决策树分类器)
—过滤方法:使用某种独立于数据挖掘任务的方法,在数据挖掘算法运行前进行特征选择。
—包装方法:将目标数据挖掘算法作为黑盒子,但不枚举所有可能的子集来找出最佳属性子集。

贪心算法:由局部最优解逼近全局的最优解;
(2)主成分分析(线性变换:A B C D --> AB CD)【降维】

主成分就是原始数据的加权组合;
(3)傅里叶变换/小波变换(映射到新空间:A B C D ---> E F)【降维】

功率频谱正比于每一个频率属性的平方;
(4)属性构造
—原始数据属性具有必要信息,但其形式不适合数据挖掘算法;
—简单数学组合构造,专家意见构造;

—数量规约:用代替的、较小的数据表示形式替换原数据,如聚类,抽样等方法。
(1)直方图(一维的汇聚)

(2)聚集(多维的汇聚)

(3)抽样

数据变换
离散化:离散型变量,连续型变量

规范化:


2.3数据构造
属性添加

二元化

变换后所有的分类值都是不相关的;
概念分层

—有用户或专家进行属性分类排序;
—通过显示数据来定义分层结构的一部分;
—定义属性集但不定义它们的排序;
—只定义部分属性集;

3.关联分析算法
3.1基本概念
关联分析(association analysis):在大规模数据集中寻找有趣关系。
—频繁项集(frequent item sets):是经常出现在一块儿的物品的集合。
—关联规则(association rules):暗示两种物品之间可能存在很强的关系。
支持度(support):数据集中包含该项集的记录所占的比例,是针对项集来说的。
置信度(confidence):出现某些物品时,另外一些物品必定出现的概率,针对规则而言。



3.2Apriori算法(基于布尔关联规则的算法)


3.3FP-growth算法(基于频繁模式增长的算法)
3.4ECLAT算法(基于使用垂直数据格式挖掘频繁模式)
3.5其他算法
4.分类算法
4.1基本概念
4.2ID3算法
4.3Navie Bayes算法
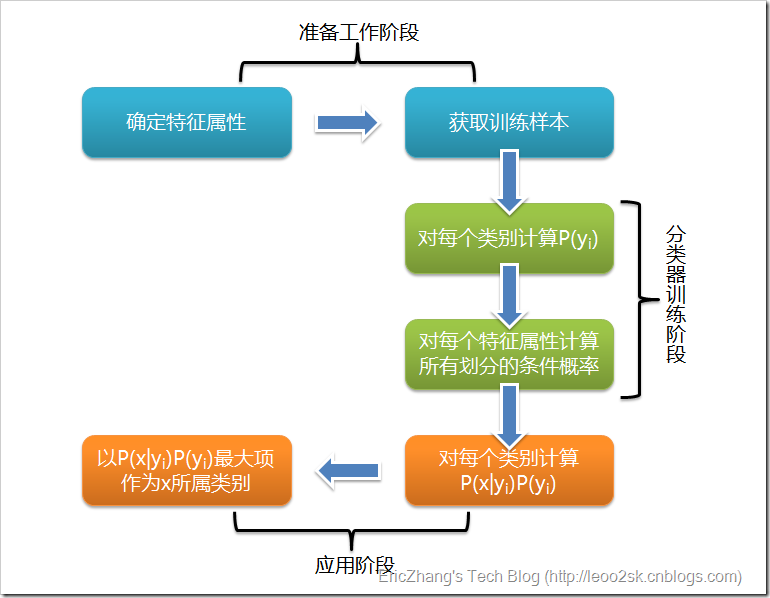
4.4KNN算法

简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
4.5其他算法
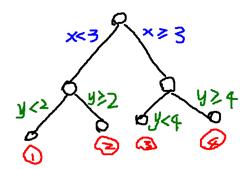
决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树:
就是将空间划分成下面的样子:
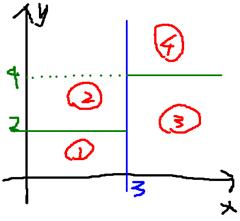
这样使得每一个叶子节点都是在空间中的一个不相交的区域,在进行决策的时候,会根据输入样本每一维feature的值,一步一步往下,最后使得样本落入N个区域中的一个(假设有N个叶子节点)
随机森林(Random Forest):
随机森林是一个最近比较火的算法,它有很多的优点:
在数据集上表现良好
在当前的很多数据集上,相对其他算法有着很大的优势
它能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,它能够给出哪些feature比较重要
ce0b
在创建随机森林的时候,对generlization error使用的是无偏估计
训练速度快
在训练过程中,能够检测到feature间的互相影响
容易做成并行化方法
实现比较简单
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
在建立每一棵决策树的过程中,有两点需要注意 - 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤
- 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
5.聚类算法
5.1基本概念
5.2K-Means算法


从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
随机在图中取K(这里K=2)个种子点。
然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”。
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance公式——也就是第一个公式λ=2的情况

3)CityBlock Distance公式——也就是第一个公式λ=1的情况

这三个公式的求中心点有一些不一样的地方,我们看下图(对于第一个λ在0-1之间)。



(1)Minkowski Distance (2)[b]Euclidean Distance (3) [b]CityBlock Distance[/b][/b]
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
5.3AGNES算法
5.4DBSCAN算法
5.5其他算法
6.异常点检测算法
6.1基本概念
6.2BPrule算法
6.3Cell-Based算法
6.4其他算法
1.1定义
技术定义:数据挖掘(data mining)就是从大量变的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
商业定义:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。
1.2研究对象
数据
—关系型数据库,事务性数据库,面向对象的数据框
—数据仓库,多维数据库
—空间数据
—工程数据
—文本和多媒体数据
—时间相关的数据
—万维网(半结构化的html,结构化的XML)
1.3目的
描述:了解数据中潜在的规律
预测:用历史预测未来
1.4应用领域
解决典型商业问题:
—数据库营销(database marketing)
—客户群体划分(customer segmentation & classification)
—背景分析(profile analysis)
—交叉销售(cross-selling)
—客户流失性分析(credit analysis)
—客户信用记分(credit scoring)
—欺诈侦测(fraud detection)
—...等等
1.5实施步骤
教科书步骤:
实际业务应用的步骤:
情况一:有数据,没想法
数据探索(了解缺失值情况和数据类型...),数据预处理(),明确挖掘任务(),选择技术方案(),结果信息()。
情况二:有想法,没数据
明确挖掘任务(),收集数据(),数据预处理(),选择技术方案(),结果信息()
DIKW体系(Data-to-Information-to-Knowledge-to-Wisdom)
1.6技术原理
-关联分析
-分类
-聚类
-异常检测
-...其他
2.数据预处理
数据预处理(data preprocessing):是指在主要的处理以前对数据进行的一些处理。
—数据质量问题:数据太乱,数据质量差,影响后续数据挖掘结果的准确性。
—数据数量问题:数据太多,导致后续数据挖掘过程的开销太大,但未必能较大提高挖掘结果质量;数据太少,某些数据挖掘中需 要的关键属性缺少,影响数据挖掘结果的准确性。
数据质量问题
—数据不完整:缺少某些属性或某些感兴趣的属性。
—数据不正确或含噪声:包含错误或存在偏离期望的值。
—数据不一致:如用于商品分类的部门编码存在差异。
—数据时效性差:如进行近期预测,数据却是一年前的数据。
—数据可信度不高:曾经出现过错误数据,导致新数据可信度差。
—数据不可解释:使用了其他特殊编码,无法知道数据所表达的含义。
数据数量问题
—存储类型太多:存在不同的数据库中,数据结构不同。
—属性太多:数据的变量太多。
—条目太多:数据记录的条数太多。
—分类变量类别多:某个离散性变量类别很多。
—关键属性缺少:数据挖掘过程中所需的关键属性太少。
—数据层次太少:汇总数据较多,导致数据数量较少。
数据预处理技术
—数据清洗:解决数据质量太乱的问题
—数据压缩:解决数据数量太多的问题
—数据构造:解决数据数量太少的问题
2.1数据清理
缺失数据
处理缺失数据的步骤:
—步骤1:识别缺失数据
-NA代表缺失值,不可得到这个数;
-NaN代表不可能的值,不是一个数;
-Inf,-Inf分别代表正无穷和负无穷。
—步骤2:探究缺失数据
-缺失数据的比例
-缺失数据集中程度
-缺失数据的机制:
-完全随机缺失(MCAR):若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失。(简单删除)
-随机缺失(MAR):若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺 失。(建立回归模型进行预测)
-非随机缺失(NMAR):若缺失数据不属于MCAR或MAR,则数据为非随机缺失。(模型选择法和模式混合法)
—步骤3:处理缺失数据
-删除法:观测样本删除,变量删除,完全变量分析,无回答权重。
-填补法:单变量填补(简单随机填补,均值填补,回归填补,热平台和冷平台,随机回归填补法等),多变量填补(多 重填补法等)。
噪声数据
噪声数据(noisy data)定义:无意义的数据(meaningless data)。
噪声数据产生的原因:硬件故障、编程错误或者语音或光学字符识别程序中的乱码;拼写错误、行业简称和俚语也会阻碍机器读取。
噪声数据处理原则:不是所有的噪声数据都要处理掉,必须事先判断出这些离群的点是否会阻碍后面的数据挖掘任务,部分情况下噪声数据是需要保留的重要信息。
噪声数据处理方法:分箱、回归、聚类等。
不一致数据
不一致数据:编码使用的不一致,数据表示的不一致。
不一致数据处理方法:通常需要人工检测,当发现一定规律时可以通过编程进行替换和修改;若存在不一致的数据是无意义数据,可以使用缺失值处理方法进行相应处理。
2.2数据压缩
数据集成
—对象匹配:注意数据结构,确保源系统中的函数依赖和参照约束与目标系统中的匹配。
—属性冗余:通过相关分析判断属性间的依赖关系,标称数据使用X2检验,数值型属性数据使用相关系数和协方差。
—元组重复:进行元组级重复检测。
—数据值冲突:使用一系列的数据变换来统一或纠正数据。
数据归约
—维规约:减少所要考虑得随机变量或属性个数,如特征子集选择,主成分分析,傅里叶变换等。
(1)特征子集的选择
—嵌入方法:特征选择作为数据挖掘算法的一部分。(构造决策树分类器)
—过滤方法:使用某种独立于数据挖掘任务的方法,在数据挖掘算法运行前进行特征选择。
—包装方法:将目标数据挖掘算法作为黑盒子,但不枚举所有可能的子集来找出最佳属性子集。
贪心算法:由局部最优解逼近全局的最优解;
(2)主成分分析(线性变换:A B C D --> AB CD)【降维】
主成分就是原始数据的加权组合;
(3)傅里叶变换/小波变换(映射到新空间:A B C D ---> E F)【降维】
功率频谱正比于每一个频率属性的平方;
(4)属性构造
—原始数据属性具有必要信息,但其形式不适合数据挖掘算法;
—简单数学组合构造,专家意见构造;
—数量规约:用代替的、较小的数据表示形式替换原数据,如聚类,抽样等方法。
(1)直方图(一维的汇聚)
(2)聚集(多维的汇聚)
(3)抽样
数据变换
离散化:离散型变量,连续型变量
规范化:
2.3数据构造
属性添加
二元化
变换后所有的分类值都是不相关的;
概念分层
—有用户或专家进行属性分类排序;
—通过显示数据来定义分层结构的一部分;
—定义属性集但不定义它们的排序;
—只定义部分属性集;
3.关联分析算法
3.1基本概念
关联分析(association analysis):在大规模数据集中寻找有趣关系。
—频繁项集(frequent item sets):是经常出现在一块儿的物品的集合。
—关联规则(association rules):暗示两种物品之间可能存在很强的关系。
支持度(support):数据集中包含该项集的记录所占的比例,是针对项集来说的。
置信度(confidence):出现某些物品时,另外一些物品必定出现的概率,针对规则而言。
3.2Apriori算法(基于布尔关联规则的算法)
3.3FP-growth算法(基于频繁模式增长的算法)
3.4ECLAT算法(基于使用垂直数据格式挖掘频繁模式)
3.5其他算法
4.分类算法
4.1基本概念
4.2ID3算法
4.3Navie Bayes算法
4.4KNN算法
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
4.5其他算法
决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树:

就是将空间划分成下面的样子:

这样使得每一个叶子节点都是在空间中的一个不相交的区域,在进行决策的时候,会根据输入样本每一维feature的值,一步一步往下,最后使得样本落入N个区域中的一个(假设有N个叶子节点)
随机森林(Random Forest):
随机森林是一个最近比较火的算法,它有很多的优点:
在数据集上表现良好
在当前的很多数据集上,相对其他算法有着很大的优势
它能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,它能够给出哪些feature比较重要
ce0b
在创建随机森林的时候,对generlization error使用的是无偏估计
训练速度快
在训练过程中,能够检测到feature间的互相影响
容易做成并行化方法
实现比较简单
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
在建立每一棵决策树的过程中,有两点需要注意 - 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤
- 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
5.聚类算法
5.1基本概念
5.2K-Means算法
从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
随机在图中取K(这里K=2)个种子点。
然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”。
求点群中心的算法
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:1)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。
2)Euclidean Distance公式——也就是第一个公式λ=2的情况
3)CityBlock Distance公式——也就是第一个公式λ=1的情况
这三个公式的求中心点有一些不一样的地方,我们看下图(对于第一个λ在0-1之间)。
(1)Minkowski Distance (2)[b]Euclidean Distance (3) [b]CityBlock Distance[/b][/b]
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
5.3AGNES算法
5.4DBSCAN算法
5.5其他算法
6.异常点检测算法
6.1基本概念
6.2BPrule算法
6.3Cell-Based算法
6.4其他算法

相关文章推荐
- 数据科学工程师面试宝典系列---旅游评论数据中的自然语言处理
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据科学工程师面试宝典系列之四---MySQL基础
- 数据科学工程师面试宝典系列之一--Python爬虫实战
- 数据科学工程师面试宝典系列之二---Python机器学习kaggle案例:泰坦尼克号船员获救预测
- 数据挖掘系列-朴素贝叶斯分类算法原理与实践
- 数据科学工程师面试宝典系列---R语言入门
- 数据科学工程师面试宝典系列之一--Python爬虫实战
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据科学工程师面试宝典系列之一----Python爬虫
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 全文检索、数据挖掘、推荐引擎系列7---条目相似度算法
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大系列集锦
- 转载某博主整理的资料:程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大经典原创系列集锦与总结