RCNN系列学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentation
2017-02-26 16:22
411 查看
基于R-CNN的目标检测
原文地址:http://blog.csdn.net/u011534057/article/details/51218250
一、相关理论
本篇博文主要讲解2014年CVPR上的经典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》,这篇文章的算法思想又被称之为:R-CNN(Regions
with Convolutional Neural Network Features),是物体检测领域曾经获得state-of-art精度的经典文献。
这篇paper的思想,改变了物体检测的总思路,现在好多文献关于深度学习的物体检测的算法,基本上都是继承了这个思想,比如:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,所以学习经典算法,有助于我们以后搞物体检测的其它paper。
之前刚开始接触物体检测算法的时候,老是分不清deep learning中,物体检测和图片分类算法上的区别,弄得我头好晕,终于在这篇paper上,看到了解释。物体检测和图片分类的区别:图片分类不需要定位,而物体检测需要定位出物体的位置,也就是相当于把物体的bbox检测出来,还有一点物体检测是要把所有图片中的物体都识别定位出来。
(笔记后感by ym:
个人理解testing整个流程即:先将region通过ss检测出来(2k+),然后根据cnn提取的region特征丢入svm进行分类(compute score),得到
13cf7
的就是一个region-bbox以及对应的类别,再利用(IoU->nms)得到具体的框,目的防止泛滥,为了精确bbox,再根据pool5 feature做了个bbox regression来decrease
location error,training的trick则为hnm+finetuning)
——————————————————————————————————————————————————————————————————
Selective Search
因为研究RCNN的需要,在这里看一下Selective Search的操作流程
原文链接:http://koen.me/research/pub/uijlings-ijcv2013-draft.pdf
选择性搜索遵循如下的原则:
图片中目标的尺寸不一,边缘清晰程度也不一样,选择性搜索应该能够将所有的情况都考虑进去,如下图,最好的办法就是使用分层算法来实现
区域合并的算法应该多元化。初始的小的图像区域(Graph-Based Image Segmentation得到)可能是根据颜色、纹理、部分封闭等原因得到的,一个单一的策略很难能适应所有的情况将小区域合并在一起,因此需要有一个多元化的策略集,能够在不同场合都有效。
能够快速计算。
——————————————————————————————————————————————————————————————————
二、基础知识
1、有监督预训练与无监督预训练
(1)无监督预训练(Unsupervised pre-training)
无监督预训练这个名词我们比较熟悉,栈式自编码、DBM采用的都是采用无监督预训练。因为预训练阶段的样本不需要人工标注数据,所以就叫做无监督预训练。
(2)有监督预训练(Supervised pre-training)
所谓的有监督预训练,我们也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇paper采用了迁移学习的思想。文献就先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络的图片分类训练。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段cnn模型的输出是1000个神经元,或者我们也直接可以采用Alexnet训练好的模型参数。
2、IOU的定义
因为没有搞过物体检测不懂IOU这个概念,所以就简单介绍一下。物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。

IOU定义了两个bounding box的重叠度,如下图所示:
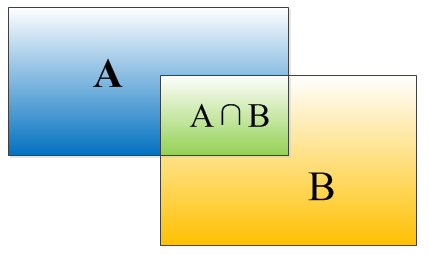
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
3、非极大值抑制
因为一会儿讲RCNN算法,会从一张图片中找出n多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)非极大值抑制顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
——————————————————————————————————————————————————————————————————
canny detection(canny NMS):
图像梯度幅值矩阵中的元素值越大,说明图像中该点的梯度值越大,但这不不能说明该点就是边缘(这仅仅是属于图像增强的过程)。在Canny算法中,非极大值抑制是进行边缘检测的重要步骤,通俗意义上是指寻找像素点局部最大值,将非极大值点所对应的灰度值置为0,这样可以剔除掉一大部分非边缘的点(这是本人的理解)。
图1 非极大值抑制原理
根据图1 可知,要进行非极大值抑制,就首先要确定像素点C的灰度值在其8值邻域内是否为最大。图1中蓝色的线条方向为C点的梯度方向,这样就可以确定其局部的最大值肯定分布在这条线上,也即出了C点外,梯度方向的交点dTmp1和dTmp2这两个点的值也可能会是局部最大值。因此,判断C点灰度与这两个点灰度大小即可判断C点是否为其邻域内的局部最大灰度点。如果经过判断,C点灰度值小于这两个点中的任一个,那就说明C点不是局部极大值,那么则可以排除C点为边缘。这就是非极大值抑制的工作原理。
作者认为,在理解的过程中需要注意以下两点:
1)中非最大抑制是回答这样一个问题:“当前的梯度值在梯度方向上是一个局部最大值吗?”
所以,要把当前位置的梯度值与梯度方向上两侧的梯度值进行比较;
2)梯度方向垂直于边缘方向。
但实际上,我们只能得到C点邻域的8个点的值,而dTmp1和dTmp2并不在其中,要得到这两个值就需要对该两个点两端的已知灰度进行线性插值,也即根据图1中的g1和g2对dTmp1进行插值,根据g3和g4对dTmp2进行插值,这要用到其梯度方向,这是上文Canny算法中要求解梯度方向矩阵Thita的原因。
完成非极大值抑制后,会得到一个二值图像,非边缘的点灰度值均为0,可能为边缘的局部灰度极大值点可设置其灰度为128。根据下文的具体测试图像可以看出,这样一个检测结果还是包含了很多由噪声及其他原因造成的假边缘。因此还需要进一步的处理。
——————————————————————————————————————————————————————————————————
4、VOC物体检测任务
这个就相当于一个竞赛,里面包含了20个物体类别:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/examples/index.html
还有一个背景,总共就相当于21个类别,因此一会设计fine-tuning CNN的时候,我们softmax分类输出层为21个神经元。
三、算法总体思路
开始讲解paper前,我们需要先把握总体思路,才容易理解paper的算法。
(作者通过在recongnition using regions操作的方法来解决CNN的定位问题,这个方法在目标检测和语义分割中都取得了成功。测试阶段,这个方法对每一个输入的图片产生近2000个不分种类的“region proposals,使用CNNs从每个region proposals”中提取一个固定长度的特征向量,然后对每个region
proposal(SS for Detction)提取的特征向量使用特定种类的线性SVM进行分类(CNN+SVM for classification)。)
图片分类与物体检测不同,物体检测需要定位出物体的位置,这种就相当于回归问题,求解一个包含物体的方框。而图片分类其实是逻辑回归。这种方法对于单物体检测还不错,但是对于多物体检测就……
因此paper采用的方法是:首先输入一张图片,我们先定位出2000个物体候选框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,接着采用svm算法对各个候选框中的物体进行分类识别。也就是总个过程分为三个程序:a、找出候选框;b、利用CNN提取特征向量;c、利用SVM进行特征向量分类。具体的流程如下图片所示:
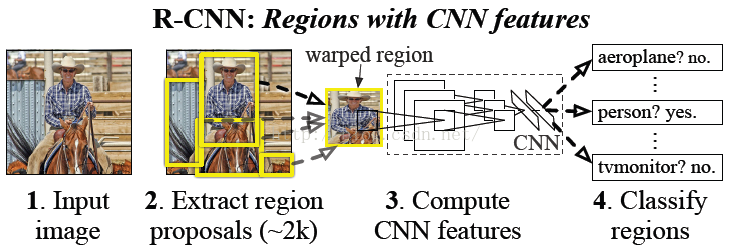
后面我们将根据这三个过程,进行每个步骤的详细讲解。
四、候选框搜索阶段
(作者也考虑过使用一个滑动窗口的方法,然而由于更深的网络,更大的输入图片和滑动步长,使得使用滑动窗口来定位的方法充满了挑战)
1、实现方式
当我们输入一张图片时,我们要搜索出所有可能是物体的区域,这个采用的方法是传统文献的算法:《search for object recognition》,通过这个算法我们搜索出2000个候选框。然后从上面的总流程图中可以看到,搜出的候选框是矩形的,而且是大小各不相同。然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。下面我们讲解要怎么进行缩放处理,为了简单起见我们假设下一阶段CNN所需要的输入图片大小是个正方形图片227*227。因为我们经过selective
search 得到的是矩形框,paper试验了两种不同的处理方法:
(1)各向异性缩放
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227,如下图(D)所示;
(2)各向同性缩放
因为图片扭曲后,估计会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法
A、直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如下图(B)所示;
B、先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示;

对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高,具体不再啰嗦。
OK,上面处理完后,可以得到指定大小的图片,因为我们后面还要继续用这2000个候选框图片,继续训练CNN、SVM。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。
因此我们需要用IOU为2000个bounding box打标签,以便下一步CNN训练使用。在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则我们就把它当做背景类别。SVM阶段的正负样本标签问题,等到了svm讲解阶段我再具体讲解。
五、CNN特征提取阶段
1、算法实现
a、网络结构设计阶段
网络架构我们有两个可选方案:第一选择经典的Alexnet;第二选择VGG16。经过测试Alexnet精度为58.5%,VGG16精度为66%。VGG这个模型的特点是选择比较小的卷积核、选择较小的跨步,这个网络的精度高,不过计算量是Alexnet的7倍。后面为了简单起见,我们就直接选用Alexnet,并进行讲解;Alexnet特征提取部分包含了5个卷积层、2个全连接层,在Alexnet中p5层神经元个数为9216、 f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量。
b、网络有监督预训练阶段
参数初始化部分:物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这边文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。
网络优化求解:采用随机梯度下降法,学习速率大小为0.001;
C、fine-tuning阶段
我们接着采用selective search 搜索出来的候选框,然后处理到指定大小图片,继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个事正样本、96个事负样本(正负样本的定义前面已经提过,不再解释)。
2、问题解答
OK,看完上面的CNN过程后,我们会有一些细节方面的疑问。首先,反正CNN都是用于提取特征,那么我直接用Alexnet做特征提取,省去fine-tuning阶段可以吗?这个是可以的,你可以不需重新训练CNN,直接采用Alexnet模型,提取出p5、或者f6、f7的特征,作为特征向量,然后进行训练svm,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择p5、f6、f7,这三层的神经元个数分别是9216、4096、4096。从p5到p6这层的参数个数是:4096*9216 ,从f6到f7的参数是4096*4096。那么具体是选择p5、还是f6,又或者是f7呢?
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。
打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
还有另外一个疑问:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,是一个端到端的任务,在训练的时候最后一层softmax就是分类层.
那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding
box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm,具体请看下文。
六、SVM训练、测试阶段
这是一个二分类问题,我么假设我们要检测车辆。我们知道只有当bounding box把整量车都包含在内,那才叫正样本;如果bounding box 没有包含到车辆,那么我们就可以把它当做负样本。但问题是当我们的检测窗口只有部分包好物体,那该怎么定义正负样本呢?作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后我们通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。一旦CNN
f7层特征被提取出来,那么我们将为每个物体累训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000*4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096*N点(Therefore,the pool5 need to be set as)乘(N为分类类别数目,因为我们训练的N个svm,每个svm包好了4096个W),就可以得到结果了。
参考文献:
1、《Rich feature hierarchies for Accurate Object Detection and Segmentation》
2、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
原文地址:http://blog.csdn.net/u011534057/article/details/51218250
一、相关理论
本篇博文主要讲解2014年CVPR上的经典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》,这篇文章的算法思想又被称之为:R-CNN(Regions
with Convolutional Neural Network Features),是物体检测领域曾经获得state-of-art精度的经典文献。
这篇paper的思想,改变了物体检测的总思路,现在好多文献关于深度学习的物体检测的算法,基本上都是继承了这个思想,比如:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,所以学习经典算法,有助于我们以后搞物体检测的其它paper。
之前刚开始接触物体检测算法的时候,老是分不清deep learning中,物体检测和图片分类算法上的区别,弄得我头好晕,终于在这篇paper上,看到了解释。物体检测和图片分类的区别:图片分类不需要定位,而物体检测需要定位出物体的位置,也就是相当于把物体的bbox检测出来,还有一点物体检测是要把所有图片中的物体都识别定位出来。
(笔记后感by ym:
个人理解testing整个流程即:先将region通过ss检测出来(2k+),然后根据cnn提取的region特征丢入svm进行分类(compute score),得到
13cf7
的就是一个region-bbox以及对应的类别,再利用(IoU->nms)得到具体的框,目的防止泛滥,为了精确bbox,再根据pool5 feature做了个bbox regression来decrease
location error,training的trick则为hnm+finetuning)
Selective Search
因为研究RCNN的需要,在这里看一下Selective Search的操作流程
原文链接:http://koen.me/research/pub/uijlings-ijcv2013-draft.pdf
选择性搜索遵循如下的原则:
图片中目标的尺寸不一,边缘清晰程度也不一样,选择性搜索应该能够将所有的情况都考虑进去,如下图,最好的办法就是使用分层算法来实现
区域合并的算法应该多元化。初始的小的图像区域(Graph-Based Image Segmentation得到)可能是根据颜色、纹理、部分封闭等原因得到的,一个单一的策略很难能适应所有的情况将小区域合并在一起,因此需要有一个多元化的策略集,能够在不同场合都有效。
能够快速计算。
——————————————————————————————————————————————————————————————————
二、基础知识
1、有监督预训练与无监督预训练
(1)无监督预训练(Unsupervised pre-training)
无监督预训练这个名词我们比较熟悉,栈式自编码、DBM采用的都是采用无监督预训练。因为预训练阶段的样本不需要人工标注数据,所以就叫做无监督预训练。
(2)有监督预训练(Supervised pre-training)
所谓的有监督预训练,我们也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇paper采用了迁移学习的思想。文献就先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络的图片分类训练。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段cnn模型的输出是1000个神经元,或者我们也直接可以采用Alexnet训练好的模型参数。
2、IOU的定义
因为没有搞过物体检测不懂IOU这个概念,所以就简单介绍一下。物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
IOU定义了两个bounding box的重叠度,如下图所示:
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
3、非极大值抑制
因为一会儿讲RCNN算法,会从一张图片中找出n多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:
就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)非极大值抑制顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
——————————————————————————————————————————————————————————————————
canny detection(canny NMS):
对梯度幅值进行非极大值抑制
图像梯度幅值矩阵中的元素值越大,说明图像中该点的梯度值越大,但这不不能说明该点就是边缘(这仅仅是属于图像增强的过程)。在Canny算法中,非极大值抑制是进行边缘检测的重要步骤,通俗意义上是指寻找像素点局部最大值,将非极大值点所对应的灰度值置为0,这样可以剔除掉一大部分非边缘的点(这是本人的理解)。
图1 非极大值抑制原理
根据图1 可知,要进行非极大值抑制,就首先要确定像素点C的灰度值在其8值邻域内是否为最大。图1中蓝色的线条方向为C点的梯度方向,这样就可以确定其局部的最大值肯定分布在这条线上,也即出了C点外,梯度方向的交点dTmp1和dTmp2这两个点的值也可能会是局部最大值。因此,判断C点灰度与这两个点灰度大小即可判断C点是否为其邻域内的局部最大灰度点。如果经过判断,C点灰度值小于这两个点中的任一个,那就说明C点不是局部极大值,那么则可以排除C点为边缘。这就是非极大值抑制的工作原理。
作者认为,在理解的过程中需要注意以下两点:
1)中非最大抑制是回答这样一个问题:“当前的梯度值在梯度方向上是一个局部最大值吗?”
所以,要把当前位置的梯度值与梯度方向上两侧的梯度值进行比较;
2)梯度方向垂直于边缘方向。
但实际上,我们只能得到C点邻域的8个点的值,而dTmp1和dTmp2并不在其中,要得到这两个值就需要对该两个点两端的已知灰度进行线性插值,也即根据图1中的g1和g2对dTmp1进行插值,根据g3和g4对dTmp2进行插值,这要用到其梯度方向,这是上文Canny算法中要求解梯度方向矩阵Thita的原因。
完成非极大值抑制后,会得到一个二值图像,非边缘的点灰度值均为0,可能为边缘的局部灰度极大值点可设置其灰度为128。根据下文的具体测试图像可以看出,这样一个检测结果还是包含了很多由噪声及其他原因造成的假边缘。因此还需要进一步的处理。
——————————————————————————————————————————————————————————————————
4、VOC物体检测任务
这个就相当于一个竞赛,里面包含了20个物体类别:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/examples/index.html
还有一个背景,总共就相当于21个类别,因此一会设计fine-tuning CNN的时候,我们softmax分类输出层为21个神经元。
三、算法总体思路
开始讲解paper前,我们需要先把握总体思路,才容易理解paper的算法。
(作者通过在recongnition using regions操作的方法来解决CNN的定位问题,这个方法在目标检测和语义分割中都取得了成功。测试阶段,这个方法对每一个输入的图片产生近2000个不分种类的“region proposals,使用CNNs从每个region proposals”中提取一个固定长度的特征向量,然后对每个region
proposal(SS for Detction)提取的特征向量使用特定种类的线性SVM进行分类(CNN+SVM for classification)。)
图片分类与物体检测不同,物体检测需要定位出物体的位置,这种就相当于回归问题,求解一个包含物体的方框。而图片分类其实是逻辑回归。这种方法对于单物体检测还不错,但是对于多物体检测就……
因此paper采用的方法是:首先输入一张图片,我们先定位出2000个物体候选框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,接着采用svm算法对各个候选框中的物体进行分类识别。也就是总个过程分为三个程序:a、找出候选框;b、利用CNN提取特征向量;c、利用SVM进行特征向量分类。具体的流程如下图片所示:
后面我们将根据这三个过程,进行每个步骤的详细讲解。
四、候选框搜索阶段
(作者也考虑过使用一个滑动窗口的方法,然而由于更深的网络,更大的输入图片和滑动步长,使得使用滑动窗口来定位的方法充满了挑战)
1、实现方式
当我们输入一张图片时,我们要搜索出所有可能是物体的区域,这个采用的方法是传统文献的算法:《search for object recognition》,通过这个算法我们搜索出2000个候选框。然后从上面的总流程图中可以看到,搜出的候选框是矩形的,而且是大小各不相同。然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。下面我们讲解要怎么进行缩放处理,为了简单起见我们假设下一阶段CNN所需要的输入图片大小是个正方形图片227*227。因为我们经过selective
search 得到的是矩形框,paper试验了两种不同的处理方法:
(1)各向异性缩放
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227,如下图(D)所示;
(2)各向同性缩放
因为图片扭曲后,估计会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法
A、直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如下图(B)所示;
B、先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示;
对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高,具体不再啰嗦。
OK,上面处理完后,可以得到指定大小的图片,因为我们后面还要继续用这2000个候选框图片,继续训练CNN、SVM。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。
因此我们需要用IOU为2000个bounding box打标签,以便下一步CNN训练使用。在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则我们就把它当做背景类别。SVM阶段的正负样本标签问题,等到了svm讲解阶段我再具体讲解。
五、CNN特征提取阶段
1、算法实现
a、网络结构设计阶段
网络架构我们有两个可选方案:第一选择经典的Alexnet;第二选择VGG16。经过测试Alexnet精度为58.5%,VGG16精度为66%。VGG这个模型的特点是选择比较小的卷积核、选择较小的跨步,这个网络的精度高,不过计算量是Alexnet的7倍。后面为了简单起见,我们就直接选用Alexnet,并进行讲解;Alexnet特征提取部分包含了5个卷积层、2个全连接层,在Alexnet中p5层神经元个数为9216、 f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量。
b、网络有监督预训练阶段
参数初始化部分:物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这边文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。
网络优化求解:采用随机梯度下降法,学习速率大小为0.001;
C、fine-tuning阶段
我们接着采用selective search 搜索出来的候选框,然后处理到指定大小图片,继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个事正样本、96个事负样本(正负样本的定义前面已经提过,不再解释)。
2、问题解答
OK,看完上面的CNN过程后,我们会有一些细节方面的疑问。首先,反正CNN都是用于提取特征,那么我直接用Alexnet做特征提取,省去fine-tuning阶段可以吗?这个是可以的,你可以不需重新训练CNN,直接采用Alexnet模型,提取出p5、或者f6、f7的特征,作为特征向量,然后进行训练svm,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择p5、f6、f7,这三层的神经元个数分别是9216、4096、4096。从p5到p6这层的参数个数是:4096*9216 ,从f6到f7的参数是4096*4096。那么具体是选择p5、还是f6,又或者是f7呢?
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。
打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
还有另外一个疑问:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,是一个端到端的任务,在训练的时候最后一层softmax就是分类层.
那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding
box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm,具体请看下文。
六、SVM训练、测试阶段
这是一个二分类问题,我么假设我们要检测车辆。我们知道只有当bounding box把整量车都包含在内,那才叫正样本;如果bounding box 没有包含到车辆,那么我们就可以把它当做负样本。但问题是当我们的检测窗口只有部分包好物体,那该怎么定义正负样本呢?作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后我们通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。一旦CNN
f7层特征被提取出来,那么我们将为每个物体累训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000*4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096*N点(Therefore,the pool5 need to be set as)乘(N为分类类别数目,因为我们训练的N个svm,每个svm包好了4096个W),就可以得到结果了。
参考文献:
1、《Rich feature hierarchies for Accurate Object Detection and Segmentation》
2、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》

相关文章推荐
- rcnn学习笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- 【转】R-CNN学习笔记2:Rich feature hierarchies for accurate object detection and semantic segmentation
- RCNN系列笔记整理(1):Rich feature hierarchies for accurate object detection and semantic segment
- 深度学习论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- R-CNN学习笔记2:Rich feature hierarchies for accurate object detection and semantic segmentation
- [深度学习论文笔记][Object Detection] Rich feature hierarchies for accurate object detection and semantic seg
- Rich feature hierarchies for accurate object detection and semantic segmentation论文笔记
- 论文笔记——Rich feature hierarchies for accurate object detection and semantic segmentation
- 【论文笔记】Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation 笔记
- RCNN(一):Rich feature hierarchies for accurate object detection and semantic segmentation
- 2014-RCNN-Rich feature hierarchies for accurate object detection and semantic segmentation 翻译
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- Rich feature hierarchies for accurate object detection and semantic segmentation(RCNN)
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- 《Rich feature hierarchies for accurate object detection and semantic segmentation》笔记
- 论文笔记|Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文阅读笔记:R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich featureHierarchies for accurate object detection and semantic segmentation 阅读笔记