Rich featureHierarchies for accurate object detection and semantic segmentation 阅读笔记
2016-11-29 10:02
639 查看
2016-11-22
在物体检测领域中,之前很多的任务都是基于SIFT和HOG的。比较好的方法也是基于复杂的集成系统的,而作者提出一个简单而且可扩展的检测算法,这种算法提高了平均物体检测度(mAP:mean average precision ),
两点贡献:
(1)将CNN用在从底至上的region propasals上,从而进行物体定位和分割(one can apply high-capacity convolutional neural net-works (CNNs) tobottom-up region proposals in order tolocalize and segment objects)
(2)通过使用有监督预训练加上相关的finetune,解决物体识别标签数据有限的问题,提高性能
该方法把region proposals与CNNs结合,称之为R-CNN方法,Regions with CNN features。
Fukushima的神经认知机一个模式识别中受生物启发的分层结构和迁移不变模型,是早期在那样一个阶段的尝试。但是,这个神经认知机缺乏监督训练算法。建立在Rumelhart等人和 LeCun等人基础上的通过反向传播的随机梯度下降法是一种有效的训练卷积神经网络(一类神经认知机扩展的模型)的方法。
CNNs在90年代的时候得到大量的使用,但是随着支持向量机的出现而日渐衰落。在2012年Krizhevsky等人通过在 ImageNet上大规模的视觉识别挑战赛(the Large Scale Visual Recognition Challenge——ILSVRC)上达到的更高的分类准确率重新点燃了对CNNs的热情。他们的成功在于在120万张标签图片上训练巨大的CNN网络,并且在LeCun’s CNN 网络上采取了一些改进(例如:max(x;
0) 矫正非线性和“dropout”正则化)。
ImageNet上的显著结果在2012的视觉识别挑战赛的专题研讨会上得到了热烈的讨论。大家提炼出一个中心的议题:在ImageNet上CNN的分类结果推广到 PASCAL VOC数据集上做目标检测的会怎样?
我们通过构建图像分类和目标检测之间沟壑的桥梁来回答这一问题。
主要关注两个问题:用深度网络定位物体,并且用少部分标记的检测数据来训练高性能的模型。
一种途径是帧定位作为一种回归问题。(表现不好)
一个可选择的是构建一个滑动窗检测器。CNNs被用于这种方式至少20年,典型的是应用于约束的物体类别的分类对象,例如人脸和行人。为了维持高空间分辨率,这些CNNs网络通常仅有两个卷积层和一个池化层。我们也考虑到采用滑动窗口的方法。但是,窗口单元使我们的网络结构变得复杂,有五层卷积层,并且在输入图像上有一个巨大的可接受的区域(195*195像素范围)和跨度(32*32像素范围),这使得在滑动窗口模式下进行的精确定位很难。
与以上不同,我们解决CNN的定位问题通过“recognition using regions”的模式去操控,这种方法已成功运用到物体检测和语义分割。
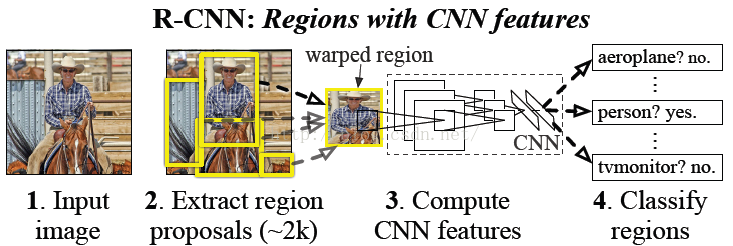
A、 输入图片
B、 提取 region proposals
C、 用CNN进行特征提取
D、 给定区域进行分类
B、用少量的标注数据进行fine-tune
orders of magnitude lower-dimensional than previously used regionfeatures)。
分析2012年的 Diagnosingerror in object detector得知,bounding-boxregression方法可以降低错误定位的问题。
我们的检测系统包括三个模块。
(1) 产生 category-independent regionproposals。
这些proposals定义我们检测器需要的候选区域。
(2) 用CNN来提取候选区域中的特征向量。
(3) 用一系列的线性SVM对每个区域进行分类。
包括:objectness,selective search,category-independent region proposals,constrained parametric min-cuts (CPMC), multi-scale combinatorial grouping等方法。因为R-CNN对特定region proposal 方法不可知,我们使用selective search的方法并将结果与其他检测方法结果对比。
由于候选区域大小不一,而CNN的输入数据维度必须一致,首先需要将候选区域转换。在可能转换的方式中,我们选择最简单的。不管候选区域的大小和长宽比,我们将物体附近的像素warp到要求的大小尺寸(we warp all pixels in a tightbounding box around it to the required size)。在warping之前,需要先扩展bounding box 以至于在warped大小尺寸基础上在原有的bounding
box周围恰好有p个像素的warped图像内容(我们用p=16)。可选择的warping方法在附录A讨论
(1) 用selectivesearch 提取2000的region proposals
(2) 对每个region proposals,将其转换为required size data(cnn的输入数据维度需要固定)
(3) 对每个region proposals,用cnn进行feature extraction
(4) 对一副图片中的每类用训练好的SVM model进行评分(score)
(5) 对一幅图片中的每类的所有评分区域通过greedynon-maximum suppression(非极大抑制)和IoU(intersection-over-union ,IoU的值定义:Region Proposal与Ground Truth的窗口的交集比并集的比值,如果IoU低于0.5,那么相当于目标还是没有检测到)来去除重复区域。
用SGD fine-tuneCNN的参数。每次SGD迭代,统一采样32正样本(over all classes),96负样本区域(background windows)
由于对某一类别来说,一个输入图片可能得到同一类的好多region proposals,显示的时候只是显示最优的区域。所以需要计算要显示区域(proposals)的激活值,按激活值的大小排序,执行非极大抑制,显示最大score的proposal
(1) Performance layer-by-layer,without fine-tuning。
未fine-tune的时候,发现fc6的结果优于fc7的结果。
(2) Performance layer-by-layer,with fine-tuning
Fine-tune 增加了mAP
(3) Comparison to recent featurelearning methods
(4) Detection error analysis
(5) Bounding box regression(appendix C)
———————————————————————————————————————————
【1】RCNN 译文 http://blog.csdn.net/u013488563/article/details/42027885
【2】RCNN 学习笔记http://blog.csdn.net/chenriwei2/article/details/38110387
(讲了论文中的主要方法、内容、测试过程、具体实现等 )
【3】RCNN算法详解 http://blog.csdn.net/shenxiaolu1984/article/details/51066975
从算法思想、流程开始讲起,后边会描述各个部分是如何操作的。
【4】基于R-CNN的物体检测 http://blog.csdn.net/hjimce/article/details/50187029
(建议看此博文)
【5】Selective Search讲解 http://blog.csdn.net/mao_kun/article/details/50576003
Rich featureHierarchies for accurate object detection and semantic segmentation
建议读此论文之前,先读 基于R_CNN的物体检测Abstract
PASCAL VOC(patternanalysis,statistical modelling and computationallearning visual object classes 模式分析、统计建模、计算学习、视觉物体分类 )数据集(用来做图片识别和物体检测)在物体检测领域中,之前很多的任务都是基于SIFT和HOG的。比较好的方法也是基于复杂的集成系统的,而作者提出一个简单而且可扩展的检测算法,这种算法提高了平均物体检测度(mAP:mean average precision ),
两点贡献:
(1)将CNN用在从底至上的region propasals上,从而进行物体定位和分割(one can apply high-capacity convolutional neural net-works (CNNs) tobottom-up region proposals in order tolocalize and segment objects)
(2)通过使用有监督预训练加上相关的finetune,解决物体识别标签数据有限的问题,提高性能
该方法把region proposals与CNNs结合,称之为R-CNN方法,Regions with CNN features。
1、Introduction
特征主导。之前在视觉识别任务上的进步都是基于SIFT和HOG特征的。在2010-2012年没有成效。Fukushima的神经认知机一个模式识别中受生物启发的分层结构和迁移不变模型,是早期在那样一个阶段的尝试。但是,这个神经认知机缺乏监督训练算法。建立在Rumelhart等人和 LeCun等人基础上的通过反向传播的随机梯度下降法是一种有效的训练卷积神经网络(一类神经认知机扩展的模型)的方法。
CNNs在90年代的时候得到大量的使用,但是随着支持向量机的出现而日渐衰落。在2012年Krizhevsky等人通过在 ImageNet上大规模的视觉识别挑战赛(the Large Scale Visual Recognition Challenge——ILSVRC)上达到的更高的分类准确率重新点燃了对CNNs的热情。他们的成功在于在120万张标签图片上训练巨大的CNN网络,并且在LeCun’s CNN 网络上采取了一些改进(例如:max(x;
0) 矫正非线性和“dropout”正则化)。
ImageNet上的显著结果在2012的视觉识别挑战赛的专题研讨会上得到了热烈的讨论。大家提炼出一个中心的议题:在ImageNet上CNN的分类结果推广到 PASCAL VOC数据集上做目标检测的会怎样?
我们通过构建图像分类和目标检测之间沟壑的桥梁来回答这一问题。
主要关注两个问题:用深度网络定位物体,并且用少部分标记的检测数据来训练高性能的模型。
(1)CNN定位问题
不像图像分类,检测要求在一张图像中定位物体(可能很多)。一种途径是帧定位作为一种回归问题。(表现不好)
一个可选择的是构建一个滑动窗检测器。CNNs被用于这种方式至少20年,典型的是应用于约束的物体类别的分类对象,例如人脸和行人。为了维持高空间分辨率,这些CNNs网络通常仅有两个卷积层和一个池化层。我们也考虑到采用滑动窗口的方法。但是,窗口单元使我们的网络结构变得复杂,有五层卷积层,并且在输入图像上有一个巨大的可接受的区域(195*195像素范围)和跨度(32*32像素范围),这使得在滑动窗口模式下进行的精确定位很难。
与以上不同,我们解决CNN的定位问题通过“recognition using regions”的模式去操控,这种方法已成功运用到物体检测和语义分割。
A、 输入图片
B、 提取 region proposals
C、 用CNN进行特征提取
D、 给定区域进行分类
(2)标注数据量少的问题
A、用无监督的卷积进行预训练B、用少量的标注数据进行fine-tune
(3)矩阵向量积和非极大抑制
系统是非常高效的,用矩阵向量积和非极大抑制的方法对于特定类别进行计算。这种计算是基于不同种类物体的特征,而且这种计算比之前用region feature的计算少两个数量级(This computationalproperty follows from features that are shared across all categories and thatare also twoorders of magnitude lower-dimensional than previously used regionfeatures)。
(4)bounding-box regression
分析2012年的 Diagnosingerror in object detector得知,bounding-boxregression方法可以降低错误定位的问题。
2、Object detection with R-CNN
我们的检测系统包括三个模块。
(1) 产生 category-independent regionproposals。
这些proposals定义我们检测器需要的候选区域。
(2) 用CNN来提取候选区域中的特征向量。
(3) 用一系列的线性SVM对每个区域进行分类。
2.1 Module design
Region proposals (Selective search)
最近很多论文提供了产生category-independent region proposals的方法。包括:objectness,selective search,category-independent region proposals,constrained parametric min-cuts (CPMC), multi-scale combinatorial grouping等方法。因为R-CNN对特定region proposal 方法不可知,我们使用selective search的方法并将结果与其他检测方法结果对比。
Feature extraction (Appendix A)
用基于Caffe 的AlexNet从region proposal上提取4096维的特征向量。输入为227*227的RGB图像,5个卷积层和两个全连接层。由于候选区域大小不一,而CNN的输入数据维度必须一致,首先需要将候选区域转换。在可能转换的方式中,我们选择最简单的。不管候选区域的大小和长宽比,我们将物体附近的像素warp到要求的大小尺寸(we warp all pixels in a tightbounding box around it to the required size)。在warping之前,需要先扩展bounding box 以至于在warped大小尺寸基础上在原有的bounding
box周围恰好有p个像素的warped图像内容(我们用p=16)。可选择的warping方法在附录A讨论
2.2 Test-time detection
对于test image,detection步骤如下:(1) 用selectivesearch 提取2000的region proposals
(2) 对每个region proposals,将其转换为required size data(cnn的输入数据维度需要固定)
(3) 对每个region proposals,用cnn进行feature extraction
(4) 对一副图片中的每类用训练好的SVM model进行评分(score)
(5) 对一幅图片中的每类的所有评分区域通过greedynon-maximum suppression(非极大抑制)和IoU(intersection-over-union ,IoU的值定义:Region Proposal与Ground Truth的窗口的交集比并集的比值,如果IoU低于0.5,那么相当于目标还是没有检测到)来去除重复区域。
2.3 Training
Supervised pre-training
用基于image-levelannotations(没有label)作为预训练数据,用ILSVRC2012作fine-tune(label比较少)Domain-specific fine-tuning
把所有的regionproposals 与ground-truth box 的IoU>= 0.5认为是正样本,其他的是负样本。用SGD fine-tuneCNN的参数。每次SGD迭代,统一采样32正样本(over all classes),96负样本区域(background windows)
Object category classifiers
3、Visualization,ablation,and modes of error
3.1 Visualizing learned features
用反卷积的方法进行可视化,直接展示出网络所学到的东西。由于对某一类别来说,一个输入图片可能得到同一类的好多region proposals,显示的时候只是显示最优的区域。所以需要计算要显示区域(proposals)的激活值,按激活值的大小排序,执行非极大抑制,显示最大score的proposal
3.2 Ablation studies
(1) Performance layer-by-layer,without fine-tuning。
未fine-tune的时候,发现fc6的结果优于fc7的结果。
(2) Performance layer-by-layer,with fine-tuning
Fine-tune 增加了mAP
(3) Comparison to recent featurelearning methods
(4) Detection error analysis
(5) Bounding box regression(appendix C)
———————————————————————————————————————————
参考网址及参考文献
【1】RCNN 译文 http://blog.csdn.net/u013488563/article/details/42027885
【2】RCNN 学习笔记http://blog.csdn.net/chenriwei2/article/details/38110387
(讲了论文中的主要方法、内容、测试过程、具体实现等 )
【3】RCNN算法详解 http://blog.csdn.net/shenxiaolu1984/article/details/51066975
从算法思想、流程开始讲起,后边会描述各个部分是如何操作的。
【4】基于R-CNN的物体检测 http://blog.csdn.net/hjimce/article/details/50187029
(建议看此博文)
【5】Selective Search讲解 http://blog.csdn.net/mao_kun/article/details/50576003

相关文章推荐
- 论文阅读笔记:R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation 笔记
- 论文笔记——Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- 《Rich feature hierarchies for accurate object detection and semantic segmentation》笔记
- 【CV论文阅读】:Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- R-CNN学习笔记2:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation论文笔记
- 【论文笔记】Rich feature hierarchies for accurate object detection and semantic segmentation
- R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation(阅读)
- RCNN系列学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentation
- rcnn学习笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文阅读:RCNN[Rich feature hierarchies for accurate object detection and semantic segmentation]
- 【转】R-CNN学习笔记2:Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- 论文笔记|Rich feature hierarchies for accurate object detection and semantic segmentation
- 深度学习论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- RCNN学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation