RCNN(一):Rich feature hierarchies for accurate object detection and semantic segmentation
2016-08-04 19:37
615 查看
RCNN:基于丰富层次特征的精确目标检测和语义分割
rbg大神将深度卷积网络引入目标检测领域,大幅提高了准确度和精度。并由此产生一系列改进算法。从RCNN -> SPP-NET -> Fast RCNN -> Faster RCNN 准确度和速度一步步提高,最终近乎于实时的水平。本周粗略看了这几篇论文,总结一下方便以后回顾以及和大家讨论。
(未完待续,码字中…)
摘要和引言
传统的目标检测方法主要是提取图像的SIFT 、HOG特征这些手工设计的特征进行目标定位以及识别。从2012-2014年,这些传统的方法遇到了瓶颈,取得一些进展主要是通过ensemble systems。卷积神经网络从2012年起在图像分类上的大幅提升效果使得RBG大神考虑到能否将CNN应用到目标检测领域。但是不同于分类问题,目标检测需要目标的具体位置,这时通常的CNN难以做到的。本文使用的方法是recognition using regions,这种方法已经在目标检测以及语义分割上成功应用[21,39,5]。在测试的时候,我们的方法为每个图片产生2000个左右类别无关的目标候选区域,然后我们通过CNN为每个候选区域提取到一个定长的特征向量,然后通过SVM分类每一个候选区域。
本文的另一个贡献是,在目标检测领域,一般样本是很稀缺的,通常做法是通过无监督的预训练[35],然后再微调。文中使用的方法是现在大的数据集如ImageNet上进行有监督的预训练,然后在特定的测试集上进行有监督微调,发现效果比无监督的要好。
Since our system combines region proposals with CNNs, we dub the method R-CNN:Regions with CNN features.
相关术语介绍
IoU 指重叠程度,计算公式为:A∩B/A∪Bgreedy non-maximum suppression 贪婪非极大值抑制
指的是,假设ABCDEF五个区域候选,首先根据概率从大刀小排列。假设为FABCDE。然后从最大的F开始,计算F与ABCDE是否IoU是否超过某个阈值,如果超过则将ABC舍弃。然后再从D开始,直到集合为空。
Object detection with R-CNN
本文的网络主要分为三个部分,Region proposal、Feature extractiom、SVMS。这部分的讲述我改变了原本文章的流程,按照我的思路去写。
R-CNN的目标检测流程如下:
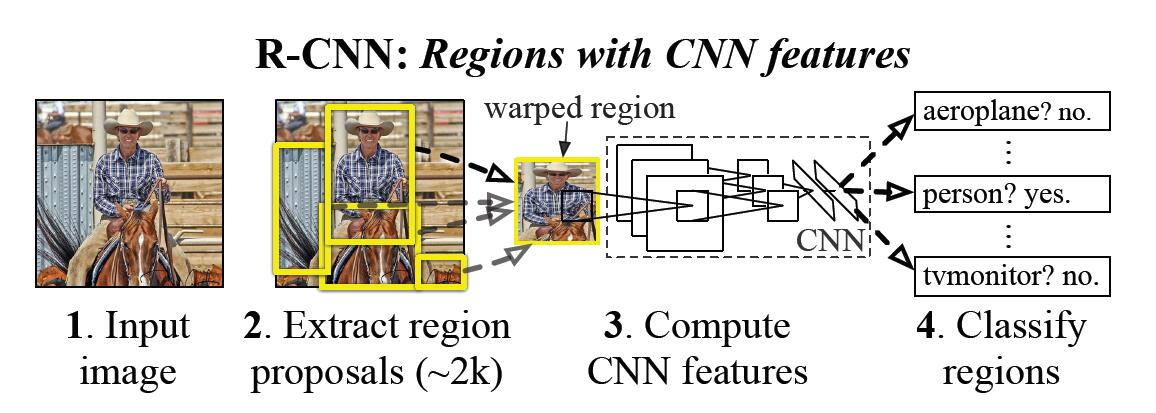
使用大的数据集训练CNN网络模型。如使用VGG模型和ILSVRC2012进行训练,这些训练集是不包含bounding box的,只有具体的类别。
首先通过Region proposal获得大约2k个与类别无关的区域候选。这里面作者使用的方法是selective search。作者使用这个方法主要是为了能够和现有的方法进行对比试验。
将CNN模型最后的softMax层分类结果改为我们目标检测所需要的分类结果数目,注意加上一类为背景区域。
将2K个区域候选按照IoU值进行分类,IoU<0.5的分为背景。反之分到相应的类别内。因为CNN要求固定大小的图像作为输入,因此需要将每一个区域候选resize到227*277。作者使用的方法是直接进行同向放缩。然后将学习率设置为0.001(进行CNN模型训练的1/10),为了避免微调对网络模型产生较大的更改。然后就可以进行微调了,每次进行SGD迭代的时候,作者用32个正样本(IOU>0.5)和96个负样本(因为正样本实在太少了)。这样通过CNN我们就能拿到Region proposal的特征了。同时,这里面所有的分类共享的是同一个卷积神经网络,因此计算开销也比较小。
拿到CNN特征后需要为每一类训练一个SVM分类器用以筛选这个东西是背景还是前景。对于SVM的训练,作者将IoU<0.3的作为负样本,正样本定义为ground-truth bounding box。使用的方法是standard hard negative mining converges[17,37]。
通过SVM判断后,同一类别可能会产生很多的区域候选,这时候要进行区域合并了。作者提出,首先通过SVM的结果对于每个区域候选进行打分,然后根据打分的结果对于同一类使用greedy non-maximum suppression算法进行区域合并。
实验结果分析
rbg大神的文章通常对于实验结果分析的特别透彻,实验分析部分我将在后面补上。模型分析
rbg首次将CNN应用到目标检测,是目标检测和深度学习的一大进步。模型大幅提高了目标检测的准确度,但是也存在以下的问题:Region proposal耗时较多
对于每一个Region proposal都需要resize然后进行CNN特征提取,耗时严重。
不是端到端的训练,训练比较麻烦。
当然,针对这些问题,后面的SPP-NET、Fast-RCNN、Faster-RCNN进行了改进,还请看后面的文章哦。
References
[1] B. Alexe, T. Deselaers, and V. Ferrari. Measuring the objectness of image windows. TPAMI, 2012. 2[2] P. Arbel´aez, B. Hariharan, C. Gu, S. Gupta, L. Bourdev, and J. Malik. Semantic segmentation using regions and parts.
[3] P. Arbel´aez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik.Multiscale combinatorial grouping. In CVPR, 2014. 3
[4] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV,
[5] J. Carreira and C. Sminchisescu. CPMC: Automatic object segmentation using constrained parametric min-cuts.
[6] D. Cires¸an, A. Giusti, L. Gambardella, and J. Schmidhuber.Mitosis detection in breast cancer histology images with
deep neural networks. In MICCAI, 2013. 3
[7] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005. 1
[8] T. Dean, M. A. Ruzon, M. Segal, J. Shlens, S. Vijayanarasimhan, and J. Yagnik. Fast, accurate detection of
100,000 object classes on a single machine. In CVPR, 2013.3
[9] J. Deng, A. Berg, S. Satheesh, H. Su, A. Khosla, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Competition
2012 (ILSVRC2012). http://www.image-net.org/challenges/LSVRC/2012/. 1
[10] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database.
[11] J. Deng, O. Russakovsky, J. Krause, M. Bernstein, A. C.Berg, and L. Fei-Fei. Scalable multi-label annotation.
[12] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang,E. Tzeng, and T. Darrell. DeCAF: A Deep Convolutional
Activation Feature for Generic Visual Recognition. In ICML,
[13] M. Douze, H. J´egou, H. Sandhawalia, L. Amsaleg, and C. Schmid. Evaluation of gist descriptors for web-scale image
search. In Proc. of the ACM International Conference on Image and Video Retrieval, 2009. 13
[14] I. Endres and D. Hoiem. Category independent object proposals.
[15] M. Everingham, L. Van Gool, C. K. I.Williams, J.Winn, and A. Zisserman. The PASCAL Visual Object Classes (VOC)
[16] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. TPAMI, 2013. 10
[17] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan.Object detection with discriminatively trained part
based models. TPAMI, 2010. 2, 4, 7, 12
[18] S. Fidler, R. Mottaghi, A. Yuille, and R. Urtasun. Bottom-up segmentation for top-down detection. In CVPR, 2013. 4,
[19] K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition
unaffected by shift in position. Biological cybernetics,36(4):193–202, 1980. 1
[20] R. Girshick, P. Felzenszwalb, and D. McAllester. Discriminatively trained deformable part models, release 5.
http://www.cs.berkeley.edu/˜rbg/latent-v5/. 2,5, 6, 7
[21] C. Gu, J. J. Lim, P. Arbel´aez, and J. Malik. Recognitionusing regions. In CVPR, 2009. 2
[22] B. Hariharan, P. Arbel´aez, L. Bourdev, S. Maji, and J. Malik.Semantic contours from inverse detectors. In ICCV, 2011.
[23] D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV. 2012. 2, 7, 8
[24] Y. Jia. Caffe: An open source convolutional architecture for fast feature embedding.
http://caffe.berkeleyvision.org/, 2013. 3
[25] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS,
[26] Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard,W. Hubbard, and L. Jackel. Backpropagation applied to
handwritten zip code recognition. Neural Comp., 1989. 1
[27] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradientbasedlearning applied to document recognition. Proc. of the
[28] J. J. Lim, C. L. Zitnick, and P. Doll´ar. Sketch tokens: A learned mid-level representation for contour and object detection.In CVPR, 2013. 6, 7
[29] D. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 2004. 1
[30] A. Oliva and A. Torralba. Modeling the shape of the scene:A holistic representation of the spatial envelope. IJCV,
[31] X. Ren and D. Ramanan. Histograms of sparse codes forobject detection. In CVPR, 2013. 6, 7
[32] H. A. Rowley, S. Baluja, and T. Kanade. Neural networkbased face detection. TPAMI, 1998. 2
[33] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. Parallel
Distributed Processing, 1:318–362, 1986. 1
[34] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. OverFeat: Integrated Recognition, Localization
and Detection using Convolutional Networks. In ICLR, 2014. 1, 2, 4, 10
[35] P. Sermanet, K. Kavukcuoglu, S. Chintala, and Y. LeCun. Pedestrian detection with unsupervised multi-stage feature
learning. In CVPR, 2013. 2
[36] H. Su, J. Deng, and L. Fei-Fei. Crowdsourcing annotations for visual object detection. In AAAI Technical Report, 4th
Human Computation Workshop, 2012. 8
[37] K. Sung and T. Poggio. Example-based learning for viewbased human face detection. Technical Report A.I. Memo
No. 1521, Massachussets Institute of Technology, 1994. 4
[38] C. Szegedy, A. Toshev, and D. Erhan. Deep neural networks for object detection. In NIPS, 2013. 2
[39] J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013. 1, 2, 3,
[40] R. Vaillant, C. Monrocq, and Y. LeCun. Original approach for the localisation of objects in images. IEE Proc on Vision,Image, and Signal Processing, 1994. 2
[41] X.Wang, M. Yang, S. Zhu, and Y. Lin. Regionlets for generic object detection. In ICCV, 2013. 3, 5
[42] M. Zeiler, G. Taylor, and R. Fergus. Adaptive deconvolutional networks for mid and high level feature learning. In
[43] K. Simonyan and A. Zisserman. Very Deep ConvolutionalNetworks for Large-Scale Image Recognition. arXiv preprint, arXiv:1409.1556, 2014. 6, 7, 14

相关文章推荐
- RCNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- 2014-RCNN-Rich feature hierarchies for accurate object detection and semantic segmentation 翻译
- RCNN系列学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation(RCNN)
- rcnn学习笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记《Rich Feature Hierarchies for accurate object detection and semantic segmentation》
- 论文笔记|Rich feature hierarchies for accurate object detection and semantic segmentation
- (R-CNN)Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文笔记——Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation(译)
- RCNN学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentation
- 【CV论文阅读】:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation 笔记
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- RCNN学习笔记(2):Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation论文笔记
- RCNN学习笔记(2):Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation(泛读)
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation