PHP抓取百度百科数据实践
2017-02-24 12:39
204 查看
最近在用PHP抓取各种IP数据,这里讲一下在抓取百度百科数据时的步骤以及遇到的坑。
首先我们要确定抓取的内容是什么。比如我们想抓取“周杰伦”的数据。我们直接在百度搜索周杰伦,会出现百度的搜索结果,其中就有百度百科的内容,我们直接点进去。
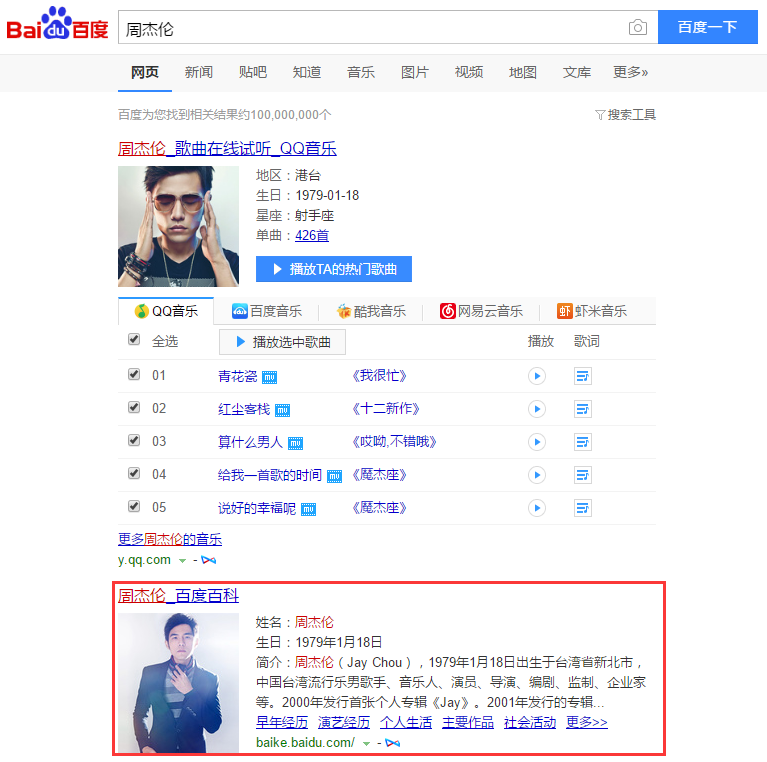
我们先看一下我们搜索结果的百度百科URL是什么样子的:

可以看到格式为http://baike.baidu.com/link?url=para
b85c
ms
其中这个params其实就是urlencode我们搜索的关键字之后形成的参数,所以我们可以根据前端直接POST过来的关键字进行URL的拼接之后用CURL或者phpQuery来抓取百度百科页面的信息。但是这里有一个问题。我们搜索出来的关键字的百科信息可能对应了不同的词条。比如我们搜索了“仙剑奇侠传“,我们本意想搜索胡歌主演的电视剧,但是百科的第一词条却是显示的仙剑奇侠传这个游戏,这个词条是一个多义词。所以我们前端传过来的值最好是确定的百度百科URL,这样我们抓取的信息会准确无误。
好了现在有了URL了,我们下面就要开始抓取我们想要的数据了。最想要的数据应该就是我们搜索出来的词条的基本信息,就是图下的内容:
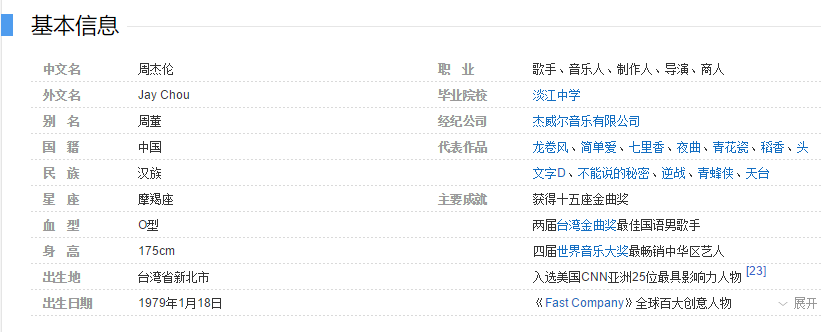
周杰伦是名人,你可按照词条的分类不同建立不同的数据表,比如人物一张表,影视内容一张表等等,因为同一类的百科基本信息组成都差不多。如果用NoSQL就更方便了,直接把这些信息全放进去就可以。
抓取页面一部分的内容还是用phpQuery比较方便,我们先看一下这个基本信息的DOM元素:
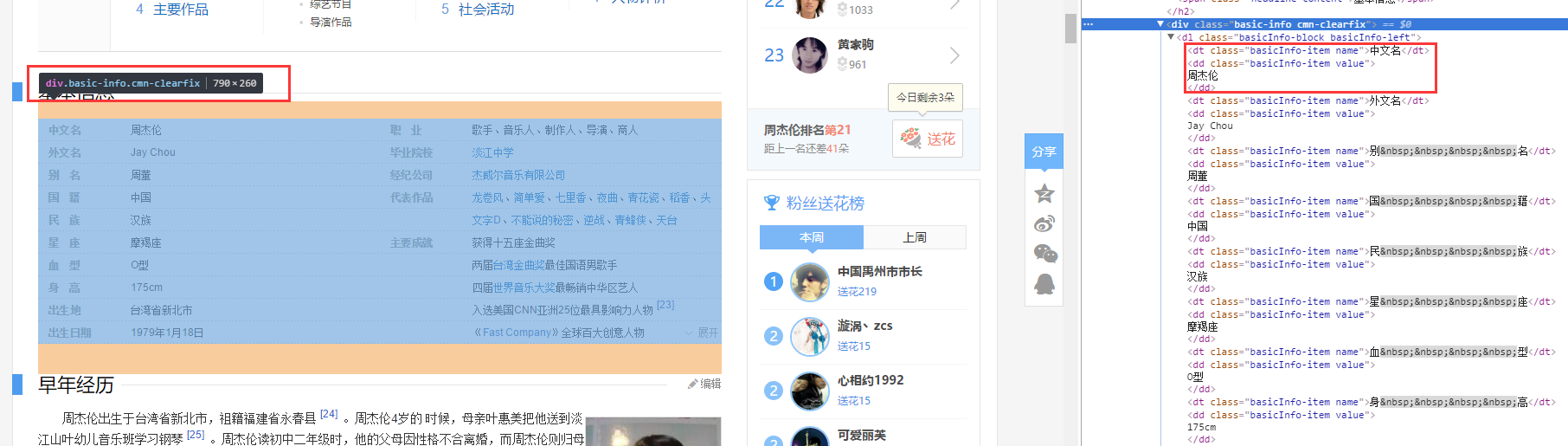
可以看到这个是一个basic-info为class的div包裹的,左边的信息在basicInfo-left中,右边的信息在basicInfo-right中。具体的信息在一个dt和dd组成的元素里,一个信息(在.basicInfo-item name的class)对应一个值(在basicInfo-item value的class中)。
我们直接把这个class为basic-info的div里面的html抓取下来就好,剩下我们在用正则匹配我们想要的内容。
直接pq('.basic-info')->html()就可以了。
我们先看一下抓取到的内容是什么样子的:

基本上就是一个原始的HTML内容。我们要正则匹配出来我们想要的信息然后存入相应的字段中。
我们先把这个字符串里的空格都清楚掉,方便我们的正则匹配,我这里写了一个函数:
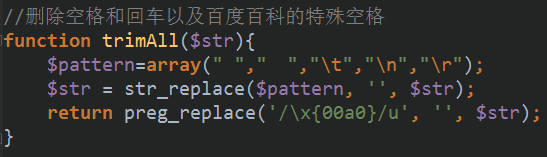
!注意:可以看到我最后还替换了一个\x{00a0}的东西,这个是什么呢?这个就是一个坑。大家可以在上面的HTML图中看到,其中信息为两个字的中间有四个空格,但是这个空格并不能用平常的空格给代替掉,必须用ASCII码来替换,这是需要注意的。
接下来正则匹配我们想要的信息:

这里也要注意,有些我们想要的信息是有多个信息匹配的,虽然名字不一样,但是里面信息的内容却是相近的。这里举例的是明星和运动演员,都是获得的奖项,但是名字却不一样。同样的还有电影的票房,票房、全球票房、统计票房等等,其实都是票房的字段信息,随意抓取的时候多观察几个百科页面的信息,做到万无一失。
然后将匹配到的信息存到数组中准备插入数据库,在插入数据库之前还有一个工作要做:
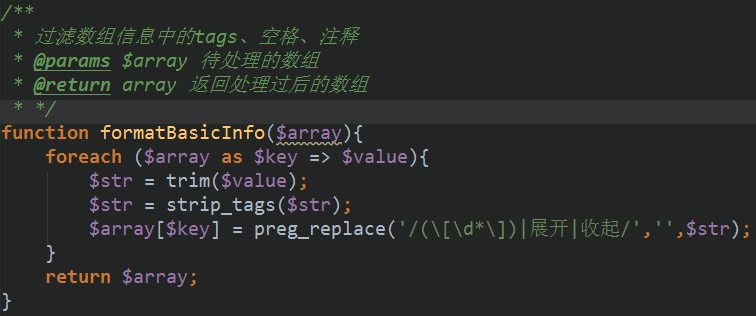
我们要把数组中的标签、注释和多余信息给剔除。
注释是这样的:
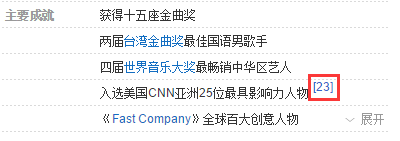
多余信息是这样的:
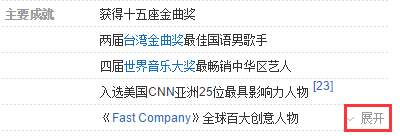
这些都是要注意的内容。
最后我们就得到了我们想要的数据了,分类插入数据库就OK啦。
首先我们要确定抓取的内容是什么。比如我们想抓取“周杰伦”的数据。我们直接在百度搜索周杰伦,会出现百度的搜索结果,其中就有百度百科的内容,我们直接点进去。
我们先看一下我们搜索结果的百度百科URL是什么样子的:
可以看到格式为http://baike.baidu.com/link?url=para
b85c
ms
其中这个params其实就是urlencode我们搜索的关键字之后形成的参数,所以我们可以根据前端直接POST过来的关键字进行URL的拼接之后用CURL或者phpQuery来抓取百度百科页面的信息。但是这里有一个问题。我们搜索出来的关键字的百科信息可能对应了不同的词条。比如我们搜索了“仙剑奇侠传“,我们本意想搜索胡歌主演的电视剧,但是百科的第一词条却是显示的仙剑奇侠传这个游戏,这个词条是一个多义词。所以我们前端传过来的值最好是确定的百度百科URL,这样我们抓取的信息会准确无误。
好了现在有了URL了,我们下面就要开始抓取我们想要的数据了。最想要的数据应该就是我们搜索出来的词条的基本信息,就是图下的内容:
周杰伦是名人,你可按照词条的分类不同建立不同的数据表,比如人物一张表,影视内容一张表等等,因为同一类的百科基本信息组成都差不多。如果用NoSQL就更方便了,直接把这些信息全放进去就可以。
抓取页面一部分的内容还是用phpQuery比较方便,我们先看一下这个基本信息的DOM元素:
可以看到这个是一个basic-info为class的div包裹的,左边的信息在basicInfo-left中,右边的信息在basicInfo-right中。具体的信息在一个dt和dd组成的元素里,一个信息(在.basicInfo-item name的class)对应一个值(在basicInfo-item value的class中)。
我们直接把这个class为basic-info的div里面的html抓取下来就好,剩下我们在用正则匹配我们想要的内容。
直接pq('.basic-info')->html()就可以了。
我们先看一下抓取到的内容是什么样子的:
基本上就是一个原始的HTML内容。我们要正则匹配出来我们想要的信息然后存入相应的字段中。
我们先把这个字符串里的空格都清楚掉,方便我们的正则匹配,我这里写了一个函数:
!注意:可以看到我最后还替换了一个\x{00a0}的东西,这个是什么呢?这个就是一个坑。大家可以在上面的HTML图中看到,其中信息为两个字的中间有四个空格,但是这个空格并不能用平常的空格给代替掉,必须用ASCII码来替换,这是需要注意的。
接下来正则匹配我们想要的信息:
这里也要注意,有些我们想要的信息是有多个信息匹配的,虽然名字不一样,但是里面信息的内容却是相近的。这里举例的是明星和运动演员,都是获得的奖项,但是名字却不一样。同样的还有电影的票房,票房、全球票房、统计票房等等,其实都是票房的字段信息,随意抓取的时候多观察几个百科页面的信息,做到万无一失。
然后将匹配到的信息存到数组中准备插入数据库,在插入数据库之前还有一个工作要做:
我们要把数组中的标签、注释和多余信息给剔除。
注释是这样的:
多余信息是这样的:
这些都是要注意的内容。
最后我们就得到了我们想要的数据了,分类插入数据库就OK啦。

相关文章推荐
- PHP抓取百度百科数据实践
- PHP的cURL库功能简介:抓取网页,POST数据及其他
- Comet初步研究与实践 – PHP到C#应用程序的数据推送DEMO
- PHP实践之路(三)PHP初探数据类型
- PHP的CURL方法curl_setopt()函数案例介绍(抓取网页,POST数据)
- python实践 - 抓取网页中的图片和数据
- 使用PHP进行网页数据抓取小结
- 使用php发送Http请求,抓取网页数据
- C实现PHP扩展《Fetch_Url》类数据抓取
- php 网页数据抓取 简单实例
- PHP的cURL库功能简介:抓取网页,POST数据及其他
- PHP的cURL库功能简介 抓取网页、POST数据及其他
- PHP的cURL库功能简介 抓取网页、POST数据及其他
- PHP应用curl对ajax型的网页数据进行抓取
- 用PHP抓取数据
- php 关于抓取不到数据的问题
- PHP的cURL库功能简介:抓取网页,POST数据及其他
- PHP抓取网络数据
- 【引用】PHP的cURL库功能简介:抓取网页,POST数据及其他