页面置换算法--LFU算法实现-O(1)时间复杂度
2017-02-21 10:50
531 查看
LFU: least frequently used (LFU) page-replacement algorithm
若有读者看到,希望在理解思路后,自己多敲几遍(收获会较大)
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
put(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted.
Follow up:
Could you do both operations in O(1) time complexity?
Example:
LFUCache cache = new LFUCache( 2 /* capacity */ );
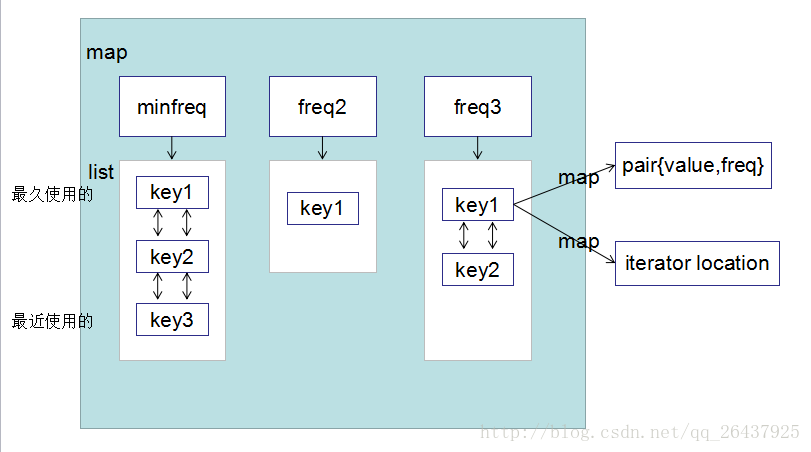
https://discuss.leetcode.com/topic/78833/c-89ms-beats-99-8-using-unordered_map-list-of-list
数据结构设计
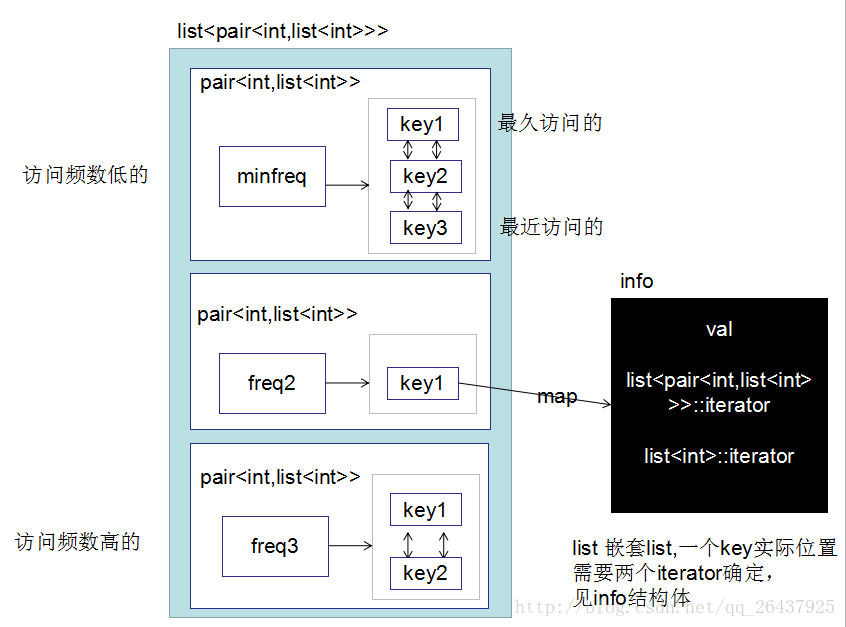
若有读者看到,希望在理解思路后,自己多敲几遍(收获会较大)
leetcode题目地址
https://leetcode.com/problems/lfu-cache/?tab=Description题目描述
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: get and put.get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
put(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted.
Follow up:
Could you do both operations in O(1) time complexity?
Example:
LFUCache cache = new LFUCache( 2 /* capacity */ );
cache.put(1, 1); cache.put(2, 2); cache.get(1); // returns 1 cache.put(3, 3); // evicts key 2 cache.get(2); // returns -1 (not found) cache.get(3); // returns 3. cache.put(4, 4); // evicts key 1. cache.get(1); // returns -1 (not found) cache.get(3); // returns 3 cache.get(4); // returns 4
题目讨论,各种解决方案
https://leetcode.com/problems/lfu-cache/?tab=Solutionsac1
数据结构设计ac代码
class LFUCache {
public:
int size;
int cap;
int minfreq;
map<int,pair<int,int>> m;//key to pair<value,freq>
map<int,list<int>::iterator> mIter;//key to list location , key在 list中的位置一个iterator
map<int,list<int>> fm;//freq to list , list存放的是所有的key, 最后的key是最近访问过的,头部的是最近没有访问的(淘汰)
public:
LFUCache(int capacity) {
cap = capacity;
size = 0;
}
int get(int key) {
if(m.count(key) == 0)
return -1;
//key 频率加1,删除原来其在fm中的位置,插入到新的位置
fm[m[key].second].erase(mIter[key]);
m[key].second ++;
fm[m[key].second].push_back(key);
mIter[key] = --fm[m[key].second].end(); // 当前key所在的位置
if(fm[minfreq].size() == 0) //上面的步骤处理后,可能最小频率已经删除了数据,所以需要判断
minfreq ++;
return m[key].first;
}
void put(int key, int value) {
if(cap <= 0)
return ;
/*
调用成员方法get
如果不存在,返回-1;
如果已经存在,那么就会修改频数,删除旧的位置,添加到新的位置,但是值仍然是原来的,需要修改
*/
int storeValue = get(key);
if(storeValue != -1)
{
m[key].first = value;
return; // 直接返回
}
// 不存在的情况, 已经满了,需要删除频率最小,最近都没有访问过的那个key
if(size >= cap){
m.erase(fm[minfreq].front());
mIter.erase(fm[minfreq].front());
fm[minfreq].pop_front();
size --;
}
pair<int, int> pr(value, 1);
m[key] = pr;
fm[1].push_back(key);
mIter[key] = --fm[1].end();
minfreq = 1;
size ++;
}
};ac代码改写1(还是同样的数据结构,把情况分细,写清楚)
class LFUCache {
public:
int size;
int cap;
int minfreq;
map<int,pair<int,int>> m;//key to pair<value,freq>
map<int,list<int>::iterator> mIter;//key to list location , key在 list中的位置一个iterator
map<int,list<int>> fm;//freq to list , list存放的是所有的key, 最后的key是最近访问过的,头部的是最近没有访问的(淘汰)
public:
LFUCache(int capacity) {
cap = capacity;
size = 0;
minfreq = -1;
}
int get(int key) {
// key 不存在
if(m.count(key) == 0)
return -1;
// key 存在
pair<int,int> oldPair = m[key];
list<int>::iterator oldIter = mIter[key];
fm[oldPair.second].erase(oldIter); // 从旧的频数fm[oldPair.second]中删除该key
// 判断是否需要删除fm.erase(oldPair.second),和 更新minfreq
if(oldPair.second == minfreq && fm[oldPair.second].empty()){
fm.erase(fm.begin());
minfreq ++;
}else if(oldPair.second > minfreq && fm[oldPair.second].empty())
{
fm.erase(oldPair.second);
}
// 构造新的
pair<int,int> newPair(oldPair.first, oldPair.second + 1);
m[key] = newPair; // 更新m的pair<int,int>
if(fm.count(newPair.second) == 0)
{
list<int> li;
li.push_back(key);
fm[newPair.second] = li;
}else{
fm[newPair.second].push_back(key);
}
mIter[key] = std::prev(fm[newPair.second].end()); // 更新mIter的list<int>::iterator
return m[key].first;
}
void put(int key, int value) {
if(cap <= 0)
return ;
int storeValue = get(key);// 调用get函数,会完成其更新操作
// key 不存在
if(storeValue == -1)
{
//需要淘汰
if(size >= cap)
{
int outKey = *fm[minfreq].begin();
m.erase(outKey);
mIter.erase(outKey);
fm[minfreq].pop_front();
size --;
}
if(minfreq > 1 && fm[minfreq].empty())
{
fm.erase(fm.begin());
pair<int, int> pr(value, 1);
m[key] = pr;
list<int> li;
li.push_back(key);
fm[1] = li;
mIter[key] = std::prev(fm[1].end());
minfreq = 1;
size ++;
}else{
pair<int, int> pr(value, 1);
m[key] = pr;
fm[1].push_back(key);
mIter[key] = std::prev(fm[1].end());
minfreq = 1;
size ++;
}
}else{
// 可以存在,由于get已经操作了部分,这里只需要更新value
m[key].first = value;
}
}
};ac代码同样是思路,第三次编写,思路更加清楚,代码也比较清楚了
需要注意变量的更新,是所有变量都要考虑到,不能漏掉某个变量,然后看看自己数据结构的变化。class LFUCache {
public:
int size;
int cap;
int minFreq;
map<int,list<int>> fm;
map<int,list<int>::iterator> mIter;
map<int,pair<int,int>> m;
public:
LFUCache(int capacity) {
size = 0;
cap = capacity;
minFreq = -1;
}
int get(int key) {
if(m.count(key) == 0)
return -1;
int oldFreq = m[key].second;
fm[oldFreq].erase(mIter[key]); // 删除其原来在fm中的位置
if(fm[oldFreq].empty())
{
fm.erase(oldFreq); // fm[频率] 里面一个key都没有了,就直接删除它
if(oldFreq == minFreq)
minFreq ++;
}
int newFreq = oldFreq + 1;
m[key].second = newFreq; // 更新key的pair<value,freq>
if(fm.count(newFreq) == 0)
{
list<int> li; // 构造当前频率的fm
li.push_back(key);
fm[newFreq] = li;
}else{
fm[newFreq].push_back(key); // 新插入是最近访问的,在链表的尾部
}
mIter[key] = std::prev(fm[newFreq].end()); // 更新key在fm[]中的位置 mIter
return m[key].first; // 返回其value
}
void put(int key, int value) {
if(cap <= 0)
return;
int storeVal = get(key); // 调用get函数 完成部分更新操作
// 原来是存在的,还需要更新value
if(storeVal != -1)
{
m[key].first = value;
return;
}
// key不存在,考虑是否需要淘汰,不顾新插入的freq肯定是1,肯定插入到list末尾
pair<int,int> pa(value, 1);
m[key] = pa;
// LFU淘汰
if(size == cap)
{
int outKey = *fm[minFreq].begin();// 记录要淘汰的key
fm[minFreq].pop_front(); // 这一句就是淘汰
mIter.erase(outKey);
m.erase(outKey);
size --;
if(fm[minFreq].empty())
{
if(minFreq > 1)
{
fm.erase(minFreq);
}
}
}
size ++;
minFreq = 1;
if(fm.count(minFreq) == 0)
{
list<int> li;
li.push_back(key);
fm[minFreq]= li;
}else{
fm[minFreq].push_back(key);
}
mIter[key] = std::prev( fm[minFreq].end() );
}
};ac2
参考https://discuss.leetcode.com/topic/78833/c-89ms-beats-99-8-using-unordered_map-list-of-list
数据结构设计
ac代码
class LFUCache {
public:
struct info
{
int val;
list<pair<int, list<int>>>::iterator it_pair;
list<int>::iterator it_key;
};
LFUCache(int capacity) {
cap_ = capacity;
}
int get(int key) {
auto it = map_.find(key);
if (it == map_.end())
{
return -1;
}
else
{
visit(it, key);
return it->second.val;
}
}
void put(int key, int value) {
auto it = map_.find(key);
// 已经存在,需要更新value,改变其频数,在map等中的信息都要更改
if (it != map_.end())
{
visit(it, key);
it->second.val = value;
}
else
{
if (cap_ == 0) return;
// del
if (map_.size() == cap_)
{
auto it = list_.front().second.begin();
map_.erase(*it);
list_.front().second.erase(it);
if (list_.front().second.size() == 0)
list_.erase(list_.begin());
}
// insert
if (list_.empty() || list_.front().first != 1)
{
list<int> li;
li.push_back(key);
pair<int,list<int>> pr(1, li);
list_.push_front(pr);
//list_.push_front({1, {key}});
}
else
{
// 最小的频数list中插入一个key, 插入到最后面表示是最近访问到的
list_.front().second.push_back(key);
}
info in;
in.val = value;
in.it_pair = list_.begin();
in.it_key = std::prev(list_.front().second.end());
map_[key] = in;
//map_[key] = {value, list_.begin(), std::prev(list_.front().second.end())};
}
}
protected:
void visit(unordered_map<int, info>::iterator it, int key)
{
auto it_pair = it->second.it_pair; // 在list中的哪个频数上面
auto it_key = it->second.it_key; // 在map中的位置
int count = it_pair->first + 1; // 频数加1
it_pair->second.erase(it_key); // 删除该key,如果对应频数没有key了, list_要将这个记录直接删除,并把it指向下一个记录
if (it_pair->second.size() == 0)
it_pair = list_.erase(it_pair);
else
{
std::advance(it_pair, 1); // it_pair往前移动
}
if (it_pair == list_.end() || it_pair->first != count)
{
// list_没有该新的频数,就构造出来,插入到对应的位置
list<int> li;
li.push_back(key);
pair<int,list<int>> pr(count, li);
it_pair = list_.insert(it_pair, pr);
//it_pair = list_.insert(it_pair, {count, {key}});
}
else
{
it_pair->second.push_back(key);
}
// 更新info信息
it->second.it_pair = it_pair;
it->second.it_key = std::prev(it_pair->second.end());
}
int cap_;
list<pair<int, list<int>>> list_;
unordered_map<int, info> map_;
};同样的ac2思想,仿照ac1代码形式改写,还是可以ac,不过ac时间更长(可能是C++ stl相关操作的影响)
class LFUCache {
public:
struct Info
{
int val;
list<pair<int, list<int>>>::iterator it_pair;
list<int>::iterator it_key;
};
int size;
int cap;
list<pair<int, list<int>>> liFreq; // freq keys
unordered_map<int, Info> mp; //key->Info
public:
LFUCache(int capacity) {
size = 0;
cap = capacity;
}
int get(int key) {
if(mp.count(key) == 0)
return -1;
Info oldInfo = mp[key];
list<pair<int, list<int>>>::iterator old_it_pair = oldInfo.it_pair;
list<int>::iterator old_it_key = oldInfo.it_key;;
old_it_pair->second.erase(old_it_key); // 删除旧的
int newFreqNum = old_it_pair->first + 1; // 新的的频率
list<pair<int, list<int>>>::iterator new_it_pair; // key需要到的新的liFreq位置
if((int)old_it_pair->second.size() == 0)
{
new_it_pair = liFreq.erase(old_it_pair); // 删除该频数
}else{
new_it_pair = std::next(old_it_pair);
}
// 是否需要构建新的频数,然后key总是插入到最后面
if(new_it_pair == liFreq.end() || new_it_pair->first != newFreqNum)
{
// liFreq 没有该新的频数,就构造出来,插入到对应的位置
list<int> li;
li.push_back(key);
pair<int,list<int>> pr(newFreqNum, li);
new_it_pair = liFreq.insert(new_it_pair, pr); // 位置之前插入,并返回插入后,元素所处的位置
}else{
new_it_pair->second.push_back(key);
}
mp[key].it_pair = new_it_pair;
mp[key].it_key = std::prev(new_it_pair->second.end());
return mp[key].val;
}
void put(int key, int value) {
if(cap <= 0)
return;
int storeVal = get(key);
if(storeVal !=-1)
{
mp[key].val = value;
return;
}
if(size == cap)
{
auto it = liFreq.front().second.begin();
int outKey = *it;
mp.erase(outKey);
liFreq.front().second.erase(it); // 删除key
if((int)liFreq.front().second.size() == 0) // 若删除key后 该频数为空了,那么该频数也可以删除掉了
liFreq.erase(liFreq.begin());
size --;
}
size ++;
// insert
if (liFreq.empty() || liFreq.front().first != 1)
{
list<int> li;
li.push_back(key);
pair<int,list<int>> pr(1, li);
liFreq.push_front(pr);
}
else
{
// 最小的频数list中插入一个key, 插入到最后面表示是最近访问到的
liFreq.front().second.push_back(key);
}
Info in;
in.val = value;
in.it_pair = liFreq.begin();
in.it_key = std::prev(liFreq.front().second.end());
mp[key] = in;
}
};

相关文章推荐
- 任意半径中值滤波(扩展至百分比滤波器)O(1)时间复杂度算法的原理、实现及效果。
- 任意半径中值滤波(扩展至百分比滤波器)O(1)时间复杂度算法的原理、实现及效果。
- 排序算法的C语言实现以及各个算法的时间复杂度和空间复杂度分析(冒泡排序)
- 任意半径中值滤波(扩展至百分比滤波器)O(1)时间复杂度算法的原理、实现及效果
- 借鉴快速排序的思想,实现算法将整型数组a[0...n]分成两块,使得第一块元素均大于等于0,第二块的元素均小于0,要求算法原地工作且时间复杂度为O(n)
- 任意半径中值滤波(扩展至百分比滤波器)O(1)时间复杂度算法的原理、实现及效果。
- 每对顶点间的最短路径算法时间复杂度改进C++实现
- 算法导论-最大子数组问题-线性时间复杂度算法分析与实现
- 每对顶点间的最短路径算法时间复杂度改进C++实现
- 已知一个整数数组A[n],写出算法实现将奇数元素放在数组的左边,将偶数放在数组的右边。要求时间复杂度为O(n)。
- 页面置换算法LRU实现--leetcode O(1)时间复杂度
- 算法 插入排序 的 JS实现及时间复杂度分析
- 【算法数据结构Java实现】时间复杂度为O(n)的最大和序列
- 实现数组元素倒序的算法,写出两种实现,时间复杂度为O(n)和O(n/2)
- 常用数据结构2——栈,实现PUSH、POP和取最小值操作算法时间复杂度为o(1)
- java实现时间复杂度O(1)的LFU缓存
- 不要在DEBUG模式下使用STL实现"复杂的"算法
- 一道看上去很吓人的算法面试题:如何对n个数进行排序,要求时间复杂度O(n),空间复杂度O(1)
- 一道看上去很吓人的算法面试题:如何对n个数进行排序,要求时间复杂度O(n),空间复杂度O(1)
- 一道看上去很吓人的算法面试题:如何对n个数进行排序,要求时间复杂度O(n),空间复杂度O(1)