【机器学习】tensorflow:HMM隐状态链的一种最优化求解方法
2017-02-21 10:27
225 查看
隐马尔科夫模型(HMM)有很多讲解,这里我推荐这篇文章:一文搞懂HMM(隐马尔可夫模型)。HMM有三种核心问题:1、给定隐状态链、转移矩阵、发射矩阵,求状态链发生概率2、给定状态链求转移矩阵和发射矩阵3、给定状态链、转移矩阵、发射矩阵,求隐状态链。三类问题分别对应前向-后向算法、最大熵算法、维特比算法。鉴于第三类问题本质上是优化问题,所以我尝试用tensorflow进行求解(网上的tensorflow-hmm实现其实就是把numpy下的维特比算法用tf重写了一遍)。该方法不比维特比算法效率好,不过可以用在更加复杂的概率图模型上。
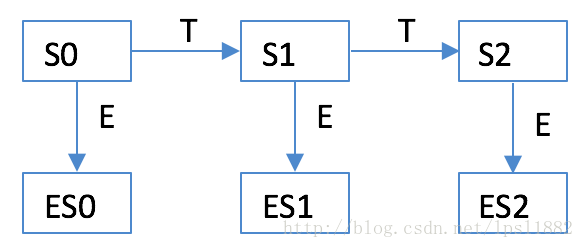
上图是一个简单的HMM。我们的目标是要从表状态链(生活)中找到最可能的隐状态链(天气)。
传统的维特比算法,等价于将HMM展开为概率图,最好的隐状态链就是概率图中的最优路径对应的隐状态链,所以维特比算法思路等价于dijistra最优路径算法。这里要说明几个要点:
- 概率低不代表不发生
- 节点的某个状态概率低,依然可以选择这条路径节点,因为我们求解的是全局最优路径
- 在求解最优隐状态链时,我们实际上给隐状态链加入了一个门阀矩阵Pk,比如选取状态二就是点乘[0,0,1]矩阵
因此,最优路径权重表示为J=∏P(Si|Si−1)PkiEi。为了能够转变为最优化梯度求解问题,我做出模糊/概率化假设:Pk矩阵并不是0、1离散数值构成的矩阵,而是代表为该节点选取某条路径节点,能够帮助获取全局最优概率路径的概率;也可以理解为,某个隐状态不代表不发生,比如某一天可能有时晴天有时雨天,按比率分配,当天的生活也是可能同时发生三种状态,只不过我们容易看到某种状态而已。也就是说,维特比算法准确给出了如何选择路径,这里给出了选择路径的概率。
tensorflow代码如下:
我们将每个状态的概率点乘目标表状态链矩阵,得到真实权重,然后最大化所有权重,求解得到state0,1,2概率为:
[[ 0. 1.]]
[[ 1. 0.]]
[[ 1. 0.]]
也就是sunny,rainy,rainy
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}上图是一个简单的HMM。我们的目标是要从表状态链(生活)中找到最可能的隐状态链(天气)。
传统的维特比算法,等价于将HMM展开为概率图,最好的隐状态链就是概率图中的最优路径对应的隐状态链,所以维特比算法思路等价于dijistra最优路径算法。这里要说明几个要点:
- 概率低不代表不发生
- 节点的某个状态概率低,依然可以选择这条路径节点,因为我们求解的是全局最优路径
- 在求解最优隐状态链时,我们实际上给隐状态链加入了一个门阀矩阵Pk,比如选取状态二就是点乘[0,0,1]矩阵
因此,最优路径权重表示为J=∏P(Si|Si−1)PkiEi。为了能够转变为最优化梯度求解问题,我做出模糊/概率化假设:Pk矩阵并不是0、1离散数值构成的矩阵,而是代表为该节点选取某条路径节点,能够帮助获取全局最优概率路径的概率;也可以理解为,某个隐状态不代表不发生,比如某一天可能有时晴天有时雨天,按比率分配,当天的生活也是可能同时发生三种状态,只不过我们容易看到某种状态而已。也就是说,维特比算法准确给出了如何选择路径,这里给出了选择路径的概率。
tensorflow代码如下:
stateNum = 2
estateNum = 3
p0=np.mat([0.6,0.4])
T = np.mat([[0.7,0.3],[0.4,0.6]])
E = np.mat([[0.1,0.4,0.5],[0.6,0.3,0.1]])
obchain = np.array([0,1,2])
y_=np.zeros([obchain.shape[0],estateNum],np.int)
for i in range(0,obchain.shape[0]):
y_[obchain[i],i] = 1
with tf.device('/cpu:0'):
with tf.variable_scope("zh", reuse=None):
start = tf.placeholder('float',p0.shape)
tT = tf.placeholder('float',T.shape)
tE = tf.placeholder('float',E.shape)
y0 = tf.placeholder('float',[1,estateNum])
y1 = tf.placeholder('float',[1,estateNum])
y2 = tf.placeholder('float',[1,estateNum])
state = []
estate = []
pick0 = tf.get_variable(initializer=tf.ones([1,stateNum])/stateNum,name='pick0')
state0 = tf.multiply(start,pick0)#tf.get_variable(initializer=tf.ones([1,stateNum])/stateNum,name='state0')
state0 = tf.minimum(tf.maximum(state0,0.0),1.)
state0 /= tf.reduce_sum(state0)
estate0 = tf.matmul(state0,tE)
pick1 = tf.get_variable(initializer=tf.ones([1,stateNum])/stateNum,name='pick1')
state1 = tf.multiply(tf.matmul(state0,tT),pick1)
state1 = tf.minimum(tf.maximum(state1,0.0),1.)
state1 /= tf.reduce_sum(state1)
estate1 = tf.matmul(state1,tE)
pick2 = tf.get_variable(initializer=tf.ones([1,stateNum])/stateNum,name='pick2')
state2 = tf.multiply(tf.matmul(state1,tT),pick2)
state2 = tf.minimum(tf.maximum(state2,0.0),1.)
state2 /= tf.reduce_sum(state2)
estate2 = tf.matmul(state2,tE)
loss = tf.reduce_sum(tf.multiply(estate0,y0))
loss *= tf.reduce_sum(tf.multiply(estate1,y1))
loss *= tf.reduce_sum(tf.multiply(estate2,y2))
loss *= -1.
global_step = tf.Variable(0, name = 'global_step',trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,500, 0.95, staircase=True)
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss=loss,global_step = global_step)我们将每个状态的概率点乘目标表状态链矩阵,得到真实权重,然后最大化所有权重,求解得到state0,1,2概率为:
[[ 0. 1.]]
[[ 1. 0.]]
[[ 1. 0.]]
也就是sunny,rainy,rainy

相关文章推荐
- 基于机器学习的web异常检测——基于HMM的状态序列建模,将原始数据转化为状态机表示,然后求解概率判断异常与否
- 用tensorflow求解吴恩达的机器学习练习题(ex1)
- 机器学习中导数最优化方法(基础篇)
- JD 1147:Jugs(一种用最少步骤求解的方法)
- .NET2.0 一种简单的窗口控件UI状态控制方法
- 机器学习中常见的几种最优化方法
- 机器学习中的最优化方法进阶
- 一种高性能与高可用的流媒体系统之媒体流状态管理方法
- 白话机器学习-最优化方法-梯度下降法
- 机器学习(四)正规方程求解线性回归问题、正规方法与梯度法的优劣
- 【笔记】人工智能 一种现代方法 人工智能 一种现代方法 第6章 用搜索树对问题求解
- .NET20 一种简单的窗口控件UI状态控制方法
- 求解无约束最优化问题方法
- .NET20 一种简单的窗口控件UI状态控制方法
- 深度学习和机器学习最优化方法总结
- 机器学习之导数最优化方法
- 【转】机器学习中导数最优化方法(基础篇)
- [置顶] 概率统计与机器学习:机器学习的各类型最优化方法
- 机器学习练习记录(3):HMM中,如果已知观察序列和产生观察序列的状态序列,如何直接进行参数估计?
- 【tensorflow】通过机器学习求解二元一次方程的参数