CS231n课程笔记5.1:神经网络历史&激活函数比较
2016-12-24 16:43
465 查看
CS231n简介
详见 CS231n课程笔记1:Introduction。注:斜体字用于注明作者自己的思考,正确性未经过验证,欢迎指教。
课程笔记
关于神经网络的简介请参考 CS231n课程笔记4.2:神经网络结构。1. 神经网络历史
具有神经网络的结构,但是使用电门手动构造函数。[Frank Rosenblatt, ~1957: Perceptron;Widrow and Hoff, ~1960: Adaline/Madaline]BP出现 [Rumelhart et al. 1986: First time back-propagation became popular]
可以训练深层神经网络[Hinton and Salakhutdinov 2006]
再度复兴,可以得到很好的成果[George Dahl, Dong Yu, Li Deng, Alex Acero, 2010;Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, 2012]
2. 激活函数的选择
激活函数是作用于线性函数之后的非线性函数,使得模型具有非线性区分能力。常见的激活函数如下图: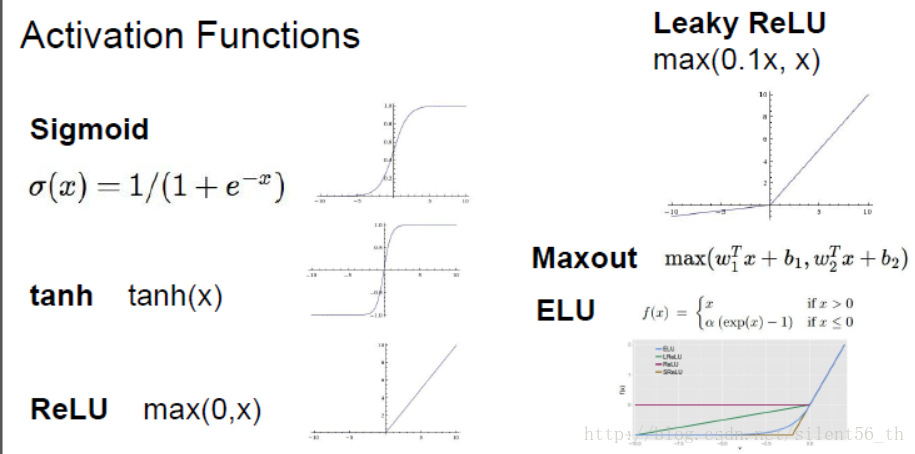
衡量激活函数通常有三个方向的考量:是否会有效地传播gradient;是否是均值为0;计算消耗是否很大。
1. 传播gradient的部分的考量是为了让模型可以快速有效地收敛。
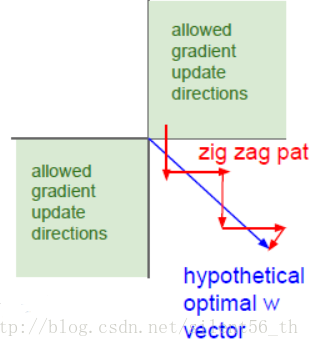
2. 数据集均值为0同样是处于收敛的考虑。这部分课程中没有详细解释,举了个特例,然后说有相关论文证明均值为0有助于收敛。如下图所示,假设所有的输入都大于0,那么考虑从激活函数传回线性函数中的权重的gradient,必然只能位于一三象限(如果是二维的话),那么如果理想的方向位于第二象限的话,则需要之字形前行,收敛变慢。
2.1. sigmoid函数
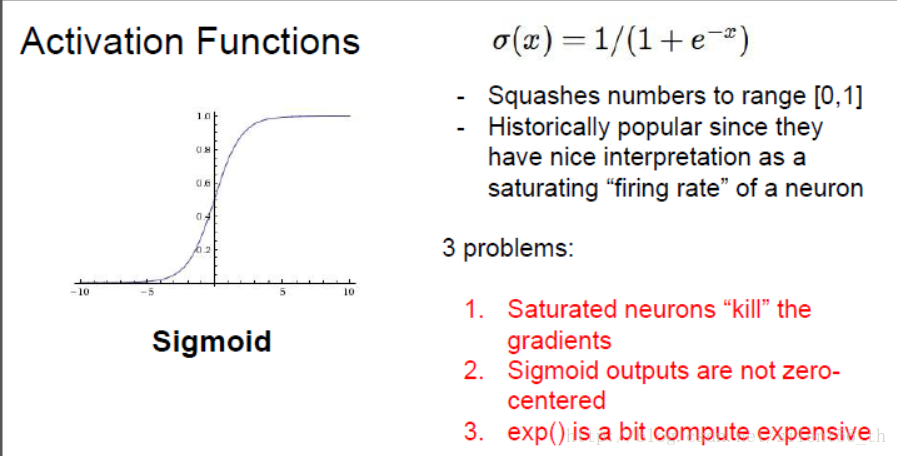
曾经很火的激活函数,易求导,可解释。但是有很多缺点:对于y接近1以及0的部分,导数几乎为0,所以BP的时候基本不会传播gradient;不是zero mean的,指数函数计算代价高。
2.2. tanh 函数
此函数被yann lecun于1991年提出,认为比sigmoid要好。从上诉衡量标准可以看出,tanh具有所有sigmoid的优势以及缺点,除了其是zero mean的。所以是在这种评价体系中明显优于sigmoid。
2.3. ReLU函数
函数非常简单,如下图所示,基本就是对于小于0的部分截断,但是具有很多优良的性质,是现在神经网络的默认激活函数,最开始出现于[Krizhevsky et al., 2012]。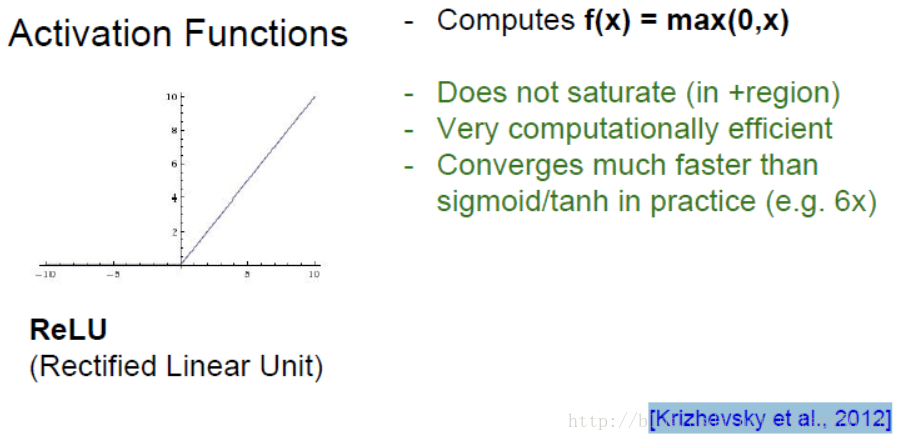
其在大于0的部分直接传回gradient;计算代价很小;实际中收敛速度很快。但是均值不是0;0的部分无法计算梯度;对于小于0的部分直接kill gradient。如果初始化或者训练过程中,某次的权重恰好使得输出都为0,即无法传回gradient,那么此次优化就会停止在非最优点无法收敛,如下图所示。
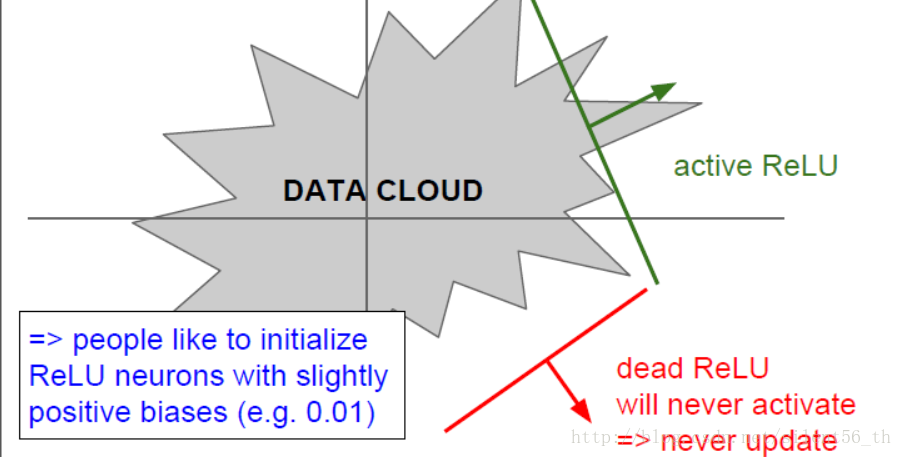
2.4. ReLU的变种
如上所述,ReLU具有令人难以拒绝的优良性质,但有一些缺点;所以有一些变种用于保留优点,同时修补一些缺点(不收敛)。Leaky ReLU、Parametric ReLU以及如下图所示:

Leaky ReLU用于简单修补ReLU不会收敛的缺点,对于小于0的部分,传回0.01*gradient。
而Parametric ReLU则是用于修补Leaky ReLU中简单实用0.01倍数的缺点,用一个参数替代,注意这个参数不是超参数,是需要在BP中修正的。
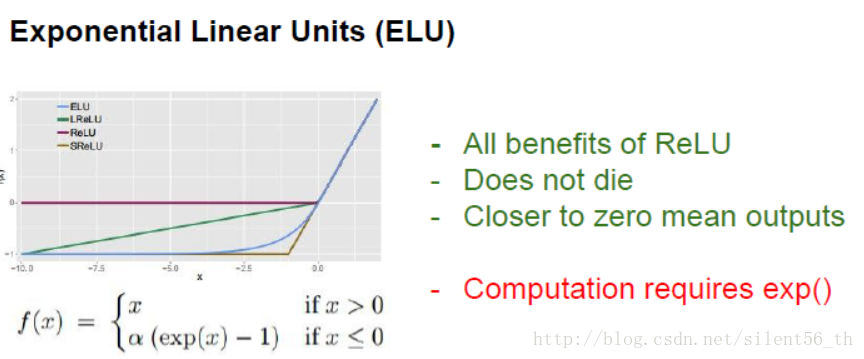
ELU则进一步修正ReLU中非zero mean的缺点,它可以证明的预期输出zero mean的数据,但是因为使用了指数函数,计算代价比ReLU要高。
还有一个maxout neuron如下图所示,也是属于ReLU的变种,但变化较大,非线性能力也很强,但是对于整个模型来说参数加倍,并不是很常用。

2.5. 实际使用的建议
默认使用ReLU,可以试一试ReLU的变种,可以尝试tanh但是不要期待过多,永远不要用sigmoid。

相关文章推荐
- cs231n笔记(5)--传统神经网络,激活函数
- 【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数
- 【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数
- 【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数
- CS231n课程笔记翻译:神经网络笔记1(下)
- CS231n课程笔记翻译7:神经网络笔记 part2
- CS231n课程笔记翻译:神经网络笔记3(上)
- CS231n课程笔记翻译:神经网络笔记2
- CS231n课程笔记4.2:神经网络结构
- CS231n课程笔记翻译(十):神经网络笔记1(上)
- 机器学习笔记:形象的解释神经网络激活函数的作用是什么?
- [DeeplearningAI笔记]神经网络与深度学习3.2_3.11(激活函数)浅层神经网络
- CS231n课程笔记6.2:神经网络训练技巧之Ensemble、Dropout
- cs231n 卷积神经网络与计算机视觉 5 神经网络基本结构 激活函数总结
- 神经网络中各种激活函数比较
- 课程笔记之六:神经网络的代价函数和误差反向传播算法
- CS231n课程笔记翻译6:神经网络笔记 part1
- CS231n课程笔记翻译:神经网络笔记3
- 神经网络中激活函数比较
- CS231n课程笔记翻译:神经网络笔记1(上)