神经网络中各种激活函数比较
2017-08-13 14:05
351 查看
ReLU 激活函数:
ReLu使得网络可以自行引入稀疏性,在没做预训练情况下,以ReLu为激活的网络性能优于其它激活函数。数学表达式: $y = max(0,x)$
第一,sigmoid的导数只有在0附近的时候有比较好的激活性,在正负饱和区的梯度都接近于0,所以这会造成梯度弥散,而relu函数在大于0的部分梯度为常数,所以不会产生梯度弥散现象。第二,relu函数在负半区的导数为0 ,所以一旦神经元激活值进入负半区,那么梯度就会为0,也就是说这个神经元不会经历训练,即所谓的稀疏性。第三,relu函数的导数计算更快,程序实现就是一个if-else语句,而sigmoid函数要进行浮点四则运算。
ReLU 的缺点是,它在训练时比较脆弱并且可能“死掉”。
举例来说:一个非常大的梯度经过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0。
也就是说,这个 ReLU 单元在训练中将不可逆转的死亡,导致了数据多样化的丢失。实际中,如果学习率设置得太高,可能会发现网络中 40% 的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。
合理设置学习率,会降低这种情况的发生概率。
Leaky ReLU 是为解决“ ReLU 死亡”问题的尝试。
ReLU 中当 x<0 时,函数值为 0。而 Leaky ReLU 则是给出一个很小的梯度值,比如 0.01。
maxout: https://arxiv.org/pdf/1302.4389.pdf
Maxout 具有 ReLU 的优点(如:计算简单,不会 梯度饱和),同时又没有 ReLU 的一些缺点 (如:容易 go die)。不过呢,还是有一些缺点的嘛:就是把参数double了。
Sigmoid 激活函数:
sigmoid 激活函数在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。数学表达式: $y = (1 + exp(-x))^{-1}$
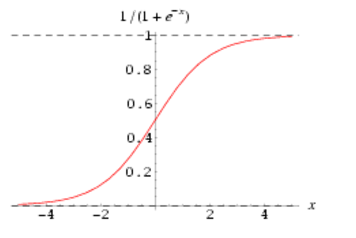
缺点:
激活函数计算量大,反向传播求误差梯度时,求导涉及除法
反向传播时,很容易就会出现梯度消失或梯度爆炸的情况,从而无法完成深层网络的训练
梯度消失或梯度爆炸的原因:
以下图的反向传播为例(假设每一层只有一个神经元且对于每一层
,其中
为sigmoid函数)

可以推导出
的最大值为
,而我们初始化的网络权值
通常都小于1,因此
,因此对于上面的链式求导,层数越多,求导结果
越小,因而导致梯度消失的情况出现。
这样,梯度爆炸问题的出现原因就显而易见了,即
,也就是
比较大的情况。但对于使用sigmoid激活函数来说,这种情况比较少。因为
的大小也与
有关(
),除非该层的输入值
在一直一个比较小的范围内。
其实梯度爆炸和梯度消失问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应(导数的链式求导法则)。对于更普遍的梯度消失问题,可以考虑用ReLU激活函数取代sigmoid激活函数。另外,LSTM的结构设计也可以改善RNN中的梯度消失问题。
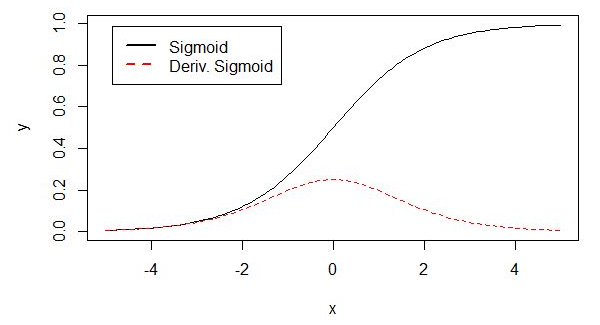
Tanh 激活函数:
Tanh 激活函数使得输出与输入的关系能保持非线性单调上升和下降关系,比sigmoid 函数延迟了饱和期(即导数接近0),对神经网路的容错性好。数学表达式:
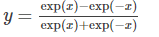


相关文章推荐
- 对不同激活函数在神经网络中的比较分析
- 神经网络中激活函数比较
- 神经网络不同激活函数比较--读《Understanding the difficulty of training deep feedforward neural networks》
- 神经网络激活函数比较
- CS231n课程笔记5.1:神经网络历史&激活函数比较
- 神经网络中的激活函数
- 神经网络基础之激活函数
- 神经网络之激活函数(Activation Function)(附maxout)
- 神经网络之激活函数(Activation Function)
- 深度学习中的数学与技巧(13):神经网络之激活函数
- 深度学习:神经网络中的激活函数
- 神经网络之激活函数(Activation Function)
- 20171115-神经网络激活函数
- 通俗理解神经网络中激活函数作用
- 不同的神经网络训练函数training function的比较
- 神经网络中的激活函数
- 神经网络之激活函数(activation function)
- 【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数
- 形象的解释神经网络激活函数的作用
- 神经网络激活函数面面观