pt-online-schema-change使用说明、限制与比较
2016-12-18 10:53
387 查看
如果正在看这篇文章,相信你已经知道自己的需求了。
在 mysql 5.5 版本以前,修改表结构如添加索引、修改列,需要锁表,期间不能写入,对于大表这简直是灾难。从5.5特别是5.6里,情况有了好转,支持Online DDL,相关介绍见 这篇文章,而我在实际alter table过程中还是会引起 data meta lock 问题。pt-online-schema-change是Percona-toolkit一员,通过改进原生ddl的方式,达到不锁表在线修改表结构。
在新表执行alter table 语句(速度应该很快)
在原表中创建触发器3个触发器分别对应insert,update,delete操作
以一定块大小从原表拷贝数据到临时表,拷贝过程中通过原表上的触发器在原表进行的写操作都会更新到新建的临时表
Rename 原表到old表中,在把临时表Rename为原表
如果有参考该表的外键,根据alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理
默认最后将旧原表删除
连接实例信息,缩写
结构变更语句,不需要
绝大部分情况下表上需要有主键或唯一索引,因为工具在运行当中为了保证新表也是最新的,需要旧表上创建 DELETE和UPDATE 触发器,同步到新表的时候有主键会更快。个别情况是,当alter操作就是在c1列上建立主键时,DELETE触发器将基于c1列。
子句不支持 rename 去给表重命名。
alter命令原表就不支持给索引重命名,需要先drop再add,在pt-osc也一样。(mysql 5.7 支持 RENAME INDEX old_index_name TO new_index_name)
但给字段重命名,千万不要drop-add,整列数据会丢失,使用
子句如果是add column并且定义了not null,那么必须指定default值,否则会失败。
如果要删除外键(名 fk_foo),使用工具的时候外键名要加下划线,比如
指定要ddl的数据库名和表名
默认为
因为拷贝行有可能会给部分行上锁,Threads_running 是判断当前数据库负载的绝佳指标。
默认1s。每个chunk拷贝完成后,会查看所有复制Slave的延迟情况(
熟悉percona-toolkit的人都知道
默认0.5s,即拷贝数据行的时候,为了尽量保证0.5s内拷完一个chunk,动态调整chunk-size的大小,以适应服务器性能的变化。
也可以通过另外一个选项
使用pt-osc进行ddl要开一个session去操作,
因为使用pt-osc之后ddl的速度会变慢,所以预计2.5h只能还不能改完,记得加大
创建和修改新表,但不会创建触发器、复制数据、和替换原表。并不真正执行,可以看到生成的执行语句,了解其执行步骤与细节,和
确定修改表,则指定该参数。真正执行alter。–dry-run与–execute必须指定一个,二者相互排斥
所以如果要让它支持有触发器存在的表也是可以实现的,思路就是:先找到原表触发器定义;重写原表触发器;最后阶段将原表触发器定义应用到新表。
在原表上update,新临时表上是replace into整行数据,所以达到有则更新,无则插入。同时配合后面的 insert ignore,保证这条数据不会因为重复而失败。
这里的外键不是看t1上是否存在外键,而是作为子表的 t2。主要问题在 rename t1 时,t1“不存在”导致t2的外键认为参考失败,不允许rename。
pt-osc提供
它先通过 alter table t2 drop fk1,add _fk1 重建外键参考,指向新表
再 rename t1 t1_old, _t1_new t1 ,交换表名,不影响客户端
删除旧表 t1_old
但如果字表t2太大,以致alter操作可能耗时过长,有可能会强制选择 drop_swap。
涉及的主要方法在
禁用t2表外键约束检查
然后 drop t1 原表
再 rename _t1_new t1
这种方式速度更快,也不会阻塞请求。但有风险,第一,drop表的瞬间到rename过程,原表t1是不存在的,遇到请求会报错;第二,如果因为bug或某种原因,旧表已删,新表rename失败,那就太晚了,但这种情况很少见。
我们的开发规范决定,即使表间存在外键参考关系,也不通过表定义强制约束。
而且在 Row Based Replication 下,还会写一份binlog。不要想当然使用
pt-osc工具在存在触发器时,不适用
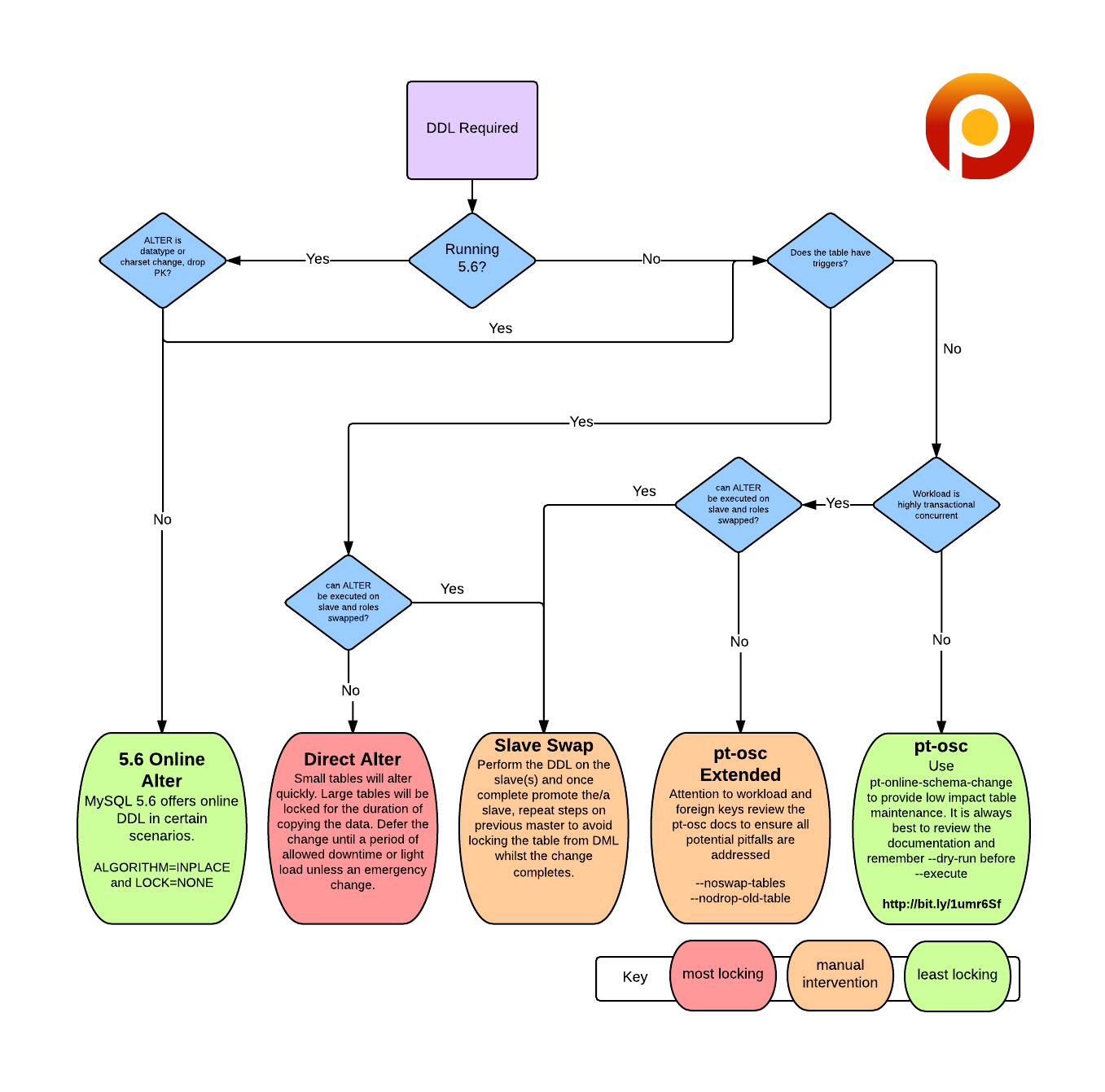
修改索引、外键、列名时,优先采用online ddl,并指定 ALGORITHM=INPLACE
其它情况使用pt-osc,虽然存在copy data
pt-osc比online ddl要慢一倍左右,因为它是根据负载调整的
无论哪种方式都选择的业务低峰期执行
特殊情况需要利用主从特性,先alter从库,主备切换,再改原主库
借助percona博客一张图说明一下:
完整输出过程
修改列类型
添加删除索引
放后台执行
修改主键
在我的环境里有不少表设计之初没有自增id,而是采用复合主键,pt-osc 对删除、添加主键会特殊处理,详见 这里。
表上存在触发器,不适用。
2. no-version-check
这个错误在阿里云RDS上执行时出现的,我以为是我哪里语法写错了,但拿到原生5.6的版本上就没问题了,加上
RDS MySQL 如何使用 Percona Toolkit
percona-toolkit 之 【pt-online-schema-change】说明
Avoiding MySQL ALTER table downtime
MySQL Online DDL和NoSQL Schemaless Design
原文链接地址:http://seanlook.com/2016/05/27/mysql-pt-online-schema-change/
在 mysql 5.5 版本以前,修改表结构如添加索引、修改列,需要锁表,期间不能写入,对于大表这简直是灾难。从5.5特别是5.6里,情况有了好转,支持Online DDL,相关介绍见 这篇文章,而我在实际alter table过程中还是会引起 data meta lock 问题。pt-online-schema-change是Percona-toolkit一员,通过改进原生ddl的方式,达到不锁表在线修改表结构。
1. pt-osc工作过程
创建一个和要执行 alter 操作的表一样的新的空表结构(是alter之前的结构)在新表执行alter table 语句(速度应该很快)
在原表中创建触发器3个触发器分别对应insert,update,delete操作
以一定块大小从原表拷贝数据到临时表,拷贝过程中通过原表上的触发器在原表进行的写操作都会更新到新建的临时表
Rename 原表到old表中,在把临时表Rename为原表
如果有参考该表的外键,根据alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理
默认最后将旧原表删除
2. 常用选项说明
只介绍部分常用的选项--host=xxx --user=xxx --password=xxx
连接实例信息,缩写
-h xxx -u xxx -p xxx,密码可以使用参数
--ask-pass手动输入。
--alter
结构变更语句,不需要
ALTER TABLE关键字。与原始ddl一样可以指定多个更改,用逗号分隔。
绝大部分情况下表上需要有主键或唯一索引,因为工具在运行当中为了保证新表也是最新的,需要旧表上创建 DELETE和UPDATE 触发器,同步到新表的时候有主键会更快。个别情况是,当alter操作就是在c1列上建立主键时,DELETE触发器将基于c1列。
子句不支持 rename 去给表重命名。
alter命令原表就不支持给索引重命名,需要先drop再add,在pt-osc也一样。(mysql 5.7 支持 RENAME INDEX old_index_name TO new_index_name)
但给字段重命名,千万不要drop-add,整列数据会丢失,使用
change col1 col1_new type constraint(保持类型和约束一致,否则相当于修改 column type,不能online)
子句如果是add column并且定义了not null,那么必须指定default值,否则会失败。
如果要删除外键(名 fk_foo),使用工具的时候外键名要加下划线,比如
--alter "DROP FOREIGN KEY _fk_foo"
D=db_name,t=table_name
指定要ddl的数据库名和表名
--max-load
默认为
Threads_running=25。每个chunk拷贝完后,会检查 SHOW GLOBAL STATUS 的内容,检查指标是否超过了指定的阈值。如果超过,则先暂停。这里可以用逗号分隔,指定多个条件,每个条件格式:
status指标=MAX_VALUE或者
status指标:MAX_VALUE。如果不指定MAX_VALUE,那么工具会这只其为当前值的120%。
因为拷贝行有可能会给部分行上锁,Threads_running 是判断当前数据库负载的绝佳指标。
--max-lag
默认1s。每个chunk拷贝完成后,会查看所有复制Slave的延迟情况(
Seconds_Behind_Master)。要是延迟大于该值,则暂停复制数据,直到所有从的滞后小于这个值。
--check-interval配合使用,指定出现从库滞后超过 max-lag,则该工具将睡眠多长时间,默认1s,再检查。如
--max-lag=5 --check-interval=2。
熟悉percona-toolkit的人都知道
--recursion-method可以用来指定从库dsn记录。另外,如果从库被停止,将会永远等待,直到从开始同步,并且延迟小于该值。
--chunk-time
默认0.5s,即拷贝数据行的时候,为了尽量保证0.5s内拷完一个chunk,动态调整chunk-size的大小,以适应服务器性能的变化。
也可以通过另外一个选项
--chunk-size禁止动态调整,即每次固定拷贝 1k 行,如果指定则默认1000行,且比 chunk-time 优先生效
--set-vars
使用pt-osc进行ddl要开一个session去操作,
set-vars可以在执行alter之前设定这些变量,比如默认会设置
--set-vars "wait_timeout=10000,innodb_lock_wait_timeout=1,lock_wait_timeout=60"。
因为使用pt-osc之后ddl的速度会变慢,所以预计2.5h只能还不能改完,记得加大
wait_timeout。
--dry-run
创建和修改新表,但不会创建触发器、复制数据、和替换原表。并不真正执行,可以看到生成的执行语句,了解其执行步骤与细节,和
--execute
确定修改表,则指定该参数。真正执行alter。–dry-run与–execute必须指定一个,二者相互排斥
3. 使用疑惑(限制)
3.1 原表上不能有触发器存在
这个很容易理解,pt-osc会在原表上创建3个触发器,而一个表上不能同时有2个相同类型的触发器,为简单通用起见,只能一棍子打死。所以如果要让它支持有触发器存在的表也是可以实现的,思路就是:先找到原表触发器定义;重写原表触发器;最后阶段将原表触发器定义应用到新表。
3.2 通过触发器写数据到临时新表,会不会出现数据不一致或异常
这其实是我的一个顾虑,因为如果update t1,触发update t2,但这条数据还没copy到t2,不就有异常了吗?后台通过打开general_log,看到它创建的触发器:| 1 2 3 4 5 6 7 8 9 10 11 12 | 6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_del` AFTER DELETE ON `confluence`.`sbtest3` FOR EACH ROW DELETE IGNORE FROM `confluence`.`_sbtest3_new` WHERE `confluence`.`_sbtest3_new`.`id` <=> OLD.`id` 6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_upd` AFTER UPDATE ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`) 6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_ins` AFTER INSERT ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`) 并且copy操作是: 6165 Query INSERT LOW_PRIORITY IGNORE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) SELECT `id`, `k`, `c`, `pad` FROM `confluence`.`sbtest3` FORCE INDEX(`PRIMARY`) WHERE ((`id` >= '4692805')) AND ((`id` <= '4718680')) LOCK IN SHARE MODE /*pt-online-schema-change 46459 copy nibble*/ |
3.3 为什么外键那么特殊
假设 t1 是要修改的表,t2 有外键依赖于 t1,_t1_new 是 alter t1 产生的新临时表。这里的外键不是看t1上是否存在外键,而是作为子表的 t2。主要问题在 rename t1 时,t1“不存在”导致t2的外键认为参考失败,不允许rename。
pt-osc提供
--alter-foreign-keys-method选项来决定怎么处理这种情况:
rebuild_constraints,优先采用这种方式
它先通过 alter table t2 drop fk1,add _fk1 重建外键参考,指向新表
再 rename t1 t1_old, _t1_new t1 ,交换表名,不影响客户端
删除旧表 t1_old
但如果字表t2太大,以致alter操作可能耗时过长,有可能会强制选择 drop_swap。
涉及的主要方法在
pt-online-schema-change文件的 determine_alter_fk_method, rebuild_constraints,swap_tables三个函数中。
drop_swap,
禁用t2表外键约束检查
FOREIGN_KEY_CHECKS=0
然后 drop t1 原表
再 rename _t1_new t1
这种方式速度更快,也不会阻塞请求。但有风险,第一,drop表的瞬间到rename过程,原表t1是不存在的,遇到请求会报错;第二,如果因为bug或某种原因,旧表已删,新表rename失败,那就太晚了,但这种情况很少见。
我们的开发规范决定,即使表间存在外键参考关系,也不通过表定义强制约束。
3.4 在使用之前需要对磁盘容量进行评估
使用OSC会使增加一倍的空间,包括索引而且在 Row Based Replication 下,还会写一份binlog。不要想当然使用
--set-vars去设置 sql_log_bin=0,因为在这个session级别,alter语句也要在从库上执行,除非你对从库另有打算。
4. 使用 pt-osc原生 5.6 online ddl相比,如何选择
online ddl在必须copy table时成本较高,不宜采用pt-osc工具在存在触发器时,不适用
修改索引、外键、列名时,优先采用online ddl,并指定 ALGORITHM=INPLACE
其它情况使用pt-osc,虽然存在copy data
pt-osc比online ddl要慢一倍左右,因为它是根据负载调整的
无论哪种方式都选择的业务低峰期执行
特殊情况需要利用主从特性,先alter从库,主备切换,再改原主库
借助percona博客一张图说明一下:

5. 示例
添加新列完整输出过程
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | [root@ssd- 34 sysbench]# pt-online-schema-change --user=user --password=password --host=10.0.201.34 --alter "ADD COLUMN f_id int default 0" D=confluence,t=sbtest3 --print --execute No slaves found. See --recursion-method if host ssd-34 has slaves. Not checking slave lag because no slaves were found and --check-slave-lag was not specified. Operation, tries, wait: analyze_table, 10, 1 copy_rows, 10, 0.25 create_triggers, 10, 1 drop_triggers, 10, 1 swap_tables, 10, 1 update_foreign_keys, 10, 1 Altering `confluence`.`sbtest3`... Creating new table... ==> 创建新表 CREATE TABLE `confluence`.`_sbtest3_new` ( `id` int( 10) unsigned NOT NULL AUTO_INCREMENT, `k` int( 10) unsigned NOT NULL DEFAULT '0', `c` char( 120) COLLATE utf8_bin NOT NULL DEFAULT '', `pad` char( 60) COLLATE utf8_bin NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_3` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT= 5000001 DEFAULT CHARSET=utf8 COLLATE=utf8_bin MAX_ROWS=1000000 Created new table confluence._sbtest3_new OK. Altering new table... ==> 使用ddl修改新表结构 ALTER TABLE `confluence`.`_sbtest3_new` ADD COLUMN f_id int default 0 Altered `confluence`.`_sbtest3_new` OK. 2016-05-24T20:54:23 Creating triggers... ==> 在旧表上创建3个触发器 CREATE TRIGGER `pt_osc_confluence_sbtest3_del` AFTER DELETE ON `confluence`.`sbtest3` FOR EACH ROW DELETE IGNORE FROM `confluence`.`_sbtest3_new` WHERE `confluence`.`_sbtest3_new`.`id` <=> OLD.`id` CREATE TRIGGER `pt_osc_confluence_sbtest3_upd` AFTER UPDATE ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`) CREATE TRIGGER `pt_osc_confluence_sbtest3_ins` AFTER INSERT ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`) 2016-05-24T20:54:23 Created triggers OK. 2016-05-24T20:54:23 Copying approximately 4485573 rows... ==> 分块拷贝数据到新表 INSERT LOW_PRIORITY IGNORE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) SELECT `id`, `k`, `c`, `pad` FROM `confluence`.`sbtest3` FORCE INDEX(`PRIMARY`) WHERE ((`id` >= ?)) AND ((`id` <= ?)) LOCK IN SHARE MODE /*pt-online-schema-change 44155 copy nibble*/ SELECT /*! 40001 SQL_NO_CACHE */ `id` FROM `confluence`.`sbtest3` FORCE INDEX(`PRIMARY`) WHERE ((`id` >= ?)) ORDER BY `id` LIMIT ?, 2 /*next chunk boundary*/ Copying `confluence`.`sbtest3`: 36% 00:52 remain Copying `confluence`.`sbtest3`: 69% 00:26 remain 2016-05-24T20:56:01 Copied rows OK. 2016-05-24T20:56:01 Analyzing new table... 2016-05-24T20:56:01 Swapping tables... ==> 交换新旧表 RENAME TABLE `confluence`.`sbtest3` TO `confluence`.`_sbtest3_old`, `confluence`.`_sbtest3_new` TO `confluence`.`sbtest3` 2016-05-24T20:56:01 Swapped original and new tables OK. 2016-05-24T20:56:01 Dropping old table... ==> 删除旧表 DROP TABLE IF EXISTS `confluence`.`_sbtest3_old` 2016-05-24T20:56:02 Dropped old table `confluence`.`_sbtest3_old` OK. 2016-05-24T20:56:02 Dropping triggers... DROP TRIGGER IF EXISTS `confluence`.`pt_osc_confluence_sbtest3_del`; DROP TRIGGER IF EXISTS `confluence`.`pt_osc_confluence_sbtest3_upd`; DROP TRIGGER IF EXISTS `confluence`.`pt_osc_confluence_sbtest3_ins`; 2016-05-24T20:56:02 Dropped triggers OK. Successfully altered `confluence`.`sbtest3`. |
| 1 2 3 4 5 6 7 | pt-online-schema-change h=10.0.201.34,P=3306,u=jacky,p=xxx,D=confluence,t=sbtest3 \ - -alter "CHANGE pad f_pad varchar(60) NOT NULL DEFAULT '' " \ - -print --dry-run pt-online-schema-change -ujacky -p xxx -h "10.0.201.34" D=confluence,t=sbtest3 \ - -alter "CHANGE pad f_pad varchar(60) NOT NULL DEFAULT '' " \ - -execute |
放后台执行
| 1 2 3 | pt-online-schema-change --user=user --ask-pass --host=10.0.201.34 \ --alter "DROP KEY cid, ADD KEY idx_corpid_userid(f_corp_id,f_user_id) " \ D=confluence,t=sbtest3 --print --execute |
在我的环境里有不少表设计之初没有自增id,而是采用复合主键,pt-osc 对删除、添加主键会特殊处理,详见 这里。
6. 错误处理
1. 存在trigger| 1 2 3 | [zx@mysql-5 ~]$ pt-online-schema- change -u user -p password -h 10.0.200.195 \ --alter="MODIFY COLUMN f_receiver varchar(128) NOT NULL DEFAULT '' AFTER f_user_id" --dry-run D=db_name,t=table_name The table `db_name`.`table_name` has triggers. This tool needs to create its own triggers, so the table cannot already have triggers. |
2. no-version-check
| 1 2 3 | $ pt-online-schema-change -uuser -ppassword --alter "add key id_provice(f_provice)" \ D=db_name,t=tb_name -h rdsxxxxxx.mysql.rds.aliyuncs.com Can't use an undefined value as an ARRAY reference at /usr/bin/pt-online-schema-change line 7335. |
--no-version-check选项就好了,见 https://help.aliyun.com/knowledge_detail/13098164.html ,没深究,应该是pt去验证mysql server版本的时候从rds拿到的信息不对,导致格式出错。
参考
refman pt-online-schema-changeRDS MySQL 如何使用 Percona Toolkit
percona-toolkit 之 【pt-online-schema-change】说明
Avoiding MySQL ALTER table downtime
MySQL Online DDL和NoSQL Schemaless Design
原文链接地址:http://seanlook.com/2016/05/27/mysql-pt-online-schema-change/

相关文章推荐
- pt-online-schema-change使用说明、限制与比较
- pt-online-schema-change使用说明、限制与比较
- pt-online-schema-change使用说明、限制与比较
- pt-online-schema-change使用说明、限制与比较
- pt-online-schema-change 使用介绍
- MySQL使用pt-online-change-schema工具在线修改1.6亿级数据表结构
- 使用 pt-online-schema-change 修改大表时异常退出 Exiting on SIGHUP 的问题
- percona-toolkit 之 【pt-online-schema-change】说明
- 使用 pt-online-schema-change 实现在线DDL
- percona-toolkit 之 【pt-online-schema-change】说明
- 使用pt-online-schema-change 修复主从数据表数据不一致
- Percona Toolkit 使用(五)(pt-online-schema-change)
- pt-online-schema-change的原理解析与应用说明
- pt-online-schema-change使用中的不当,引起的数据库不可写入问题
- pt-online-schema-change使用
- 在线更改表字段工具比较 pt-online-schema-change VS oak-online-alter-table
- pt-online-schema-change 工具使用
- 热修改mysql数据库pt-online-schema-change 的使用详解
- pt-online-schema-change原理及使用方法
- percona-toolkit 之 【pt-online-schema-change】说明