标准化,归一化和正则化
2016-12-04 20:24
134 查看
0.参考文献
关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化2017.6.3更新:
数据标准化/归一化normalization
归一化与标准化
1.标准化
用的最多的是 z-score标准化公式为 (X - mean)/ std
计算时对每个属性(每列)分别进行。
将数据按其属性(一般是按列)减去其均值,并除以其标准差,得到的结果是,对每个属性来说,所有数据都聚集在0附近,方差为1.
实现方式:
1. 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
from sklearn import preprocessing import numpy as np X=np.array([[1,-1,2], [2,0,0], [0,1,-1]]) X_scaled = preprocessing.scale(X) >>>X_scaled array([[0. ...,-1.22...,1.33...], [ 1.22..., 0. ..., -0.26...], [-1.22..., 1.22..., -1.06...]]) 处理后的均值和方差: X_scaled.mean(axis=0) array([0,0,0]) X_scaled.std(axis=0) array([1,1,1])
2.
使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
>>>scaler = preprocessing.StandardScaler().fit(X) >>>scaler StandardScaler(copy=True,with_mean=True,with_std=True) >>>scaler.mean_ >array([1,0,0.33]) >>>scaler.transform(X) array([[ 0. ..., -1.22..., 1.33...], [ 1.22..., 0. ..., -0.26...], [-1.22..., 1.22..., -1.06...]])
2. 归一化
将属性缩放到一个指定范围(比如0-1)另一种常用的方法是将属性缩放到一个指定的最大值和最小值之间,这可以通过
preprocessing.MinMaxScaler类实现。
使用这种方法的目的包括:
1. 把数变为(0,1)之间的小数,方便数据处理
2. 把有量纲表达式变为无量纲表达式
归一化的好处:
提升模型收敛速度
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快
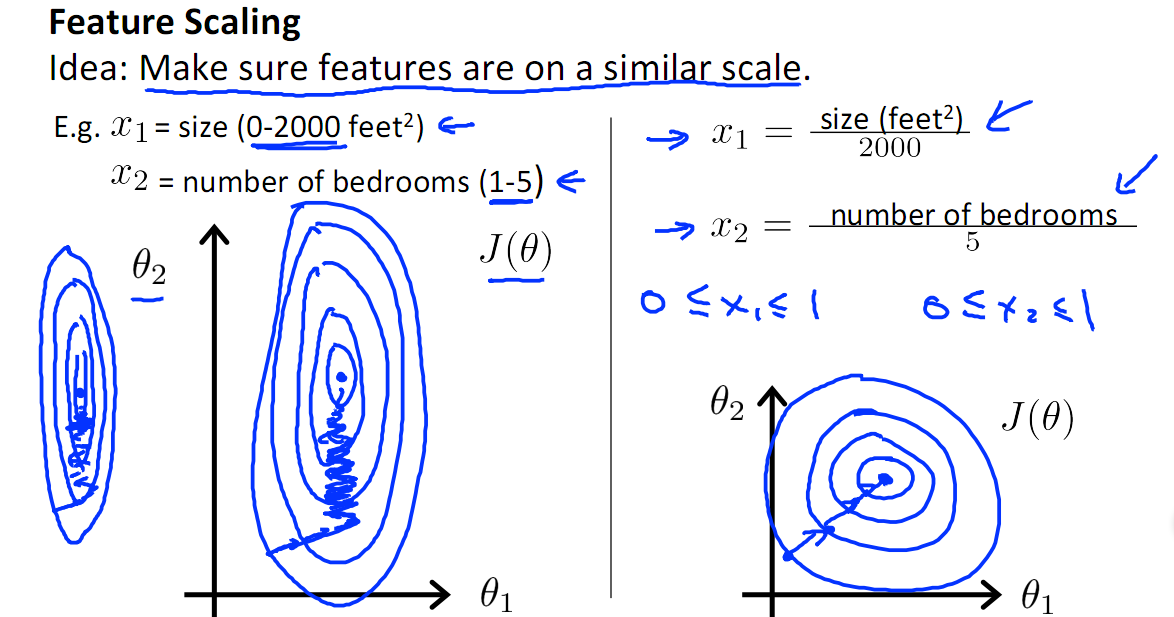
提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同
1.对于方差非常小的属性可以增强其稳定性
2.维持稀疏矩阵中为0的条目
常见的归一化方法:
min-max标准化(Min-max normalization)
也叫 离差标准化(x-min)/(max-min)
X_train = np.array( [[1,-1,2], [2,0,0], [0,1,-1]]) min_max_scaler = preprocessing.MinMaxScaler() X_train_minmax = min_max_scaler.fit_transform(X_train) >>> X_train_minmax array([[ 0.5 , 0. , 1. ], [ 1. , 0.5 , 0.33333333], [ 0. , 1. , 0. ]]) #将相同的缩放应用到测试集数据中 X_test = np.array([[-3, -1, 4]]) X_test_minmax = min_max_scler.transform(X_test) >>> X_test_minmax array([[-1.5 , 0. , 1.66666667]]) #缩放因子等属性 >>>min_max_scaler.scale_ array([0.5, 0.5, 0.33]) >>>min_max_scaler.min_ array([0, 0.5, 0.33]) 在构造对象时也可以直接指定最大最小值的范围:feature_range=(min, max),此时公式变为: X_std = (X - X.min(axis=0))/(X.max(axis=0)-X.min(axis=0)) X_scaled= X_std/(max-min)+min
log归一化
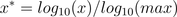
max为样本数据最大值,并且所有的数据都要大于等于1,这样才能落到[0,1]范围内。
3.正则化(Normalization)
正则化:将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其他核函数方法计算两个样本之间的相似性,这个方法会很有用。Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是是的每个处理后样本的p-范数(L1-norm, L2-norm)等于1。
p-范数的计算公式:||x||p=(|x1|^p+|x2|^p+…+|xn|^p)^(1/p)
该方法主要应用在文本分类和聚类中。例如,对于两个TF-IDF向量的I2-norm进行点积,就可以得到这两个向量的余弦相似性。
1.可以使用preprocessing.normalize()函数对指定数据进行转换。
X= [[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]] X_normalized = preprocessing.normalize(X, norm='l2') X_normalized array([[ 0.40..., -0.40..., 0.81...], [ 1. ..., 0. ..., 0. ...], [ 0. ..., 0.70..., -0.70...]])
怎么算出来的呢?
按行算: [1,-1,2]的L2范数是(1^2+(-1)^2+2^2)^(1/2)=6^(1/2)=2.45 第一行的每个元素除以L2范数,得到: [1/2.45, -1/2.45, 2/2.45] = [0.4, -0.4, 0.8..] 第二行和第一行一样,也是算自己的L2范数:(2^2+0^2+0^2)^(1/2)=2, [ 2/2, 0/2, 0/2]=[1,0,0]……
2.可以使用processing.Normalizer()类实现对训练集合测试集的拟合和转换:
normalizer = preprocessing.Normalizer().fit(X) # fit does nothing >>>normalizer Normalizer(copy=True, norm='l2') >>>normalizer.transform(X) array([[ 0.40..., -0.40..., 0.81...], [ 1. ..., 0. ..., 0. ...], [ 0. ..., 0.70..., -0.70...]]) >>> normalizer.transform([[-1., 1., 0.]]) array([[-0.70..., 0.70..., 0. ...]])

相关文章推荐
- preprocessing(归一化/标准化/正则化)
- 特征的转换_03-标准化,归一化,正则化
- [Scikit-Learn] - 数据预处理 - 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- Python数据预处理—归一化,标准化,正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 数据预处理 —— 归一化/标准化/正则化
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 数据的规范化,归一化,标准化,正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 数据归一化,标准化,正则化
- 数据预处理 - 归一化/标准化/正则化
- [置顶] python归一化、标准化、正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化