特征的转换_03-标准化,归一化,正则化
2017-02-07 16:03
477 查看
1.标准化StandardScaler
1.1 概述
我们知道,在训练模型的时候,要输入features,即因子,也叫特征。对于同一个特征,不同的样本中的取值可能会相差非常大,一些异常小或异常大的数据会误导模型的正确训练;另外,如果数据的分布很分散也会影响训练结果。以上两种方式都体现在方差会非常大。此时,我们可以将特征中的值进行标准差标准化,即转换为均值为0,方差为1的正态分布。所以在训练模型之前,一定要对特征的数据分布进行探索,并考虑是否有必要将数据进行标准化。标准差标准化也叫作Z-zero标准化,经过处理的数据会符合标准正态分布,即均值为0,方差为1。转化函数为:
x* = (x - μ) /σ
公式中标准化后的值x* 等于 原来的值x先减去原数据的均值μ,然后在除以原数据的标准差σ。最后得到的新的数据的均值就是0,方差/标准差为1.
注:是否要进行标准化,要根据具体实验定。如果特征非常稀疏,并且有大量的0(现实应用中很多特征都具有这个特点),Z-score 标准化的过程几乎就是一个除0的过程,结果不可预料。
1.2 spark代码
1.2.1 基于RDDSparkMLLIB提供了基于RDD的函数接口:
1.参数的设置
在mllib封装的StandardScaler方法中需要设置两个参数:
(1)withMean: 这是一个布尔类型的参数,可输入true,表示转化为均值为0,要注意的是它输出的结果是密集的,所以输入的数据不能是稀疏的,否则会报错哒。另外也可以设置false,表示对均值不做变化,如果不设置,默认是false.
(2)withStd:这也是一个布尔类型的参数,输入true表示将数据规模化到方差为1,默认情况下为true.
2.用法
mllib在StandardScaler中提供了一份fit 的方法,输入的参数是RDD[Vector].这个方法会对数据进行描述性统计,并输出一个模型,用这个模型来讲输入数据转换成方差为1或/和均值为0的特征数据(均值是否需要变成0是可以自己调整参数决定的)
另外,模型的输入也可以是一个Vector,无论输入哪种格式,计算后的结果会都会输出一个RDD[Vector]
3.代码与方法解读
package com.mllib.featureextraction
import org.apache.spark.mllib.feature.StandardScaler
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by wangcao on 2016/7/29.
*/
object StandardScaler {
def main (args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StandardScaler").setMaster("local")
val sc = new SparkContext(conf)
val data = MLUtils.loadLibSVMFile(sc, "C:\\Users\\Administrator\\Downloads\\sample_libsvm_data.txt")
//1.不设置任何参数,自动是默认的withMean=False and withStd=True
//注:new StandardScaler().只有一个fit的方法,fit里可传入一个Vector 或 RDD[Vector]
//使用fit生成的是一个StandardScalerModel
val scaler1 = new StandardScaler().fit(data.map(x => x.features))
//StandardScalerModel的变量与方法
//首先可以输出以下变量:模型的均值(Vector),标准差(Vector),是否withMean(Boolean),是否withStd(Boolean)
val mean = scaler1.mean
val std = scaler1.std
val isMean = scaler1.withMean
val isStd = scaler1.withStd
//其次可以调用三类方法:设置withMean参数,设置withStd参数,transform转化成规模化后的RDD[Vector]
//注:调用transform,可输入RDD[Vector],或Vector
val setMean = scaler1.setWithMean(false)
val setStd = scaler1.setWithStd(true)
val transformData = data.map(x => (x.label, scaler1.transform(x.features)))
//2.在建立模型的时候设置参数,以下表示方差为1,均值为0
val scaler2 = new StandardScaler(withMean = true, withStd = true)
.fit(data.map(x => x.features))
//使用transform方法输出规模化后的数据
//要注意的是,当withMean设置的是true时,输入的Vector必须是dense的!
val transformData2 =data.map(x => (x.label, scaler2.transform(Vectors.dense(x.features.toArray))))
}
}1.2.2 基于DateFrame
SparkML提供了基于DataFrame的函数接口
参数与用法与rdd的类似
具体应用请看代码:
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
// Compute summary statistics by fitting the StandardScaler.
val scalerModel = scaler.fit(dataFrame)
// Normalize each feature to have unit standard deviation.
val scaledData = scalerModel.transform(dataFrame)
scaledData.show()2.归一化
归一化就是将所有特征值都等比地缩小到0-1之间的区间内。其目的与标准化类似,为了使特征都在相同的规模中。sparkml提供两种方式:MinMaxScaler,MaxAbsScaler
2.1 MinMaxScaler
将一个特征中最大的值转换为1,最小的那个值转换为0,其余的值按照一定比例分布在(0,1)之间。计算公式如下: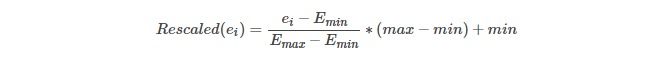
注意,如果原来是稀疏矩阵,因为原来的0转换后会不在是0,而只有最小值才是0,所以转换后价格形成一个密集矩阵。
代码:
// 创建一个DataFrame,3个样本3个特征
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.1, -1.0)),
(1, Vectors.dense(2.0, 1.1, 1.0)),
(2, Vectors.dense(3.0, 10.1, 3.0))
)).toDF("id", "features")
// 建立转换模型
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
val scalerModel = scaler.fit(dataFrame)
// 对特征进行转换
val scaledData = scalerModel.transform(dataFrame)
println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]")
scaledData.select("features", "scaledFeatures").show()打印结果:
Features scaled to range: [0.0, 1.0] +--------------+--------------+ | features|scaledFeatures| +--------------+--------------+ |[1.0,0.1,-1.0]| [0.0,0.0,0.0]| | [2.0,1.1,1.0]| [0.5,0.1,0.5]| |[3.0,10.1,3.0]| [1.0,1.0,1.0]| +--------------+--------------+
2.2 MaxAbsScaler
将一个特征中的值规模化到(-1, 1)的区间内。将每一个数都除以特征值中的最大绝对数。这样的做法并不会改变原来为0的值,所以也不会改变稀疏性。
代码:
// 创建一个DataFrame,3个样本3个特征
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.1, -8.0)),
(1, Vectors.dense(2.0, 1.0, -4.0)),
(2, Vectors.dense(4.0, 10.0, 8.0))
)).toDF("id", "features")
//建立转换模型
val scaler = new MaxAbsScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
val scalerModel = scaler.fit(dataFrame)
// 转换特征到[-1,1]区间
val scaledData = scalerModel.transform(dataFrame)
scaledData.select("features", "scaledFeatures").show()打印结果:
+--------------+----------------+ | features| scaledFeatures| +--------------+----------------+ |[1.0,0.1,-8.0]|[0.25,0.01,-1.0]| |[2.0,1.0,-4.0]| [0.5,0.1,-0.5]| |[4.0,10.0,8.0]| [1.0,1.0,1.0]| +--------------+----------------+
3.正则化Normalizer
3.1 概述
有没有遇到过这样的情景,训练模型的时候误差非常小,但是在测试模型的时候误差就大了,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。而优秀的模型往往是在简单的基础上最小化误差,因此,可以使用范数规则化去约束模型。我们常常见到L0,L1,L2这些形式的范数,想要对范数的知识进行详细的了解,可以参见博客http://blog.csdn.net/zouxy09/article/details/24971995/。在此篇幅不做详解。
为了避免出现过度拟合的问题,我们通过这些范数规则去约束我们原始的特征数据。这个过程被称之“Normalizer”
3.2 Spark代码
3.2.1 spark mllib 中 Normalizer的用法1.参数的设置
Normalizer 需要输入的参数有且仅有一个:
p:即L(p)中的P,默认p=2,即范式L2
通过Normalizer 可以将RDD[Vector]转化为规则化后的RDD[Vector],也可以将Vector转化为规则化后的Vector.
2.代码解读
package com.mllib.featureextraction
import org.apache.spark.mllib.feature.Normalizer
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2016/7/29.
*/
object Normalizer {
def main (args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Normalizer").setMaster("local")
val sc = new SparkContext(conf)
val data = MLUtils.loadLibSVMFile(sc, "C:\\Users\\Administrator\\Downloads\\sample_libsvm_data.txt")
//1.创建一个正规化器Normalizer,不传入任何参数时,默认p=2
val normalizer1 = new Normalizer()
//建立的模型有且仅有一个方法就是transform,将原始数据转化成标准化后的数据
//输入的数据格式可以使RDD[Vector],也可以是Vector,输出的格式与输入的格式相对应
val data1 = data.map(x => (x.label, normalizer1.transform(x.features)))
data1.take(2).foreach(println)
//创建一个正规化器Normalizer,参数设置为正无穷
val normalizer2 = new Normalizer(p = Double.PositiveInfinity)
val data2 = data.map(x => (x.label, normalizer2.transform(x.features)))
}
}3.2.2 spark ML 中 Normalizer的用法
基于DataFrame的用法:
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.5, -1.0)),
(1, Vectors.dense(2.0, 1.0, 1.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)).toDF("id", "features")
// 使用L1范式正则
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
println("Normalized using L^1 norm")
l1NormData.show()
// 使用正无穷范式
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
println("Normalized using L^inf norm")
lInfNormData.show()打印结果:
Normalized using L^1 norm +---+--------------+------------------+ | id| features| normFeatures| +---+--------------+------------------+ | 0|[1.0,0.5,-1.0]| [0.4,0.2,-0.4]| | 1| [2.0,1.0,1.0]| [0.5,0.25,0.25]| | 2|[4.0,10.0,2.0]|[0.25,0.625,0.125]| +---+--------------+------------------+ Normalized using L^inf norm +---+--------------+--------------+ | id| features| normFeatures| +---+--------------+--------------+ | 0|[1.0,0.5,-1.0]|[1.0,0.5,-1.0]| | 1| [2.0,1.0,1.0]| [1.0,0.5,0.5]| | 2|[4.0,10.0,2.0]| [0.4,1.0,0.2]| +---+--------------+--------------+

相关文章推荐
- 特征工程(三) 数据标准化和归一化
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- [Scikit-Learn] - 数据预处理 - 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- python机器学习库sklearn——数据归一化、标准化、特征选择、逻辑回归、贝叶斯分类器、KNN模型、支持向量机、参数优化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 归一化、标准化和正则化的关系
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 归一化、标准化和正则化的关系
- 使用sklearn进行数据预处理 —— 标准化/归一化/正则化
- spark 数据预处理 特征标准化 归一化模块
- 数据的规范化,归一化,标准化,正则化
- 数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化