Python:基于pandas ,Pymatlab的 数据分析入门
2016-11-25 07:46
1001 查看
最近这几天,老师有个项目要用到数据批量分析,让我参加进来,但是,我以前纯粹是搞应用程序开发的,并没有过多接触过数据分析。不行,任务下来了,硬着头皮也要上啊。于是,我浩浩荡荡的开始了数据分析学习计划。
首先,我先说一下,因为,我以前都是写Java代码的,所以,这次决定换个新语言,选了半天,决定从0基础入门python3.
关于python,我就不废话了,网上一大波教程和介绍,有兴趣可以去学习一下,个人觉得挺好玩的。【不过,这语言折磨人可是真的】
好了,进入正题。
我的课题选项是:假设有一次购物活动,来自福建省几个主要城市的人参加了这次购物活动,活动结束了,然后我们掌握了这些购买数据,然后进一步分析,便于掌握规律,提供数据给市场运营部去参考。
数据量:10000条购买数据,前面是人的基本信息,后面是所购买的商品种类列表。
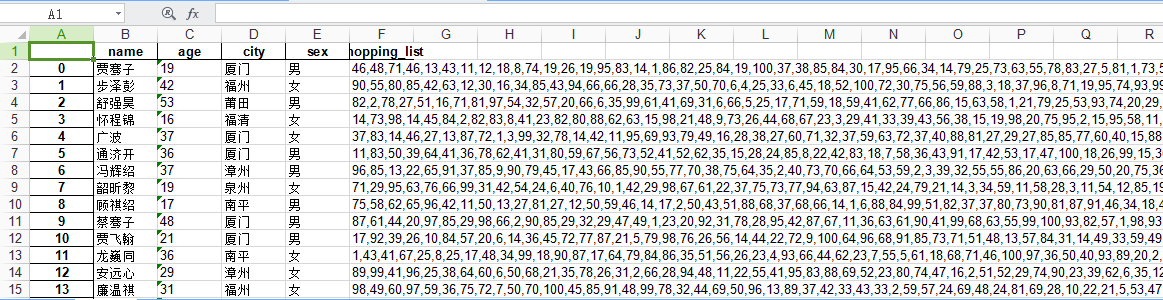
福建省几个主要地区:
①第一个任务,搭建环境
我这里用了这些主要依赖库
如果没有,你可以通过pip 或者其他三方安装工具,或者直接去官网下载【安装过程很痛苦】。
好了,基本环境搞完了,接下来就是怎么来分析了
下面是我的常量表:百家姓和一些人名,便于随机生成人名。
然后是城市列表,因为,根据概率论,如果我们不加权的话,最后,随着数据的增加,我们的结果会南辕北辙。所以,我用了最简单的加权方法:直接列表里面的地名按照个数比来加权:
注意到了没:几个城市的数目是成比例的,为了随机数产生的时候,按照一定的比例。当然,这是很不科学的,但是因为是简单入门案例,所以我这里用了模拟数据。
上面是一些常量,相信大家可以看得懂
最后,附上项目目录:
好了,直接看代码:
首先是,数据分析工具模块:
数据分析模块,是为了产生数据和简单分析数据。
然后是主模块:
最后,产生一个效果图:
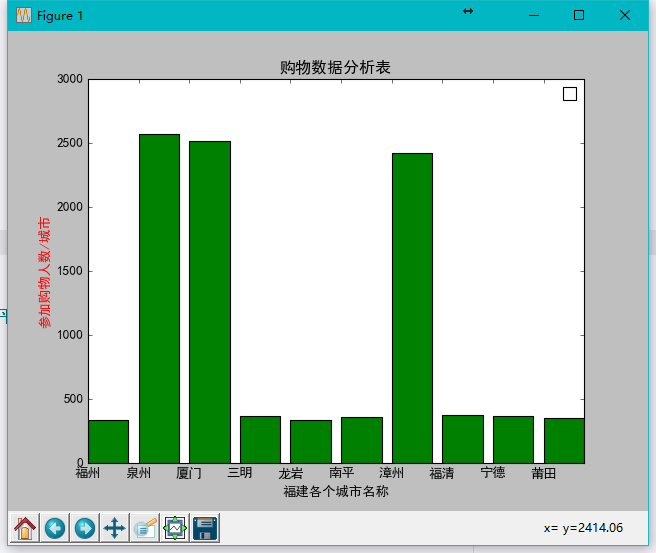
哈哈,是不是可以打出:厦门,泉州,漳州人比较有钱?(数据没有说服力,仅仅是测试而已)。
好了,最简单的入门程序到这里就完了,如果你有兴趣,还可以再深度挖掘:比如,来自福州的男性喜欢购买什么,来自厦门的女性喜欢购买什么等等。
喜欢的话,欢迎转载。
首先,我先说一下,因为,我以前都是写Java代码的,所以,这次决定换个新语言,选了半天,决定从0基础入门python3.
关于python,我就不废话了,网上一大波教程和介绍,有兴趣可以去学习一下,个人觉得挺好玩的。【不过,这语言折磨人可是真的】
好了,进入正题。
我的课题选项是:假设有一次购物活动,来自福建省几个主要城市的人参加了这次购物活动,活动结束了,然后我们掌握了这些购买数据,然后进一步分析,便于掌握规律,提供数据给市场运营部去参考。
数据量:10000条购买数据,前面是人的基本信息,后面是所购买的商品种类列表。
福建省几个主要地区:
"福州", "泉州", "厦门", "三明", "龙岩"。。。。等等
①第一个任务,搭建环境
我这里用了这些主要依赖库
import pandas as pd import numpy as np import random
如果没有,你可以通过pip 或者其他三方安装工具,或者直接去官网下载【安装过程很痛苦】。
好了,基本环境搞完了,接下来就是怎么来分析了
下面是我的常量表:百家姓和一些人名,便于随机生成人名。
MAX_AGE = 55 MIN_AGE = 15 SHOPPING_LIST = ["女装", "男装", "内衣", "鞋靴", "箱包", "配件", "童装玩具", "孕产", "用品", "家电", "数码", "手机", "美妆", "洗护", "保健品", "珠宝", "眼镜", "手表", "运动", "户外", "乐器", "游戏", "动漫", "影视", "美食", "生鲜", "零食", "鲜花", "农资", "房产", "装修", "建材", "家具", "家饰", "家纺", "汽车", "二手车", "用品", "办公", "DIY", "五金电子", "百货", "餐厨", "家庭保健", "学习", "卡券", "本地服务"] FIRST_NAME_TABLE = ["赵", "钱", "孙", "李", "周", "吴", "郑", "王", "冯", "陈", "褚", "卫", "蒋", "沈", "韩", "杨", "朱", "秦", "尤", "许", "何", "吕", "施", "张", "孔", "曹", "严", "华", "金", "魏", "陶", "姜", "戚", "谢", "邹", "喻", "柏", "水", "窦", "章", "云", "苏", "潘", "葛", "奚", "范", "彭", "郎", "鲁", "韦", "昌", "马", "苗", "凤", "花", "方", "俞", "任", "袁", "柳", "酆", "鲍", "史", "唐", "费", "廉", "岑", "薛", "雷", "贺", "倪", "汤", "滕", "殷", "罗", "毕", "郝", "邬", "安", "常", "乐", "于", "时", "傅", "皮", "卞", "齐", "康", "伍", "余", "元", "卜", "顾", "孟", "平", "黄", "和", "穆", "萧", "尹", "姚", "邵", "湛", "汪", "禹", "狄", "米", "贝", "明", "臧", "计", "伏", "成", "戴", "谈", "宋", "茅", "庞", "熊", "纪", "舒", "屈", "项", "祝", "董", "梁", "杜", "阮", "蓝", "闵", "席", "季", "麻", "强", "贾", "路", "娄", "危", "江", "童", "颜", "郭", "梅", "盛", "林", "刁", "钟", "徐", "邱", "骆", "高", "夏", "蔡", "田", "樊", "胡", "凌", "霍", "虞", "万", "支", "柯", "昝", "管", "卢", "莫", "经", "房", "裘", "缪", "干", "解", "应", "宗", "丁", "宣", "贲", "邓", "郁", "单", "杭", "洪", "包", "诸", "左", "石", "崔", "吉", "钮", "龚", "程", "嵇", "邢", "滑", "裴", "陆", "荣", "翁", "荀", "羊", "於", "惠", "甄", "曲", "家", "封", "芮", "羿", "储", "靳", "汲", "邴", "糜", "松", "井", "段", "富", "巫", "乌", "焦", "巴", "弓", "牧", "隗", "山", "谷", "车", "侯", "宓", "蓬", "全", "郗", "班", "仰", "秋", "仲", "伊", "宫", "宁", "仇", "栾", "暴", "甘", "钭", "厉", "戎", "祖", "武", "符", "刘", "景", "詹", "束", "龙", "叶", "幸", "司", "韶", "郜", "黎", "蓟", "薄", "印", "宿", "白", "怀", "蒲", "台", "从", "鄂", "索", "咸", "籍", "赖", "卓", "蔺", "屠", "蒙", "池", "乔", "阴", "郁", "胥", "能", "苍", "双", "闻", "莘", "党", "翟", "谭", "贡", "劳", "逄", "姬", "申", "扶", "堵", "冉", "宰", "郦", "雍", "却", "璩", "桑", "桂", "濮", "牛", "寿", "通", "边", "扈", "燕", "冀", "郏", "浦", "尚", "农", "温", "别", "庄", "晏", "柴", "瞿", "阎", "充", "慕", "连", "茹", "习", "宦", "艾", "鱼", "容", "向", "古", "易", "慎", "戈", "廖", "庚", "终", "暨", "居", "衡", "步", "都", "耿", "满", "弘", "匡", "国", "文", "寇", "广", "禄", "阙", "东", "殴", "殳", "沃", "利", "蔚", "越", "夔", "隆", "师", "巩", "厍", "聂", "晁", "勾", "敖", "融", "冷", "訾", "辛", "阚", "那", "简", "饶", "空", "曾", "毋", "沙", "乜", "养", "鞠", "须", "丰", "巢", "关", "蒯", "相", "查", "后", "荆", "红", "游", "竺", "权", "逯", "盖", "益", "岳", "帅", "缑", "亢", "况", "后", "有", "琴", ] LAST_NAME_TABLE = ["小明", "红", "小花", "国强", "建国", "军", "波", "良", "小芳", "芳", "燕", "敏", "小敏", "文明", "建军", "文", "平", "之明", "小燕", "英", "轩懿", "伟烨", "博苑", "泽伟", "彤熠", "煊鸿", "涛博", "霖烨", "华 烨", "祺煜", "宸智", "豪正", "然昊", "杰明", "诚立", "轩立", "辉立", "熙峻", "文弘", "彤熠", "煊鸿", "霖烨", "瀚哲", "鹏鑫", "远致", "驰俊", "泽雨", "磊烨", "睿晟", "佑天", "昊文", "洁修", "昕黎", "航远", "尧旭", "涛鸿", "祺伟", "轩荣", "泽越", "宇浩", "瑜瑾", "轩皓", "苍擎", "宇擎", "泽志", "渊睿", "瑞楷", "轩子", "文弘", "瀚哲", "泽雨", "磊鑫", "杰修", "诚伟", "辉建", "鹏晋", "磊天", "辉绍", "洋泽", "轩明", "柏健", "煊鹏", "强昊", "宸伟", "超博", "浩君", "骞子", "辉明", "涛鹏", "彬炎", "轩鹤", "彬越", "华风", "琪靖", "诚明", "格高", "华光", "源国", "宇冠", "昱晗", "润涵", "飞翰", "海翰", "乾昊", "博浩", "安和", "博弘", "恺宏", "朗鸿", "奥华", "灿华", "慕嘉", "秉坚", "明建", "鑫金", "程锦", "瑜瑾", "鹏晋", "赋经", "同景", "琪靖", "昊君", "明俊", "同季", "济开", "安凯", "成康", "语乐", "勤力", "哲良", "群理", "彦茂", "博敏", "达明", "义朋", "泽彭", "举鹏", "存濮", "心溥", "瑜璞", "泽浦", "邃奇", "祥祺", "轩荣", "达锐", "慈睿", "祺绍", "杰圣", "睿晟", "源思", "年斯", "宁泰", "佑天", "巍同", "伟奕", "温祺", "虹文", "笛向", "远心", "德欣", "翰新", "言兴", "阑星", "为修", "尧旭", "明炫", "真学", "风雪", "昶雅", "曦阳", "熠烨", "韶英", "贞永", "德咏", "寰宇", "泽雨", "韵玉", "彬越", "和蕴", "彦哲", "海振", "志正", "晋子"]
然后是城市列表,因为,根据概率论,如果我们不加权的话,最后,随着数据的增加,我们的结果会南辕北辙。所以,我用了最简单的加权方法:直接列表里面的地名按照个数比来加权:
CITY_TABLE = ["福州", "泉州", "厦门", "三明", "龙岩", "三明", "龙岩", "三明", "龙岩", "三明", "龙岩", "三明", "龙岩", "南平", "漳州", "福清", "宁德", "莆田", "漳州", "漳州", "漳州", "漳州", "漳州", "漳州", "泉州", "泉州", "泉州", "泉州", "泉州", "福州", "福州", "福州", "泉州", "厦门", "厦门", "厦门", "厦门", "厦门", "厦门"]
注意到了没:几个城市的数目是成比例的,为了随机数产生的时候,按照一定的比例。当然,这是很不科学的,但是因为是简单入门案例,所以我这里用了模拟数据。
SEX_TABLE = ["男", "女"] EXCEL_PATH = "../temp/sheet.xls" SHOPPING_COUNT = 100
上面是一些常量,相信大家可以看得懂
最后,附上项目目录:
好了,直接看代码:
首先是,数据分析工具模块:
# coding='utf-8'
import pandas as pd import numpy as np import random
import app.my_utils.paraments as para
def create_shopping_list():
res = ""
for i in range(100): # 假设购买了100件商品
res += str(random.randint(1, para.SHOPPING_COUNT)) + ","
return res
def create_excel(path):
data_list = []
for i in range(10000):
data_list.append(
[random.choice(para.FIRST_NAME_TABLE) + random.choice(para.LAST_NAME_TABLE),
random.randint(para.MIN_AGE, para.MAX_AGE), random.choice(para.CITY_TABLE),
random.choice(para.SEX_TABLE),
create_shopping_list()])
data_array = np.array(data_list)
data_frame = pd.DataFrame(data=data_array, index=None, columns=["name", "age", "city", "sex", "shopping_list"])
print("Start to write data in Excel sheet......")
data_frame.to_excel(path)
print("Excel Write Finished!")
def get_point(path):
# ["福州", "泉州", "厦门", "三明", "龙岩", "南平", "漳州", "福清", "宁德", "莆田"]
excel = None
fuzhou_num = 0
quanzhou_num = 0
xiamen_num = 0
sanming_num = 0
longyan_num = 0
nanping_num = 0
zhangzhou_num = 0
fuqing_num = 0
ningde_num = 0
putian_num = 0
try:
excel = pd.DataFrame(pd.read_excel(path))
except Exception as e:
print("Error!")
finally:
for i in range(0, len(excel)):
item = excel.values[i].tolist()
if item[2] == "福州":
fuzhou_num += 1
elif item[2] == "泉州":
quanzhou_num += 1
elif item[2] == "厦门":
xiamen_num += 1
elif item[2] == "三明":
sanming_num += 1
elif item[2] == "龙岩":
longyan_num += 1
elif item[2] == "南平":
nanping_num += 1
elif item[2] == "漳州":
zhangzhou_num += 1
elif item[2] == "福清":
fuqing_num += 1
elif item[2] == "宁德":
ningde_num += 1
elif item[2] == "莆田":
putian_num += 1
return [fuzhou_num, quanzhou_num, xiamen_num, sanming_num, longyan_num, nanping_num, zhangzhou_num, fuqing_num,
ningde_num, putian_num]
if __name__ == "__main__":
create_excel(para.EXCEL_PATH)
ll = get_point(para.EXCEL_PATH)
print(ll)
数据分析模块,是为了产生数据和简单分析数据。
然后是主模块:
# -*-coding:gbk-*-
import pylab
pylab.mpl.rcParams['font.sans-serif'] = ['SimHei']
pylab.mpl.rcParams['axes.unicode_minus'] = False
import numpy as np
import matplotlib.pyplot as plt
import app.my_utils.utils as ut
import app.my_utils.paraments as para
index = np.arange(5)
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Y = ut.get_point(para.EXCEL_PATH)
plt.title("购物数据分析表")
plt.xticks(X, ["福州", "泉州", "厦门", "三明", "龙岩", "南平", "漳州", "福清", "宁德", "莆田"])
plt.xlabel("福建各个城市名称")
plt.ylabel("参加购物人数/城市", color="red")
plt.legend(["人数:"], loc=0)
plt.bar(X, Y, color="green")
plt.show()最后,产生一个效果图:
哈哈,是不是可以打出:厦门,泉州,漳州人比较有钱?(数据没有说服力,仅仅是测试而已)。
好了,最简单的入门程序到这里就完了,如果你有兴趣,还可以再深度挖掘:比如,来自福州的男性喜欢购买什么,来自厦门的女性喜欢购买什么等等。
喜欢的话,欢迎转载。

相关文章推荐
- 基于python的数据分析库Pandas
- Python数据分析入门之pandas基础总结
- Python数据分析 Pandas入门
- Python数据分析入门-Pandas环境搭建
- 利用Python数据分析:pandas入门(四)
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍 一、pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主
- Python常用的数据分析工具入门: numpy和pandas入门
- Python数据分析入门之pandas总结基础
- 利用python进行数据分析-pandas入门3
- 利用python进行数据分析-pandas入门2
- Python——数据分析Pandas入门
- Python数据分析入门(一)-Pandas数据结构(Series)
- 利用Python数据分析:pandas入门(一)
- 用Excel演示python中pandas中数据的查询显示方法-python数据分析入门
- 利用Pythonj进行数据分析学习笔记——第五章 pandas入门
- 利用Python数据分析:pandas入门(五)
- python数据分析入门(一)----安装pandas
- 利用Python进行数据分析(五)之pandas入门
- Python数据分析入门-Pandas环境搭建
- 利用Python数据分析:pandas入门(六)