决策树(ID3、C4.5、CART)
2016-11-20 15:41
435 查看
1. 基本概念
所谓决策树,顾名思义,就是一种树,一种依托于策略抉择而建立起来的树。在机器学习中,决策树是一种预测模型,代表的是一种对象特征属性与对象目标值之间的一种映射关系。决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出。,下图给出了决策树的一个简单例子: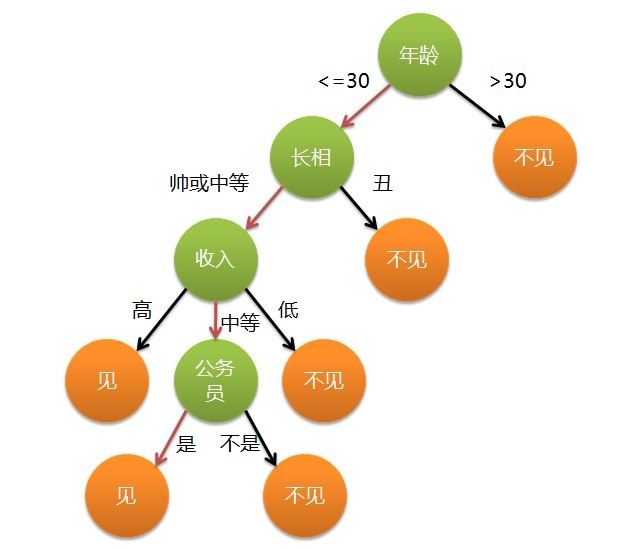
决策树分为分类树和回归树两种,分类树对离散变量做决策,输出是样本的预测类别;回归树对连续变量做决策,输出是一个实数 。本文介绍ID3、C4.5和CART这三种构造决策树的算法
2. ID3算法
ID3算法是J. Ross Quinlan于1975提出的一种贪心算法,用来构造决策树。其建立在“奥卡姆剃刀”的基础上,即越是小型的决策树越优于大的决策树。ID3算法中根据特征选择和信息增益评估,每次选择信息增益最大的特征作为分支标准。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益其实是有一个缺点,那就是它偏向于具有大量值的属性–就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的。此外,ID3不能处理连续分布的数据特征。① 信息熵
熵这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度,而在信息学里面,熵是对不确定性的度量。在1948年,香农引入了信息熵(information entropy),将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。对于有K个类别的分类问题来说,假定样本集合D中第 k 类样本所占的比例为pk(k=1,2,...,K),则样本集合D的信息熵定义为:
Ent(D)=−∑Kk=1pk⋅log2pk
② 信息增益
在决策树的分类问题中,信息增益(information gain)是针对一个特定的分支标准(branching criteria)T,计算原有数据的信息熵与引入该分支标准后的信息熵之差。信息增益的定义如下:Gain(D,a)=Ent(D)−∑Vv=1|Dv||D|Ent(Dv)
其中a是有V个不同取值的离散特征,使用特征a对样本集D进行划分会产生V个分支,Dv表示D中所有在特征a上取值为av的样本,即第v个分支的节点集合。|Dv||D|表示分支节点的权重,即分支节点的样本数越多,其影响越大。
接下来以天气的例子来说明ID3算法。下图是样本数据集,每个样本包括4个特征“Outlook”,“Temperature”,”Humidity”和“Windy”,模型的分类目标是play或者not play。
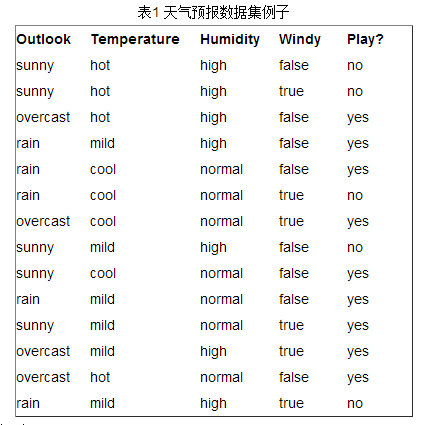
表中一共包含14个样本,包括9个正样本和5个负样本,并且是一个二分类问题,那么当前信息熵的计算如下:
Ent(D)=−914log2914−514log2514=0.940286
接下来以表中的Outlook属性作为分支标准,根据sunny、overcast、rain这三个属性值可将数据分为三类,如下图所示:
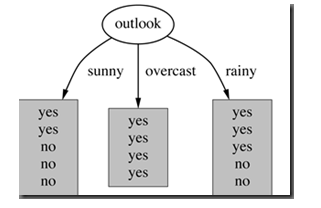
引入该分支标准后,数据被分成了3个分支,每个分支的信息熵计算如下:
H(Dsunny)=−25log225−35log235=0.970951
H(Dovercast)=−44log244=0
H(Drain)=−25log225−35log235=0.970951
因此,基于该分支标准 T 所带来的信息增益为:
Gain(D,a)=Ent(D)−∑Vv=1|Dv||D|Ent(Dv)=0.940286−514⋅0.970951+414⋅0+514⋅0.970951=0.24675
③ 算法思想
ID3算法的基本思想是:首先计算出原始数据集的信息熵,然后依次将数据中的每一个特征作为分支标准,并计算其相对于原始数据的信息增益,选择最大信息增益的分支标准来划分数据,因为信息增益越大,区分样本的能力就越强,越具有代表性。重复上述过程从而生成一棵决策树,很显然这是一种自顶向下的贪心策略。3. C4.5算法
C4.5算法是对ID3算法的改进,C4.5克服了ID3的2个缺点:用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性
不能处理连续属性
对于离散特征,C4.5算法不直接使用信息增益,而是使用“增益率”(gain ratio)来选择最优的分支标准,增益率的定义如下:
GainRatio(D,T)=Gain(D,T)IV(T)
其中,IV(T)=−∑Vv=1|Dv||D|log2|Dv||D|,称作分支标准T的“固有值”(intrinstic value)。作为分支标准的属性可取值越多,则IV 的值越大。需要注意的是: 增益率准则对可取值数目较少的属性有所偏好,因此C4.5算法并不是直接选择增益率最大的属性作为分支标准,而是先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C4.5算法处理连续属性的方法是先把连续属性转换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化的方法:<=vj的分到左子树,>vj的分到右子树。计算这N-1种情况下最大的信息增益率。在离散属性上只需要计算1次信息增益率,而在连续属性上却需要计算N-1次,计算量是相当大的。通过以下办法可以减少计算量:对于连续属性先按大小进行排序,只有在分类发生改变的地方才需要切开。比如对Temperature进行排序:

本来有13种离散化的情况,现在只需计算7种。如果利用增益率来选择连续值属性的分界点,会导致一些副作用。分界点将样本分成两个部分,这两个部分的样本个数之比也会影响增益率。根据增益率公式,我们可以发现,当分界点能够把样本分成数量相等的两个子集时(我们称此时的分界点为等分分界点),增益率的抑制会被最大化,因此等分分界点被过分抑制了。子集样本个数能够影响分界点,显然不合理。因此在决定分界点是还是采用增益这个指标,而选择属性的时候才使用增益率这个指标。
4. CART算法
CART(Classification And Regression Tree)算法既可以用于创建分类树,也可以用于创建回归树。CART算法的重要特点包含以下三个方面:二分(Binary Split):在每次判断过程中,都是对样本数据进行二分。CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分
单变量分割(Split Based on One Variable):每次最优划分都是针对单个变量。
剪枝策略:CART算法的关键点,也是整个Tree-Based算法的关键步骤。剪枝过程特别重要,所以在最优决策树生成过程中占有重要地位。有研究表明,剪枝过程的重要性要比树生成过程更为重要,对于不同的划分标准生成的最大树(Maximum Tree),在剪枝之后都能够保留最重要的属性划分,差别不大。反而是剪枝方法对于最优树的生成更为关键。
① CART分类决策树
GINI指数
CART的分支标准建立在GINI指数这个概念上,GINI指数主要是度量数据划分的不纯度,是介于0~1之间的数。GINI值越小,表明样本集合的纯净度越高;GINI值越大表明样本集合的类别越杂乱。直观来说,GINI指数反映了从数据集中随机抽出两个样本,其类别不一致的概率。衡量出数据集某个特征所有取值的Gini指数后,就可以得到该特征的Gini Split info,也就是GiniGain。不考虑剪枝情况下,分类决策树递归创建过程中就是每次选择GiniGain最小的节点做分叉点,直至子数据集都属于同一类或者所有特征用光了。的计算过程如下:对于一个数据集T,将某一个特征作为分支标准,其第i个取值的Gini指数计算方式为:gini(Ti)=1−∑nj=1p2j,其中n表示数据的类别数,pj表样本属于第j个类别的概率。计算出某个样本特征所有取值的Gini指数后就可以得到Gini Split Info:Ginisplit(T)=∑2i=1NiNgini(Ti),其中N 表示样本总数,Ni表示属于特征第i个属性值的样本数。
特征双化
如果特征的值是离散的,并且是具有两个以上的取值,则CART算法会考虑将目标类别合并成两个超类别(双化)。因为CART树是二叉树,所以对于有N(N≥3)个取值的离散特征,在处理时也只能有两个分支,这就要通过组合创建二取值序列并取GiniGain最小者作为树分叉决策点。例如,某特征值具有[‘young’,’middle’,’old’]三个取值,那么二分序列会有如下3种可能性:[((‘young’,), (‘middle’, ‘old’)), ((‘middle’,), (‘young’, ‘old’)), ((‘old’,), (‘young’, ‘middle’))]。对连续特征的处理
如果特征的取值范围是连续的,则CART算法需要把连续属性转换为离散属性再进行处理。如果有N条样本,那么我们有N-1种离散化的方法:<=vj的分到左子树,>vj的分到右子树。取这N-1种情况下GiniGain最小的离散化方式。下面举一个简单的例子来说明上述过程:
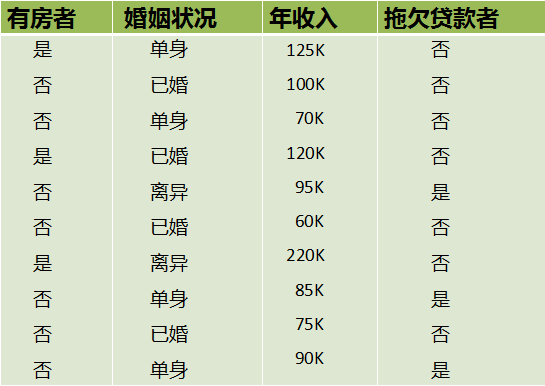
在上述图中,每个样本有3个特征,分别是有房情况,婚姻状况和年收入,其中有房情况和婚姻状况是离散的取值,而年收入是连续的取值。拖欠贷款者属于分类的结果。现在来看有房情况这个特征,那么按照它划分后的Gini指数计算如下:
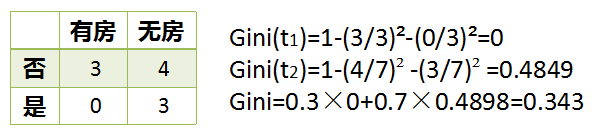
而对于婚姻状况特征来说,它的取值有3种,按照每种属性值分裂后Gini指标计算如下:
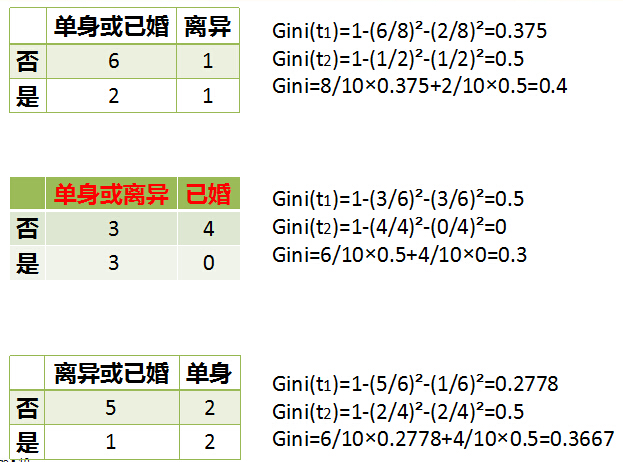
最后还有一个取值连续的特征,年收入,它的取值是连续的,那么连续的取值采用分裂点进行分裂。如下:
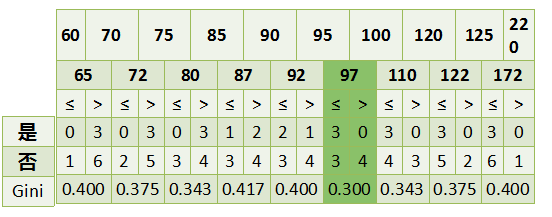
根据这样的分裂规则CART算法就能完成建树过程。
CART的剪枝
分析CART的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。决策树常用的剪枝常用的简直方法有两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。预剪枝是根据一些原则及早的停止树增长,如树的深度达到用户所要的深度、节点中样本个数少于用户指定个数、不纯度指标下降的最大幅度小于用户指定的幅度等;后剪枝则是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点,可以使用的后剪枝方法有多种,比如:代价复杂性剪枝、最小误差剪枝、悲观误差剪枝等等。5. 参考资料
http://blog.csdn.net/acdreamers/article/details/44661149http://blog.csdn.net/acdreamers/article/details/44664481
http://blog.csdn.net/u011067360/article/details/24871801
http://blog.csdn.net/suipingsp/article/details/42264413

相关文章推荐
- 决策树(ID3、C4.5、CART、随机森林)
- 2、决策树ID3、C4.5、CART
- 决策树归纳一般框架(ID3,C4.5,CART)
- 决策树归纳一般框架(ID3,C4.5,CART)
- python机器学习案例系列教程——决策树(ID3、C4.5、CART)
- ID3、C4.5、CART三种决策树的区别
- 2、决策树ID3、C4.5、CART
- 决策树CART与ID3,C4.5联系与区别
- 决策树学习(下)——ID3、C4.5、CART深度剖析及源码实现
- 决策树(ID3、C4.5、CART、随机森林)
- 决策树ID3,C4.5,CART,GBDT,RF
- 机器学习算法与Python实践(11) - 决策树 ID3、C4.5、CART
- 决策树(三)--完整总结(ID3,C4.5,CART,剪枝,替代)
- python之实战----决策树(ID3,C4.5,CART)战sin(x)+随机噪声
- 决策树(ID3、C4.5、CART、随机森林、GBDT)
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝
- 决策树之ID3,C4.5
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝
- 决策树ID3;C4.5详解和python实现与R语言实现比较
- 决策树ID3、C4.5、CART算法:信息熵,区别,剪枝理论总结