贝叶斯学习 -- matlab、python代码分析(2)
2016-11-20 10:08
351 查看
目录
1. 评估假设
2. 贝叶斯法则
3. 贝叶斯分类器
4. 实例分析
====================================
贝叶斯法则
贝叶斯推理提供一种推理的概率手段: 代考察的量遵循某概率分布,且可以根据这些概率以及已观察到的数据进行推理,以作出最优决策。
贝叶斯学习方法的特性:
1 观察到的每个训练样例可以增量的升高或降低某假设的估计概率。
2 先验知识和观察数据一起决定假设的最终概率。
3 贝叶斯方法允许作出不确定性的假设。
4 新的实例分类可由多个假设一起做出预测,用它们的概率来加权。
5 即使在贝叶斯方法计算复杂度较高时,它们仍可以作为一个最优决策的标准衡量其他方法。
在机器学习中,我们感兴趣的是:给定训练数据D时,确定假设空间H中的最佳假设。更精确的说: 贝叶斯法则提供了一种计算假设概率的方法,它基于假设的先验概率、 给定假设下观察到不同数据的概率以及观察到的数据本身。
我们先引入一些符号:
P(h) :没有训练数据前假设h拥有的初始概率。(常被称为先验概率,反映了我们所拥有的关于假设h是一正确假设的机会 的背景知识。如果没有这一知识,我们可以将每一个候选假设赋予相同的先验概率)
P(D): 将要观察的训练数据D的先验概率(在没有确定某一假设成立时,D的概率)
P(D|h): 假设h成立情况下,观察到数据D的概率。
P(h|D): (机器学习中感兴趣的)给定训练数据D时h成立的概率。(又被称为后验概率,反映了在看到训练数据D后h成立的置信度。)
注: 后验概率反映了训练数据D的影响,先验概率则是独立与D的。
贝叶斯公式:
P(h|D)=P(D|h)P(h)P(D)
提供了从先验概率P(h)以及P(D) P(D|h) 求得后验概率的方法。
在许多学习场景中,学习器考虑候选假设集合H并在其中寻找给定数据D时可能性最大的假设h(或者存在多个这样的假设时选择其中一个。)这样具有最大可能性的假设称为极大后验假设 MAP:
hMAP=argmaxh∈HP(h|D)=argmaxh∈HP(D|h)P(h)
在某些情况下可假设H中的每一个假设有相同的先验概率(对H中任意hi和hj有 P(hi)=P(hj)), 所以只需考虑P(D|h)来寻找极大可能假设。
P(D|h)常被称为给定h时数据D的似然度。而使P(D|h)最大的假设称为极大似然假设 ML
hML=argmaxh∈HP(D|h)
举例:
极大似然和最小误差平方和
本节学习在连续值目标函数的问题。(神经网络线性回归、多项式曲线拟合)
在特定的前提下,任一学习算法如果是输出的假设预测和训练数据之间的平方误差最小化,它将输出一极大似然假设。
在实际的学习器中,对于每个训练样例<xi,di>, 每个目标值di是被随机噪声干扰的,而这个随机噪声一般遵循正态分布,即di=f(xi)+ei , 学习器的任务就是: 在所有假设有相同的先验概率前提下,输出极大似然假设(MAP)
为了讨论像 e 这样连续变量上的概率,我们引入概率密度:
p(x0)=limϵ→01ϵP(x0≤x≤x0+x)
证明过程:

注
(a)误差e服从(0,σ2)的正态分布。则 每个di服从(f(xi),σ2)的正态分布,又由于概率di的表达式是在h为目标函数f的正确描述条件下的,所以μ=f(xi)=h(xi)
(b)第一项是独立于h的常数,忽略。
以上证明说明: 极大似然假设hML为:使训练值di和假设预测值h(xi)之间的误差平方和最小。
===========================================
贝叶斯最优分类器
之前我们考虑的是“给定训练数据,最可能的假设是什么?”,实际上,与之相关的问题是:给定训练数据,对新实例的最可能的分类是什么?
一般来说,新实例最可能的分类可通过合并所有假设的预测得到,用后验概率来加权,如果新样例的可能分类可取某集合V中的任一值vj, 那么概率P(vj|D)表示新实例的正确分类为vj的概率:
P(vj|D)=∑hi∈HP(vj|hi)P(hi|D)
新实例的最优分类为使P(vj|D)最大: 贝叶斯最优分类器
label=argmaxvj∈V∑hi∈HP(vj|hi)P(hi|D)
该分类器:使用相同的假设空间和相同的先验概率,没有其他方法能比其平均性能更好。该方法在给定可用数据、假设空间以及这些假设的先验概率下使新实例正确分类的可能性达到最大。
Gibbs算法
虽然贝叶斯最优分类器的性能很好,但是计算开销很大。原因在于:它要计算H中每个假设的后验概率,然后合并每个假设的预测以进行分类。
一个替换的算法:Gibbs算法
(1)按照H上的后验概率分布,从H中随机选择假设h
(2)使用h来预言下一实例x的分类。
===========================================
朴素贝叶斯分类器
朴素贝叶斯分类器应用的学习任务中,每个实例x可由属性值的合集描述,而目标函数f(x)从某个有限集合V中取值。学习器被提供一系列关于目标函数的训练样例以及新实例(描述为属性值的元组)<a1,a2,....an>然后进行预测分类得到目标值 vMAP。
vMAP=argmaxvj∈VP(vj|a1,a2,....an)
进过贝叶斯公式转化:
vMAP=argmaxvj∈VP(a1,a2,....an|vj)P(vj)
显然我们要做的就是求出上式的后面两个概率。P(vj) 很容易得出,只要计算每个目标值的vj出现在训练数据中出现的频率即可。而另一项在训练数据非常大的时候不太可行。
我们注意,朴素贝叶斯分类器有一个假设:在给定目标值时,属性值之间相互条件条件独立,也就是说,在给定目标属性值的情况下,观察到联合的a1,a2,....an的概率等于每个单独属性的概率之积:
P(a1,a2,....an|vj)=∏iP(ai|vj)
所以有:
vNB=argmaxvj∈VP(vj)∏iP(ai|vj)
概括得讲: 朴素贝叶斯学习方法需要估计不同的P(ai|vj) 和P(vj),基于它们在训练数据上的频率。只要所需的条件独立性能够被满足,朴素贝叶斯分类vNB等于MAP分类。
实例
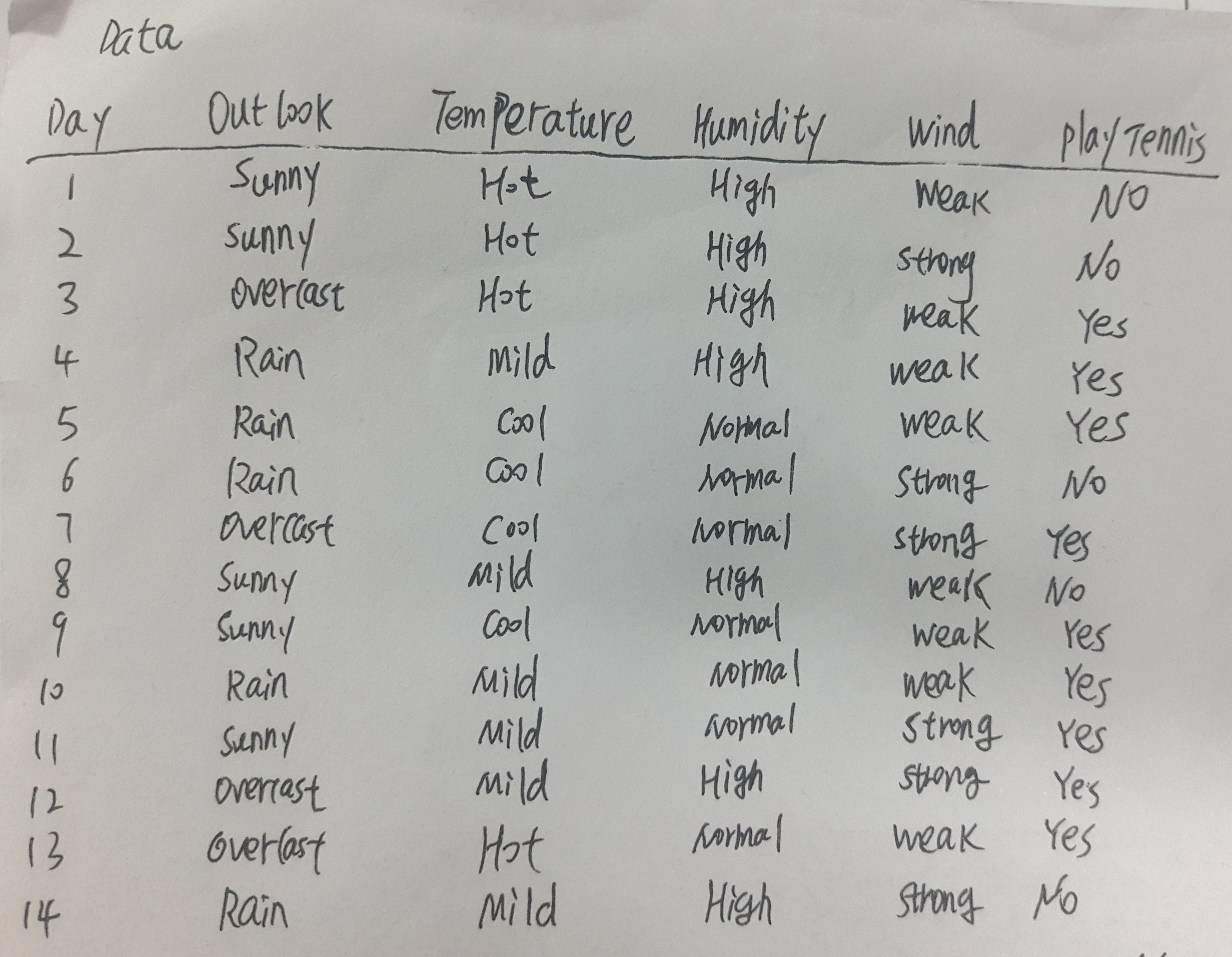
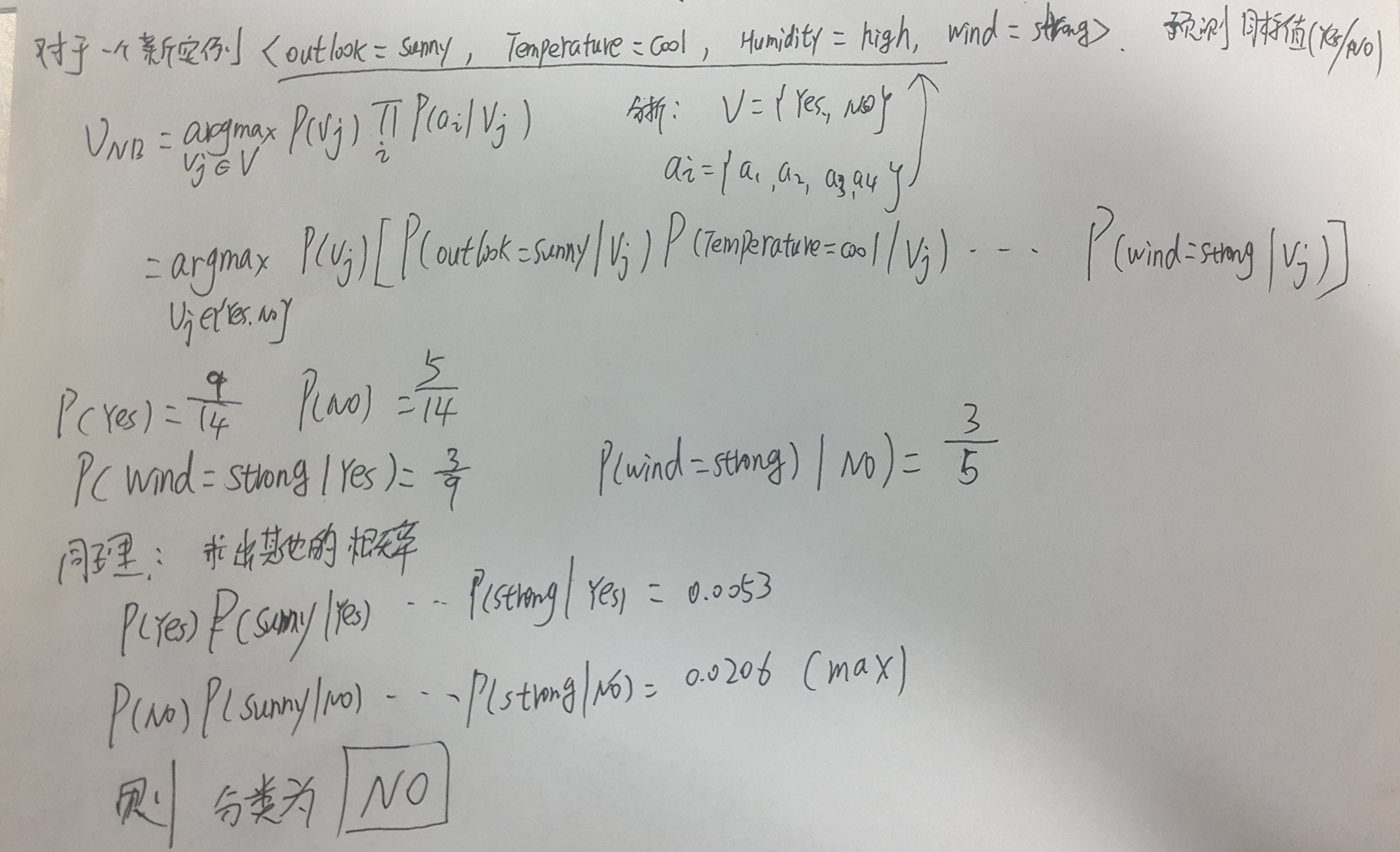
==============================================
估计概率
为力避免由于样例比较少时,我们通过频率来估计概率会不准确,为了避免这一问题,采用一种估计概率的贝叶斯方法,定义如下m-估计:
nc+mpn+m
p : 将要确定的概率的先验估计
m: 等效样本大小,它确定了对于观察到的数据如何衡量p的作用。在缺少其他的信息时,一般选择假定均匀的先验概率,如果某属性有k个可能值,那么设置p=1/k
1. 评估假设
2. 贝叶斯法则
3. 贝叶斯分类器
4. 实例分析
====================================
贝叶斯法则
贝叶斯推理提供一种推理的概率手段: 代考察的量遵循某概率分布,且可以根据这些概率以及已观察到的数据进行推理,以作出最优决策。
贝叶斯学习方法的特性:
1 观察到的每个训练样例可以增量的升高或降低某假设的估计概率。
2 先验知识和观察数据一起决定假设的最终概率。
3 贝叶斯方法允许作出不确定性的假设。
4 新的实例分类可由多个假设一起做出预测,用它们的概率来加权。
5 即使在贝叶斯方法计算复杂度较高时,它们仍可以作为一个最优决策的标准衡量其他方法。
在机器学习中,我们感兴趣的是:给定训练数据D时,确定假设空间H中的最佳假设。更精确的说: 贝叶斯法则提供了一种计算假设概率的方法,它基于假设的先验概率、 给定假设下观察到不同数据的概率以及观察到的数据本身。
我们先引入一些符号:
P(h) :没有训练数据前假设h拥有的初始概率。(常被称为先验概率,反映了我们所拥有的关于假设h是一正确假设的机会 的背景知识。如果没有这一知识,我们可以将每一个候选假设赋予相同的先验概率)
P(D): 将要观察的训练数据D的先验概率(在没有确定某一假设成立时,D的概率)
P(D|h): 假设h成立情况下,观察到数据D的概率。
P(h|D): (机器学习中感兴趣的)给定训练数据D时h成立的概率。(又被称为后验概率,反映了在看到训练数据D后h成立的置信度。)
注: 后验概率反映了训练数据D的影响,先验概率则是独立与D的。
贝叶斯公式:
P(h|D)=P(D|h)P(h)P(D)
提供了从先验概率P(h)以及P(D) P(D|h) 求得后验概率的方法。
在许多学习场景中,学习器考虑候选假设集合H并在其中寻找给定数据D时可能性最大的假设h(或者存在多个这样的假设时选择其中一个。)这样具有最大可能性的假设称为极大后验假设 MAP:
hMAP=argmaxh∈HP(h|D)=argmaxh∈HP(D|h)P(h)
在某些情况下可假设H中的每一个假设有相同的先验概率(对H中任意hi和hj有 P(hi)=P(hj)), 所以只需考虑P(D|h)来寻找极大可能假设。
P(D|h)常被称为给定h时数据D的似然度。而使P(D|h)最大的假设称为极大似然假设 ML
hML=argmaxh∈HP(D|h)
| 基本概率公式 | |
|---|---|
| 乘法规则 | P(AB)=P(A|B)P(B)=P(B|A)P(A) |
| 加法规则 | P(A+B)=P(A)+P(B)−P(AB) |
| 贝叶斯法则 | P(h|D)=P(D|h)P(h)P(D) |
| 全概率法则 | 如果事件A1,A2,,,An互斥,且∑ni=1P(Ai)=1则: P(B)=∑ni=1P(B|Ai)P(Ai) |

本节学习在连续值目标函数的问题。(神经网络线性回归、多项式曲线拟合)
在特定的前提下,任一学习算法如果是输出的假设预测和训练数据之间的平方误差最小化,它将输出一极大似然假设。
在实际的学习器中,对于每个训练样例<xi,di>, 每个目标值di是被随机噪声干扰的,而这个随机噪声一般遵循正态分布,即di=f(xi)+ei , 学习器的任务就是: 在所有假设有相同的先验概率前提下,输出极大似然假设(MAP)
讨论:
为什么 在任意实数值函数学习中,误差平方和最小假设即为极大似然假设。为了讨论像 e 这样连续变量上的概率,我们引入概率密度:
p(x0)=limϵ→01ϵP(x0≤x≤x0+x)
证明过程:
注
(a)误差e服从(0,σ2)的正态分布。则 每个di服从(f(xi),σ2)的正态分布,又由于概率di的表达式是在h为目标函数f的正确描述条件下的,所以μ=f(xi)=h(xi)
(b)第一项是独立于h的常数,忽略。
以上证明说明: 极大似然假设hML为:使训练值di和假设预测值h(xi)之间的误差平方和最小。
===========================================
贝叶斯最优分类器
之前我们考虑的是“给定训练数据,最可能的假设是什么?”,实际上,与之相关的问题是:给定训练数据,对新实例的最可能的分类是什么?
一般来说,新实例最可能的分类可通过合并所有假设的预测得到,用后验概率来加权,如果新样例的可能分类可取某集合V中的任一值vj, 那么概率P(vj|D)表示新实例的正确分类为vj的概率:
P(vj|D)=∑hi∈HP(vj|hi)P(hi|D)
新实例的最优分类为使P(vj|D)最大: 贝叶斯最优分类器
label=argmaxvj∈V∑hi∈HP(vj|hi)P(hi|D)
该分类器:使用相同的假设空间和相同的先验概率,没有其他方法能比其平均性能更好。该方法在给定可用数据、假设空间以及这些假设的先验概率下使新实例正确分类的可能性达到最大。
Gibbs算法
虽然贝叶斯最优分类器的性能很好,但是计算开销很大。原因在于:它要计算H中每个假设的后验概率,然后合并每个假设的预测以进行分类。
一个替换的算法:Gibbs算法
(1)按照H上的后验概率分布,从H中随机选择假设h
(2)使用h来预言下一实例x的分类。
===========================================
朴素贝叶斯分类器
朴素贝叶斯分类器应用的学习任务中,每个实例x可由属性值的合集描述,而目标函数f(x)从某个有限集合V中取值。学习器被提供一系列关于目标函数的训练样例以及新实例(描述为属性值的元组)<a1,a2,....an>然后进行预测分类得到目标值 vMAP。
vMAP=argmaxvj∈VP(vj|a1,a2,....an)
进过贝叶斯公式转化:
vMAP=argmaxvj∈VP(a1,a2,....an|vj)P(vj)
显然我们要做的就是求出上式的后面两个概率。P(vj) 很容易得出,只要计算每个目标值的vj出现在训练数据中出现的频率即可。而另一项在训练数据非常大的时候不太可行。
我们注意,朴素贝叶斯分类器有一个假设:在给定目标值时,属性值之间相互条件条件独立,也就是说,在给定目标属性值的情况下,观察到联合的a1,a2,....an的概率等于每个单独属性的概率之积:
P(a1,a2,....an|vj)=∏iP(ai|vj)
所以有:
vNB=argmaxvj∈VP(vj)∏iP(ai|vj)
概括得讲: 朴素贝叶斯学习方法需要估计不同的P(ai|vj) 和P(vj),基于它们在训练数据上的频率。只要所需的条件独立性能够被满足,朴素贝叶斯分类vNB等于MAP分类。
实例
==============================================
估计概率
为力避免由于样例比较少时,我们通过频率来估计概率会不准确,为了避免这一问题,采用一种估计概率的贝叶斯方法,定义如下m-估计:
nc+mpn+m
p : 将要确定的概率的先验估计
m: 等效样本大小,它确定了对于观察到的数据如何衡量p的作用。在缺少其他的信息时,一般选择假定均匀的先验概率,如果某属性有k个可能值,那么设置p=1/k

相关文章推荐
- 贝叶斯学习 -- matlab、python代码分析(3)
- 贝叶斯学习 -- matlab、python代码分析(1)
- MATLAB深度学习代码详细分析(一)__nnff.m
- 机器学习之一:logistic回归分析(含Matlab代码)
- 无监督学习之K-均值算法分析与MATLAB代码实现
- [深度学习]Python/Theano实现逻辑回归网络的代码分析
- 《Python 黑帽子》学习笔记 - 原书 netcat 代码分析 - Day 7
- 28. Python脚本学习笔记二十八代码检测和分析
- Dive Into Python 学习记录3-对获取某文件夹下MP3文件信息的代码构成分析
- [深度学习]Python/Theano实现逻辑回归网络的代码分析
- python正则表达式分析新浪网天气预报,通过pyfetion发送短信的代码
- BT源代码学习心得(八):跟踪服务器(Tracker)的代码分析(用户请求的实际处理) - 转贴自 wolfenstein (NeverSayNever)
- EasyARM2200开发板学习笔记:启动代码分析
- 贝叶斯网络的构建-学习-推理(C++源代码)分析
- Python网络编程的一些代码片断与分析
- Servlet学习——分析一牛同事的代码
- python 域名分析工具实现代码
- Python 文件操作技巧(File operation) 实例代码分析
- MFC OnFileNew OnFileOpen过程分析代码(以记录MFC学习点滴)
- (python)通过一个代码例子来分析对象的生命周期