CS231n-KNN模型分类Cifar10
2016-11-19 22:11
369 查看
图像识别流程
可视化Cifar10数据集
构建KNN模型
计算欧式距离
预测分类
交叉验证
训练评估完整数据模型
完整代码
从效果看来,KNN并不适合图像识别,它的识别更多基于背景,而不是图片的语义主体。所以在实际应用中我们一般不适用KNN识别图像,但是在学习过程中,通过KNN算法我们可以学习到图像识别的整个流程,对我们的帮助是非常大的
输入图像:一般来说,输入的是图像的像素值
训练模型:通过输入的图像来训练模型
评价模型:用测试数据来测试模型的分类能力从而评估模型的泛化能力
在训练模型阶段,由于很多模型都会有或多或少的参数需要设定(这些参数我们称为“超参”),所以我们需要增加一些步骤来确定这些参数,比如验证集或者交叉验证等方法,这些在接下来都会提到
可视化的效果如下:

那么什么叫做最相邻呢?即两个像素点越接近越相邻,这里我们用L2-范式(欧氏距离)来比较像素的接近程度,然后逐个像素比较,最后将差异值全部加起来得到两幅图像接近程度。
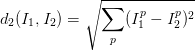
我们有很多方式可以实现这个公式,比如我们可以采取每一个测试集和每一个训练集分别计算欧氏距离的方式(即嵌套for循环),也可以用向量化的方式实现(numpy科学计算库,涉及到矩阵计算)。而事实上逐一计算方式所需的时间大概师向量化的实现的几百倍,所以我们要尽量使用向量化实现。向量化实现的思路是:
python代码实现如下:
这里注意一下,因为python的广播无法将(5000 x 500)的数组和(500,)的向量相加,所以我们有两种选择,一种是将向量先转成矩阵转置后相加,最后再转回数组,另一种就是设置关键字参数keepdims=True,它可以保证python的广播机制正确执行
python实现如下:
np.argsort:获取数组从小到大排列的索引
np.bincount:统计数组中每个值出现的次数
np.argmax:获取数组中值最大的索引
在上述的代码中,我们需要对每一个K的取值进行对5种训练集计算正确率,我们对得到的结果构建误差棒图得到以下效果

对得到的数据计算算术平均值,作出以上误差棒图,从图中我们可以看出当K值取10左右的正确率为最高
可视化Cifar10数据集
构建KNN模型
计算欧式距离
预测分类
交叉验证
训练评估完整数据模型
完整代码
从效果看来,KNN并不适合图像识别,它的识别更多基于背景,而不是图片的语义主体。所以在实际应用中我们一般不适用KNN识别图像,但是在学习过程中,通过KNN算法我们可以学习到图像识别的整个流程,对我们的帮助是非常大的
图像识别流程
无论是哪种分类算法,图像识别的流程主要为以下流程输入图像:一般来说,输入的是图像的像素值
训练模型:通过输入的图像来训练模型
评价模型:用测试数据来测试模型的分类能力从而评估模型的泛化能力
在训练模型阶段,由于很多模型都会有或多或少的参数需要设定(这些参数我们称为“超参”),所以我们需要增加一些步骤来确定这些参数,比如验证集或者交叉验证等方法,这些在接下来都会提到
可视化Cifar10数据集
在下载完 cifar10数据集 后,我们首先需要读取cifar10数据集中的数据,这个我就不多介绍了,网上应该也有很多,注意Python版本就可以了,这里使用Python3.5。然后我们随机抽取一部分图像进行可视化def VisualizeImage(X_train, y_train):
"""可视化数据集
:param X_train: 训练集
:param y_train: 训练标签
:return:
"""
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 8
for y, cls in enumerate(classes):
# 得到该标签训练样本下标索引
idxs = np.flatnonzero(y_train == y)
# 从某一分类的下标中随机选择8个图像(replace设为False确保不会选择到同一个图像)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
# 将每个分类的8个图像显示出来
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
# 创建子图像
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
# 增加标题
if i == 0:
plt.title(cls)
plt.show()可视化的效果如下:
构建KNN模型
一般构造机器学习模型,我们需要定义训练以及测试函数,而KNN模型是无需训练的,所以我们主要步骤在于预测功能,它的思路很简单:| 如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。 |
计算欧式距离
它的公式如下:我们有很多方式可以实现这个公式,比如我们可以采取每一个测试集和每一个训练集分别计算欧氏距离的方式(即嵌套for循环),也可以用向量化的方式实现(numpy科学计算库,涉及到矩阵计算)。而事实上逐一计算方式所需的时间大概师向量化的实现的几百倍,所以我们要尽量使用向量化实现。向量化实现的思路是:
| 因为一张图片我们一般会将它reshape到一个一维向量,所以对于两张图片的距离就是计算两个向量之间的欧氏距离。我们将欧氏距离公式展开,我们可以得到两个向量之间的距离为x^2 - 2xy + y^2 (X, Y分别代表一个向量,也就是一张图片), 这样我们就可以用矩阵的方式求解了。 |
def compute_distances(self, X_test): """计算测试集和每个训练集的欧氏距离 向量化实现需转化公式后实现(单个循环不需要) :param X_test: 测试集 numpy.ndarray :return: 测试集与训练集的欧氏距离数组 numpy.ndarray """ dists = np.zeros((X_test.shape[0], self.X_train.shape[0])) value_2xy = np.multiply(X_test.dot(self.X_train.T), -2) value_x2 = np.sum(np.square(X_test), axis=1, keepdims=True) value_y2 = np.sum(np.square(self.X_train), axis=1) dists = value_2xy + value_x2 + value_y2 return dists
这里注意一下,因为python的广播无法将(5000 x 500)的数组和(500,)的向量相加,所以我们有两种选择,一种是将向量先转成矩阵转置后相加,最后再转回数组,另一种就是设置关键字参数keepdims=True,它可以保证python的广播机制正确执行
预测分类
原理也很简单:| 根据上述计算的欧氏距离,对于每一个需要预测的样本,我们取前K个最接近的训练数据的分类,然后将这些分类中个数最多的分类作为预测结果. |
def predict_label(self, dists, k): """选择前K个距离最近的标签,从这些标签中选择个数最多的作为预测分类 :param dists: 欧氏距离 :param k: 前K个分类 :return: 预测分类(向量) """ y_pred = np.zeros(dists.shape[0]) for i in range(dists.shape[0]): # 取前K个标签 closest_y = self.y_train[np.argsort(dists[i, :])[:k]] # 取K个标签中个数最多的标签 y_pred[i] = np.argmax(np.bincount(closest_y)) return y_pred
np.argsort:获取数组从小到大排列的索引
np.bincount:统计数组中每个值出现的次数
np.argmax:获取数组中值最大的索引
交叉验证
在我们训练完整数据集之前,我们必须先确定超参的值,这里我是用交叉验证方法,该方法主要思路为将训练集分为n份,然后每份分别作为测试集,剩下的作为训练集来检验不同的超参的效果,它适用于数据集较少的情况,因为交叉验证训练次数比较多,所以n的值不宜取过大,我们一般取5-10就可以了;如果数据集够大,我们可以使用验证集的方式,即从训练集取一小部分作为验证集来检验不同超参的效果,这样我们所需的训练次数就会少很多了。代码如下def Cross_validation(X_train, y_train):
"""交叉验证,确定超参K,同时可视化K值
:param X_train: 训练集
:param y_train: 训练标签
"""
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
k_accuracy = {}
# 将数据集分为5份
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
# 计算每种K值
for k in k_choices:
k_accuracy[k] = []
# 每个K值分别计算每份数据集作为测试集时的正确率
for index in range(num_folds):
# 构建数据集
X_te = X_train_folds[index]
y_te = y_train_folds[index]
X_tr = np.reshape(X_train_folds[:index] + X_train_folds[index + 1:], (X_train.shape[0] * (num_folds - 1) / num_folds, -1))
y_tr = np.reshape(y_train_folds[:index] + y_train_folds[index + 1:], (X_train.shape[0] * (num_folds - 1) / num_folds))
# 预测结果
classify = KNearestNeighbor()
classify.train(X_tr, y_tr)
y_te_pred = classify.predict(X_te, k=k)
accuracy = np.sum(y_te_pred == y_te) / float(X_te.shape[0])
k_accuracy[k].append(accuracy)
for k, accuracylist in k_accuracy.items():
for accuracy in accuracylist:
print("k = %d, accuracy = %.3f" % (k, accuracy))在上述的代码中,我们需要对每一个K的取值进行对5种训练集计算正确率,我们对得到的结果构建误差棒图得到以下效果
对得到的数据计算算术平均值,作出以上误差棒图,从图中我们可以看出当K值取10左右的正确率为最高
训练评估完整数据模型
当我们确定了超参以后,我们就可以将完整的数据进行训练了,由于KNN在数据集比较大的时候(图片的数据维度很大)计算量特别大,所以我将5000个数据作为完整训练集,500个数据作为测试集(50000个训练集和10000个训练集在我的电脑不能正常运行,内存崩溃)。在上述数据中我得到的结果是正确率为28.2%,虽然识别率比较低,但这应该是个比较正常的结果,我们在使用KNN识别图片之前就应该明白它的识别率不会很高完整代码
由于代码比较多,为了控制篇幅,主要代码以上都已经贴上了,完整代码见 githubCS231n
相关文章推荐
- cs231n作业一之 在cifar-10上实现KNN
- Deep Learning-TensorFlow (4) CNN卷积神经网络_CIFAR-10进阶图像分类模型(上)
- 用KNN算法分类CIFAR-10图片数据
- Deep Learning-TensorFlow (5) CNN卷积神经网络_CIFAR-10进阶图像分类模型(下)
- 从CIFAR-10手工分类中学到的经验教训Lessons learned from manually classifying CIFAR-10
- CS231n课程笔记2.1:图像分类问题简介&KNN
- Tensorflow实现CIFAR-10分类问题-详解三cifar10_input.py
- CS231n 笔记一(lecture 2)(KNN、线性分类)
- 利用pytorch对CIFAR-10数据集的分类
- cs231n 卷积神经网络与计算机视觉 1 基础梳理与KNN图像分类
- 【深度学习】针对CIFAR-10模型所写的进行图片size,图片名,后缀图片格式写的预处理程序
- CIFAR-10模型训练python版cifar10数据集
- tensorflow学习笔记----二(CIFAR-10 模型 )
- Pytorch打怪路(一)pytorch进行CIFAR-10分类(5)测试
- Nearest Neighbor算法对Cifar-10数据集进行分类
- tensorflow 学习之 cifar_10 模型定义 4000
- CIFAR-10训练模型
- 深度学习与媒体计算②——kNN的优化与线性分类 (CS231n)
- Pytorch打怪路(一)pytorch进行CIFAR-10分类(1)CIFAR-10数据加载和处理
- 【深度学习】笔记7: CNN训练Cifar-10技巧 ---如何进行实验,如何进行构建自己的网络模型,提高精度