推荐系统的粗浅认识
2016-11-18 12:56
169 查看
注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
说到推荐系统,可以毫不夸张的说,基本每个使用互联网的人多少都见到过,从购物网站到社区,可谓无孔不入啊。
既然是推荐系统,那么它是凭什么把某一物品、文章等推荐给你的呢?说到这,就必须的谈到一个问题:距离的度量,因为只有找到跟用户喜好相似的才能推荐嘛。距离度量的方式有很多种,在我的一篇文章聚类中已经介绍完了,大家要是不熟悉的话不妨了解一下。
首先要谈的就是推荐系统的几个指标,这也是谈推荐系统绕不开的几个问题:
记:R(u)是给用户u做出的推荐列表,而T(u)是用户在测试集上真正的行为列表。
准确率:
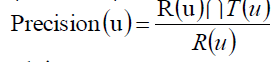
召回率:
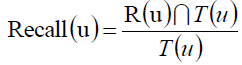
这两个标准一个是偏重推荐的准确率,一个偏重用户的召回率,各有道理吧,具体的还要看实际情况。
我们不妨借鉴Jaccard系数:
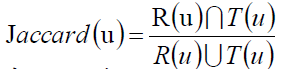
当然了,我们也可以计算一个系统整体准确率:
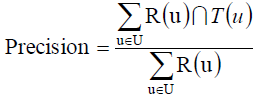
整体召回率:
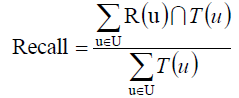
最终我们可以推出一个比较合理的综合评价:

如果我们更看重召回率,我们就让β增大,反之调小β即可,还是比较有道理的。
当然了,上边说的这些指标都是离线指标,真正的线上测试不是这样做的,而是使用AB测试或者其他方式。
除此之外,我们还可以考察一个推荐系统商品的覆盖率:
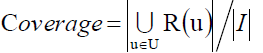
因为如果一个推荐系统的某些商品没人点击,我们又不推荐的话,很有可能更加冷,导致马太效应。
当然了,我们可以用信息熵、基尼系数来衡量一个商品出现大的次数:
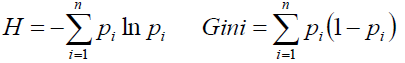
另外,惊喜度也是一种指标:满意度、相似度。因为是这样的,我是搞机器学习的,我浏览商城经常看机器学习的书,系统也总是给我推荐机器学习的书,虽然说没什么错,但是没什么惊喜度,如果这时候推荐给我一本《挪威的森林》或者直接是机器人的话我们也许会很喜欢。
协同过滤算法:
基于用户行为的数据而设计的推荐算法被称为协同过滤算法(Collaborative Filtering, CF)。
协同过滤可以基于用户也可以基于商品。
基于用户:
我们拿电影为例,假定A看了50部电影,我们就可用Jaccard相似度来度量其他用户根A的相似度,如果相似度比较高,那么可以将A看过但是其他人没看过的电影作为推荐列表。
但是其实这样做多少有些不合理,因为假如有的电影特别火,我们都看过,其实说明不了什么,如果有的电影比较冷门,并且我们都看过,这倒是可以一定程度说明我们可能很相似,我们可以将这些冷门的电影加大权重,再进行相似度比较。
当然了,不光可以使用Jaccard相似度来衡量,还有夹角余弦等其他的衡量方式。
基于商品:
我们不妨还用电影来举例子,某部电影A,假如有1,2,3,4,5,6这六个人看过,电影B有3,4,5,6,7,8看过,并且我们直到A和B电影的类型或者相似度比较高,那么我们就可把A电影推荐给7,8这两个人,把B电影推荐给1,2这两个人,很经典的倒排索引。
随机游走算法
因为我个人对图论的了解还是少一些,所以我就多介绍一些关于图轮的方法,听起来感觉挺别扭。。。
假定只有4个用户、5个商品,我们整理出用户ABCD,对商品abcde的喜欢列表,得到二部图:
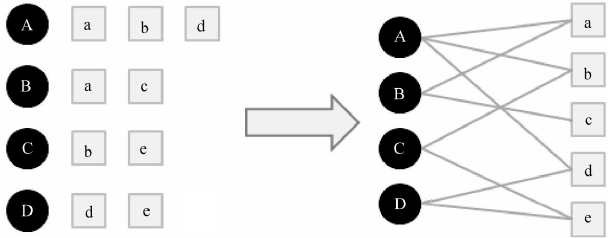
我们可以分析最短路径,越近就表示越喜欢嘛:
其中我们发现A到c和A到e是没有路径的,那么怎么评价更喜欢谁呢?
我们其实可以从A-a-B-c到达也就是3步,那么A-b-C-e也是3步啊,但是还有A-d-D-e呢,也就是说如果最短路径一样长,那么看谁的最短路径多嘛,就像你如果你更喜欢另外一个女孩子,你会各种途径接近她。嘿嘿嘿
基于隐变量的推荐 - LFM(Latent Factor Model)
当然了,推荐的方法肯定不止这几种,我们设想一下这样一个场景,Ben,Tom,John,Fred对六种商品进行了评价,评分越高代表对该商品越喜欢,0表示未评价。
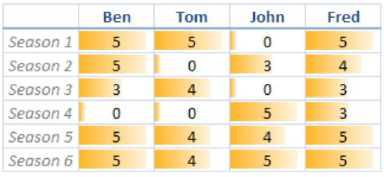
我们可以转化为矩阵A表示:
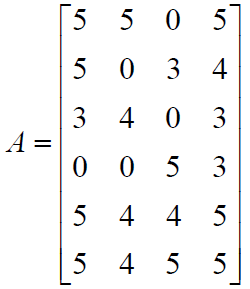
我们不妨假定用户根据啥给评的分,假如这个商品是火龙果,那么用户对它评分肯定根据什么评得呀,假如根据产地、价格、口感、包装。。。。等等,假设现在有3个隐变量产地、价格、口感,那么我们可以将这个6*4得矩阵分解一下,分成6*3得商品-隐变量矩阵和3*4的隐变量-用户矩阵,我们回头看看这么分解合不合理。
首先,我们的用户之所以喜欢一个商品,肯定是有理由的吧,比如喜欢价格便宜、产地在三亚、口感丝滑,可能根据这几个指标给商品评了5分;那么一个商品有3个主要的属性价格、产地、口感,这也很有道理吧,既然如此,那么我们就有理由将这个矩阵分解掉:
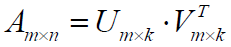
接着我们用拉格朗日乘子法建立目标函数:
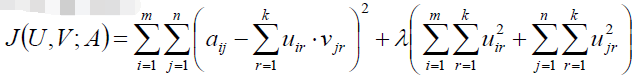
我们对u和v求偏导:
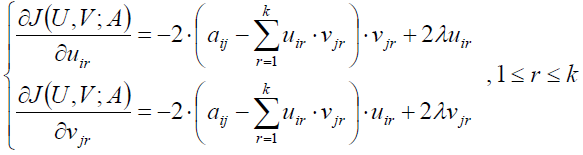
那么我们就可以根据梯度不断的优化直到收敛。
最后得到用户-隐变量矩阵:

商品-隐变量矩阵:

当然了,这里的k取得是2,也就是我们先验性的认为有两个让用户投票的原因。k是需要交叉验证的,或者根据领域知识来确定。
另外如果在矩阵分解过程中,有负权值的话,虽然可以解释,然是需要避免。
到此推荐系统的粗浅介绍就结束了,欢迎批评指正!
说到推荐系统,可以毫不夸张的说,基本每个使用互联网的人多少都见到过,从购物网站到社区,可谓无孔不入啊。
既然是推荐系统,那么它是凭什么把某一物品、文章等推荐给你的呢?说到这,就必须的谈到一个问题:距离的度量,因为只有找到跟用户喜好相似的才能推荐嘛。距离度量的方式有很多种,在我的一篇文章聚类中已经介绍完了,大家要是不熟悉的话不妨了解一下。
首先要谈的就是推荐系统的几个指标,这也是谈推荐系统绕不开的几个问题:
记:R(u)是给用户u做出的推荐列表,而T(u)是用户在测试集上真正的行为列表。
准确率:
召回率:
这两个标准一个是偏重推荐的准确率,一个偏重用户的召回率,各有道理吧,具体的还要看实际情况。
我们不妨借鉴Jaccard系数:
当然了,我们也可以计算一个系统整体准确率:
整体召回率:
最终我们可以推出一个比较合理的综合评价:
如果我们更看重召回率,我们就让β增大,反之调小β即可,还是比较有道理的。
当然了,上边说的这些指标都是离线指标,真正的线上测试不是这样做的,而是使用AB测试或者其他方式。
除此之外,我们还可以考察一个推荐系统商品的覆盖率:
因为如果一个推荐系统的某些商品没人点击,我们又不推荐的话,很有可能更加冷,导致马太效应。
当然了,我们可以用信息熵、基尼系数来衡量一个商品出现大的次数:
另外,惊喜度也是一种指标:满意度、相似度。因为是这样的,我是搞机器学习的,我浏览商城经常看机器学习的书,系统也总是给我推荐机器学习的书,虽然说没什么错,但是没什么惊喜度,如果这时候推荐给我一本《挪威的森林》或者直接是机器人的话我们也许会很喜欢。
协同过滤算法:
基于用户行为的数据而设计的推荐算法被称为协同过滤算法(Collaborative Filtering, CF)。
协同过滤可以基于用户也可以基于商品。
基于用户:
我们拿电影为例,假定A看了50部电影,我们就可用Jaccard相似度来度量其他用户根A的相似度,如果相似度比较高,那么可以将A看过但是其他人没看过的电影作为推荐列表。
但是其实这样做多少有些不合理,因为假如有的电影特别火,我们都看过,其实说明不了什么,如果有的电影比较冷门,并且我们都看过,这倒是可以一定程度说明我们可能很相似,我们可以将这些冷门的电影加大权重,再进行相似度比较。
当然了,不光可以使用Jaccard相似度来衡量,还有夹角余弦等其他的衡量方式。
基于商品:
我们不妨还用电影来举例子,某部电影A,假如有1,2,3,4,5,6这六个人看过,电影B有3,4,5,6,7,8看过,并且我们直到A和B电影的类型或者相似度比较高,那么我们就可把A电影推荐给7,8这两个人,把B电影推荐给1,2这两个人,很经典的倒排索引。
随机游走算法
因为我个人对图论的了解还是少一些,所以我就多介绍一些关于图轮的方法,听起来感觉挺别扭。。。
假定只有4个用户、5个商品,我们整理出用户ABCD,对商品abcde的喜欢列表,得到二部图:
我们可以分析最短路径,越近就表示越喜欢嘛:
其中我们发现A到c和A到e是没有路径的,那么怎么评价更喜欢谁呢?
我们其实可以从A-a-B-c到达也就是3步,那么A-b-C-e也是3步啊,但是还有A-d-D-e呢,也就是说如果最短路径一样长,那么看谁的最短路径多嘛,就像你如果你更喜欢另外一个女孩子,你会各种途径接近她。嘿嘿嘿
基于隐变量的推荐 - LFM(Latent Factor Model)
当然了,推荐的方法肯定不止这几种,我们设想一下这样一个场景,Ben,Tom,John,Fred对六种商品进行了评价,评分越高代表对该商品越喜欢,0表示未评价。
我们可以转化为矩阵A表示:
我们不妨假定用户根据啥给评的分,假如这个商品是火龙果,那么用户对它评分肯定根据什么评得呀,假如根据产地、价格、口感、包装。。。。等等,假设现在有3个隐变量产地、价格、口感,那么我们可以将这个6*4得矩阵分解一下,分成6*3得商品-隐变量矩阵和3*4的隐变量-用户矩阵,我们回头看看这么分解合不合理。
首先,我们的用户之所以喜欢一个商品,肯定是有理由的吧,比如喜欢价格便宜、产地在三亚、口感丝滑,可能根据这几个指标给商品评了5分;那么一个商品有3个主要的属性价格、产地、口感,这也很有道理吧,既然如此,那么我们就有理由将这个矩阵分解掉:
接着我们用拉格朗日乘子法建立目标函数:
我们对u和v求偏导:
那么我们就可以根据梯度不断的优化直到收敛。
最后得到用户-隐变量矩阵:
商品-隐变量矩阵:
当然了,这里的k取得是2,也就是我们先验性的认为有两个让用户投票的原因。k是需要交叉验证的,或者根据领域知识来确定。
另外如果在矩阵分解过程中,有负权值的话,虽然可以解释,然是需要避免。
到此推荐系统的粗浅介绍就结束了,欢迎批评指正!

相关文章推荐
- 【推荐】解析Linux系统根文件系统的目录树,让你对linux更深的认识
- 关于用SQL SERVER2000建立分布式网站系统的认识
- 彻底明白JAVA的IO系统-1(认识File)
- 真诚推荐:我写的免疫32种如3721、百度垃圾组件的系统工具! (摘自博客园)
- 认识VB的文件系统对象--FSO
- java Blog系统推荐-roller
- VS.NET环境下实现日志系统的几种方式 推荐
- 推荐一个非常不错的.NET系统--C1协同平台
- 推荐一本好书《深入理解计算机系统 Ccomputer Systems A Programmer's Perspective》
- [推荐]网络上通用的调查答卷系统-XML做数据库(将DataSet转化成字符串)
- 认识 VB 的文件系统对象 FSO
- [遁去的一推荐]软件测试认识的几个误区(中国软件测试社区提供)
- 系统分析书籍推荐
- [下载]好东西怎能不分享?推荐一个内容管理系统!
- 推荐一个WINDOWS系统文件介绍的网站
- 嵌入式系统好书推荐
- 蛙蛙推荐:偶做的用户管理系统
- [温润推荐]计算机系统集成项目管理
- 推荐几张系统维护光盘
- 【蛙蛙推荐】:由改进一个老旧系统想到的