hiho一下 第三十九周 #1141 : 二分·归并排序之逆序对 【归并排序----树状数组】
2016-11-17 22:03
369 查看
#1141 : 二分·归并排序之逆序对
时间限制:10000ms单点时限:1000ms
内存限制:256MB
描述
在上一回、上上回以及上上上回里我们知道Nettle在玩《艦これ》。经过了一番苦战之后,Nettle又获得了的很多很多的船。这一天Nettle在检查自己的舰队列表:
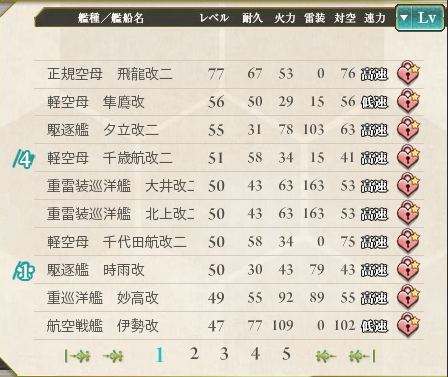
我们可以看到,船默认排序是以等级为参数。但实际上一个船的火力值和等级的关系并不大,所以会存在A船比B船等级高,但是A船火力却低于B船这样的情况。比如上图中77级的飞龙改二火力就小于55级的夕立改二。
现在Nettle将按照等级高低的顺序给出所有船的火力值,请你计算出一共有多少对船满足上面提到的这种情况。
提示:火力高才是猛!
输入
第1行:1个整数N。N表示舰船数量, 1≤N≤100,000第2行:N个整数,第i个数表示等级第i低的船的火力值a[i],1≤a[i]≤2^31-1。
输出
第1行:一个整数,表示有多少对船满足“A船比B船等级高,但是A船火力低于B船”。样例输入
10 1559614248 709366232 500801802 128741032 1669935692 1993231896 369000208 381379206 962247088 237855491
样例输出
27
×
提示:火力高才是猛!
拿到这道题目,可以很容易想到两重For循环枚举,复杂度为O(N^2),对于1000ms的时限来说显然会TLE。既然是分治专题,这题必然和分治相关咯?
没错。这道题需要用到的是长期被我们忽略的归并排序。
我们来看一个归并排序的过程:
给定的数组为[2, 4, 5, 3, 1],二分后的数组分别为[2, 4, 5], [1, 3],假设我们已经完成了子过程,现在进行到该数组的“并”操作:
| a: [2, 4, 5] | b: [1, 3] | result:[1] | 选取b数组的1 | |||
| a: [2, 4, 5] | b: [3] | result:[1, 2] | 选取a数组的2 | |||
| a: [4, 5] | b: [3] | result:[1, 2, 3] | 选取b数组的3 | |||
| a: [4, 5] | b: [] | result:[1, 2, 3, 4] | 选取a数组的4 | |||
| a: [5] | b: [] | result:[1, 2, 3, 4, 5] | 选取a数组的5 |
在原数组中,b数组中的元素位置一定在k之后,也就是说k和这些元素均构成了逆序对。
那么在放入a数组中的元素时,我们通过计算result中b数组的元素个数,就可以计算出对于k来说,b数组中满足逆序对的个数。
又因为递归的过程中,a数组中和k满足逆序对的数也计算过。则在该次递归结束时,[2, 4, 5, 3, 1]中所有k的逆序对个数也就都统计了。
同理对于a中其他的元素也同样有这样的性质。
由于每一次的归并过程都有着同样的情况,则我们可以很容易推断出:
若将每一次合并过程中得到的逆序对个数都加起来,即可得到原数组中所有逆序对的总数。
即在一次归并排序中计算出了所有逆序对的个数,时间复杂度为O(NlogN)
另外,逆序对的计算还有一种同样O(NlogN)的算法,使用的是树状数组,有兴趣的话可以自行搜索一下资料。
归并排序代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
struct node{
int hao,shu,zz;
}p[120000];
int ss[1200000],s2[1200000];
bool cmp1(node x,node y)
{
return x.shu<y.shu;
}
bool cmp2(node x,node y)
{
return x.hao<y.hao;
}
long long ans;
void SS(int l,int r)
{
if (l==r)
return ;
int m=(l+r)>>1;
SS(l,m);SS(m+1,r);
int a=l,b=m+1;
for (int i=l;i<=r;i++)
{
if (a==m+1)
s2[i]=ss[b++];
else if (b==r+1)
s2[i]=ss[a++];
else if (ss[a]<=ss[b])
{
s2[i]=ss[a++];
}
else
{
ans+=b-i;
s2[i]=ss[b++];
}
}
for (int i=l;i<=r;i++)
ss[i]=s2[i];
return ;
}
int main()
{
int n;scanf("%d",&n);
for (int i=0;i<n;i++)
{
scanf("%d",&p[i].shu);
p[i].hao=i;
}
sort(p,p+n,cmp1);
p[0].zz=1;
int lp=1;
for (int i=1;i<n;i++)
{
if (p[i].shu!=p[i-1].shu)
lp++;
p[i].zz=lp;
}
sort(p,p+n,cmp2);
ans=0;
for (int i=0;i<n;i++)
ss[i]=p[i].zz;
SS(0,n-1);
printf("%lld\n",ans);
return 0;
}
树状数组代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
struct node{
int hao,shu,zz;
}p[120000];
bool cmp1(node x,node y)
{
return x.shu<y.shu;
}
bool cmp2(node x,node y)
{
return x.hao>y.hao;
}
int lp,SHU[120000];
void add(int x)
{
for (;x<=lp;x+=(-x&x))
SHU[x]++;
}
int query(int x)
{
int ans=0;
for (;x>0;x-=(-x&x))
ans+=SHU[x];
return ans;
}
int main()
{
int n;scanf("%d",&n);
for (int i=0;i<n;i++)
{
scanf("%d",&p[i].shu);
p[i].hao=i;
}
sort(p,p+n,cmp1);
p[0].zz=1;
lp=1;
for (int i=1;i<n;i++)
{
if (p[i].shu!=p[i-1].shu)
lp++;
p[i].zz=lp;
}
for (int i=0;i<=lp;i++)
SHU[i]=0;
sort(p,p+n,cmp2);
long long ans=0;
for (int i=0;i<n;i++)
{
ans+=query(p[i].zz-1);
add(p[i].zz);
}
printf("%lld\n",ans);
return 0;
}

相关文章推荐
- #1141 : 二分·归并排序之逆序对(归并排序)
- POJ 2299 Ultra-QuickSort 【归并排序 || 树状数组求逆序对数】
- poj2299Ultra-QuickSort【树状数组求逆序数、离散化】、【归并排序模板】
- 【hiho39】二分·归并排序之逆序对
- POJ 2299 Ultra-QuickSort 【归并排序求逆序数 OR 树状数组求逆序数】
- HiHoCoder-第三十九周--二分·归并排序之逆序对
- [洛谷P1908] 逆序对|归并排序|树状数组
- hihoCoder 1141 二分·归并排序之逆序对
- Inversion (hdu 4911 树状数组 || 归并排序 求逆序对)
- 1348:数组中的逆序对(树状数组 or 归并)
- 归并排序,树状数组 两种方法求逆序对
- hdoj 1394 Minimum Inversion Number 【线段树 or 线段树lazy or 树状数组 or 归并排序】【逆序对】
- E - Inversion-归并排序求逆序对/树状数组求逆序对
- ACM:归并排序,以及利用归并排序思想求解逆序对数!
- poj 2299 求逆序对 树状数组 归并排序
- 求逆序对模板题(完善模板:树状数组或归并排序)
- NYOJ 117 求逆序数 【树状数组】或【归并排序】
- 利用归并排序思想求数组中的逆序对
- poj2299 Ultra-QuickSort&&NYOJ117 求逆序数 (树状数组求逆序对数+离散化)+(归并排序)
- Ultra-QuickSort (poj 2299 归并排序 || 树状数组 求逆序对)