READING NOTE: Aggregated Residual Transformations for Deep Neural Networks
2016-11-17 21:40
681 查看
TITLE: Aggregated Residual Transformations for Deep Neural Networks
AUTHOR: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
ASSOCIATION: UC San Diego, Facebook AI Research
FROM: arXiv:1611.05431
if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes).
each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2. The second rule ensures that the computational complexity, in terms of FLOPs is roughly the same for all blocks.
The building block of ResNeXt is shown in the following figure:
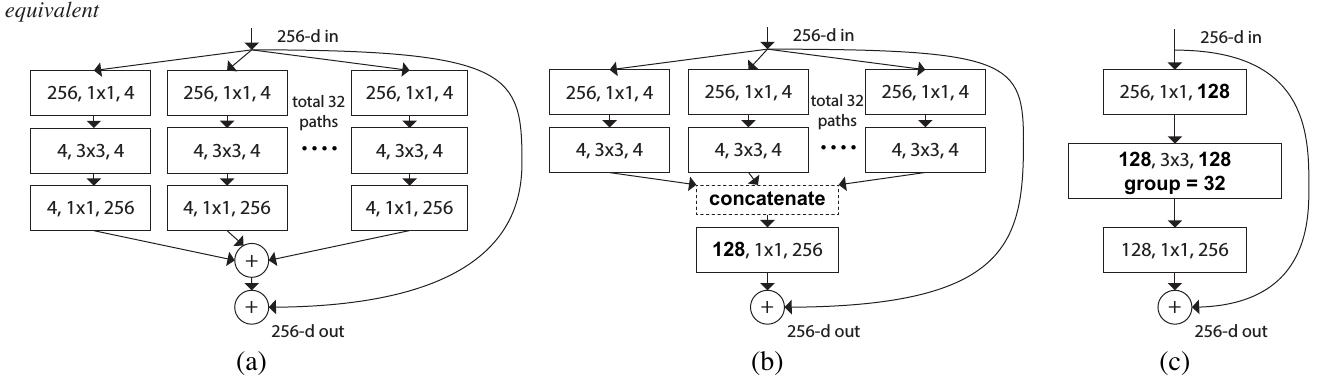
Such design will make the network having more channels (sets of transformations) without increasing much FLOPs, which is claimed as the increasing of ardinality.
AUTHOR: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
ASSOCIATION: UC San Diego, Facebook AI Research
FROM: arXiv:1611.05431
CONTRIBUTIONS
A simple, highly modularized network (ResNeXt) architecture for image classification is proposed. The network is constructed by repeating a building block that aggregates a set of transformations with the same topology.METHOD
The network is designed with two simple rules inspired by VGG/ResNets:if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes).
each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2. The second rule ensures that the computational complexity, in terms of FLOPs is roughly the same for all blocks.
The building block of ResNeXt is shown in the following figure:
Such design will make the network having more channels (sets of transformations) without increasing much FLOPs, which is claimed as the increasing of ardinality.
SOME IDEAS
The explanation of why such designation can lead to better performance seems to be less pursative.
相关文章推荐
- [Paper note] Aggregated Residual Transformations for Deep Neural Networks
- Aggregated Residual Transformations for Deep Neural Networks
- 批量残差网络-Aggregated Residual Transformations for Deep Neural Networks
- ResNeXt - Aggregated Residual Transformations for Deep Neural Networks
- Aggregated Residual Transformations for Deep Neural Networks 阅读笔记
- Aggregated Residual Transformations for Deep Neural Networks
- Aggregated Residual Transformations for Deep Neural Networks - arxiv 16.11
- READING NOTE: PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- READING NOTE: Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Trackin
- Reading Note: ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
- [Paper note] PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- READING NOTE: ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
- Efficient Training of Very Deep Neural Networks for Supervised Hashing
- Weighted-Entropy-based Quantization for Deep Neural Networks
- An End-to-End System for Unconstrained Face Verification with Deep Convolutional Neural Networks
- READING NOTE: Feature Pyramid Networks for Object Detection
- 【Paper Note】Very Deep Convolutional Networks for Large-Scale Image Recognition——VGG(论文理解)
- 目标检测--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- READING NOTE: Pushing the Limits of Deep CNNs for Pedestrian Detection
- 《Neural Networks and Deep Learning》codes' note