Spark系列(四)整体架构分析
2016-11-15 10:06
525 查看
架构流程图
说明
Driver端流程说明(Standalone模式)
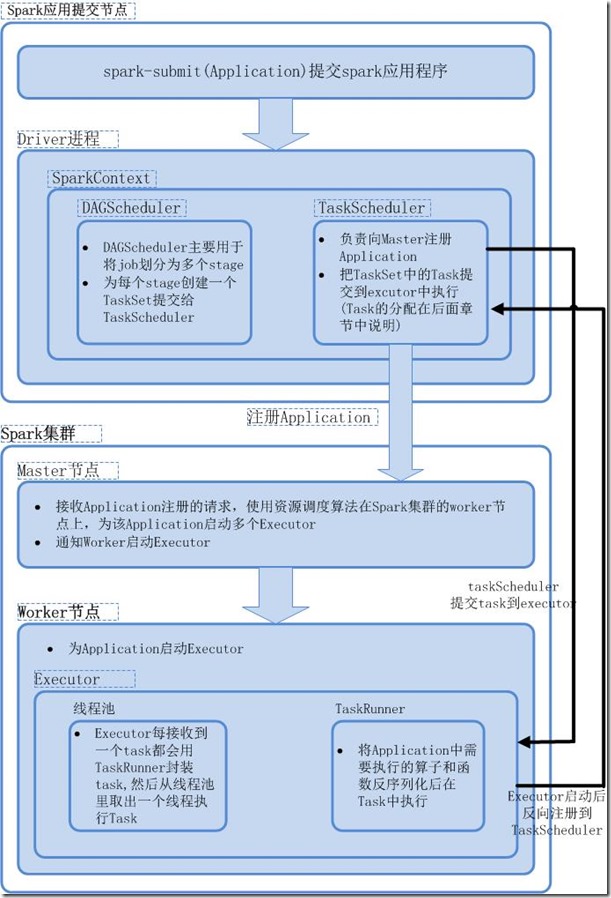
使用spark-submit提交Spark应用程序Application.
通过反射的方式创建和构造一个DriverActor进程(Driver进程).
SparkContext初始化,构造DAGScheduler和TaskScheduler.
每执行到一个Action操作就会创建一个job,该job会提交到DAGScheduler,划分为多个stage然后为每个stage创建一个TaskSet.
TaskScheduler负责连接Master并向Master注册Application.
TaskScheduler把TaskSet中的每一个task提交到executor上执行(task分配算法).
SparkContext的初始化在所有Executor完成反向注册后才完成,并继续执行提交的应用程序.
Master和Worker流程说明
Master接收到Application注册请求后会使用自己的资源调度算法,在Spark集群的Work上为这个Application启动多个Executor.
Executor启动之后反注册到TaskScheduler.
Executor每次收到一个task都会用TaskRunner来封装task,然后从线程池里取出一个线程执行这个task.
TaskRunner将需执行的算子及函数、拷贝、反序列化然后执行task.
窄依赖
英文名:Narrow Depandency
一个RDD对它的父RDD,只有简单的一对一的依赖关系,也就是说RDD的每个partition仅仅依赖于父RDD中的一个partition.父RDD和子RDD的partition之间的对应关系为一对一
宽依赖
英文名:Shuffle Dependency
本质为Shuffle,每一个父RDD的partition中的数据,都可能会传输一部分到下一个RDD的每一个oartition.该情况下父RDD和子RDD的partition之间是多对一的关系

说明
Driver端流程说明(Standalone模式)
使用spark-submit提交Spark应用程序Application.
通过反射的方式创建和构造一个DriverActor进程(Driver进程).
SparkContext初始化,构造DAGScheduler和TaskScheduler.
每执行到一个Action操作就会创建一个job,该job会提交到DAGScheduler,划分为多个stage然后为每个stage创建一个TaskSet.
TaskScheduler负责连接Master并向Master注册Application.
TaskScheduler把TaskSet中的每一个task提交到executor上执行(task分配算法).
SparkContext的初始化在所有Executor完成反向注册后才完成,并继续执行提交的应用程序.
Master和Worker流程说明
Master接收到Application注册请求后会使用自己的资源调度算法,在Spark集群的Work上为这个Application启动多个Executor.
Executor启动之后反注册到TaskScheduler.
Executor每次收到一个task都会用TaskRunner来封装task,然后从线程池里取出一个线程执行这个task.
TaskRunner将需执行的算子及函数、拷贝、反序列化然后执行task.
窄依赖
英文名:Narrow Depandency
一个RDD对它的父RDD,只有简单的一对一的依赖关系,也就是说RDD的每个partition仅仅依赖于父RDD中的一个partition.父RDD和子RDD的partition之间的对应关系为一对一
宽依赖
英文名:Shuffle Dependency
本质为Shuffle,每一个父RDD的partition中的数据,都可能会传输一部分到下一个RDD的每一个oartition.该情况下父RDD和子RDD的partition之间是多对一的关系

相关文章推荐
- Spark系列(四)整体架构分析
- jQuery-1.9.1源码分析系列(一)整体架构续
- Bootstrap源码分析系列之整体架构
- jQuery-1.9.1源码分析系列(一)整体架构
- Jquery源码分析系列(1)--Jquery整体架构
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
- Spark源码分析——Spark整体架构
- jQuery-1.9.1源码分析系列(一)整体架构
- jQuery-1.9.1源码分析系列(一)整体架构续
- UI框架系统剖析系列3(系统整体架构分析)
- Quartz.NET 架构与源代码分析系列 part 3 :Trigger 触发器
- Quartz.NET 架构与源代码分析系列
- ODI 系列学习--整体架构概念
- 【处理器体系架构系列】ARM流水线关键技术分析与代码优化
- BlogEngine.Net架构与源代码分析系列part11:开发扩展(下)——自定义Theme
- 网络协议栈实现分析1—整体架构分析
- BlogEngine.Net架构与源代码分析系列part14:实现分析(下)——网站页面上值得参考的部分
- BlogEngine.Net架构与源代码分析系列part13:实现分析(上)——HttpHandlers与HttpModules
- 大型网站架构分析系列技术文档合集二
- BlogEngine.Net架构与源代码分析系列part7:Web2.0特性——Pingback&Trackback