ZooKeeper入门笔记---架构以及应用介绍
2016-11-06 09:36
621 查看
ZooKeeper架构图:

| 1、ZooKeeper的基本概念 |
Zookeeper是一个有多个Server组成的集群.
1>一个leader,多个follower
2>每个server保存一份数据副本
3>全局数据一致
4>分布式读写
5>更新请求转发,有leader实施
| 2、ZooKeeper集群搭建的过程 |
①解压缩Zookeeper,并设置环境变量.
②修改Zookeeper的配置文件zoo.cfg,在配置文件中指定zk存放数据的目录以及节点对应的服务器编号(ID).
格式:
dataDir=/usr/local/zk/data/
server.N=YYY:2888:3888
具体含义:
YYY这个节点对应的服务器编号为N
其中N为节点对应的服务器编号、YYY为节点、2888这个端口负责在zk集群中进行数据的传输、3888这个端口负责在zk集群中进行选举
如:
server.1=hadoop11:2888:3888
server.2=hadoop22:2888:3888
server.3=hadoop33:2888:3888
③创建zk存放数据的目录. mkdir /usr/local/zk/data
④在data目录下,创建文件myid,并在myid文件中绑定节点对应的服务器编号,即N。

⑤启动,在三个节点上分别执行命令zkServer.sh start
⑥检验,在三个节点上分别执行命令zkServer.sh status.检验选举机制,同时查看对应的Java进程QuorumPeerMain.
集群搭建原则:在zk集群搭建的过程中,以zk的伪分布安装为主线,由内向外逐渐扩展zk集群.
| 3、为什么使用Zookeeper |
2>目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
3>协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
4>ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用
| 4、Zookeeper的作用 |
2>Hadoop2.0中,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等
3>HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
| 5、如何理解Zookeeper中的事务性一致 |
| 6、如何理解Zookeeper的数据模型 |
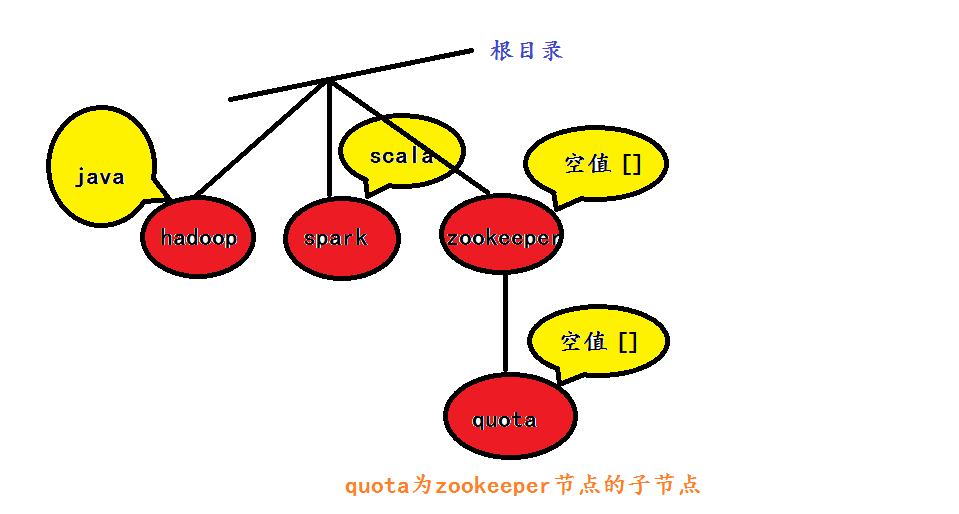
代码查看:
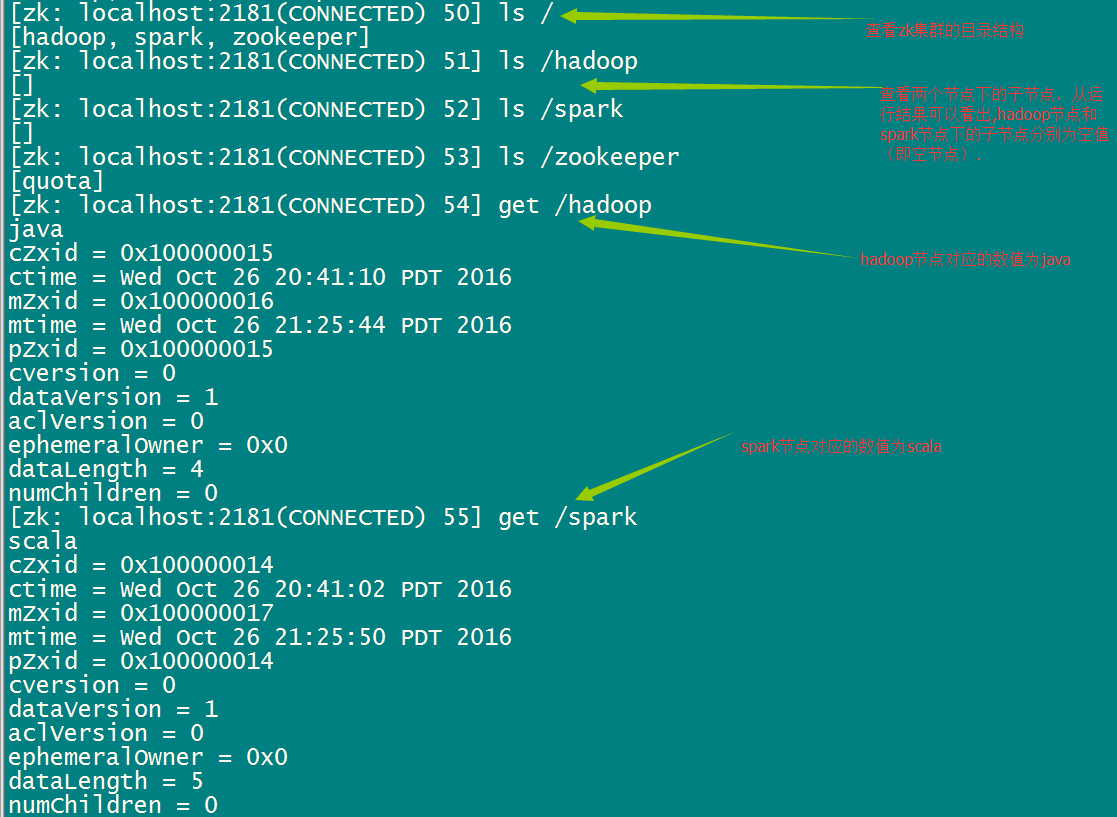
| 7、简述zk中常用的命令 |
create :创建一个节点并给它赋值
get :获取某一个节点的数值
set :设置某一个节点的数值
zkServer.sh start:开启zk集群的服务模式
zkCli.sh:进入客户端模式
| 8、简述Zk节点的分类 |
若节点不因为链接中断而丢失称为持久类型。

相关文章推荐
- ZooKeeper入门笔记---架构以及应用介绍
- Hbase入门笔记----架构以及应用介绍
- Flume入门笔记------架构以及应用介绍
- Flume入门笔记------架构以及应用介绍
- [置顶] HDFS入门笔记------架构以及应用介绍
- Flume入门之Flume架构以及应用介绍
- Hadoop之Flume架构以及应用介绍
- Flume架构以及应用介绍
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!~~
- Flume架构以及应用介绍
- Flume架构以及应用介绍
- MVC学习笔记之入门篇(二)mvc3相关介绍以及基础知识篇
- Hadoop之Hbase架构以及应用介绍
- Apache MINA 快速入门以及架构介绍
- Java EE - Spring MVC 入门介绍以及基于注解开发应用
- [置顶] Sqoop架构以及应用介绍
- Flume架构以及应用介绍
- DotNET企业架构应用实践-基于接口开发介绍以及应用场景和案例
- Spark入门之八:Spark Streaming 的原理以及应用场景介绍
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!~~