Hadoop Intellij IDEA本地开发环境搭建
2016-11-03 19:16
435 查看
首先我们需要新建一个java工程用于开发Mapper与Reducer,同时我们也需要导入hadoop的依赖包,这些包可以在hadoop的 share/hadoop 目录下找到,你可以把这些包单独取出来作为之后项目的备用。
打开Project Structure
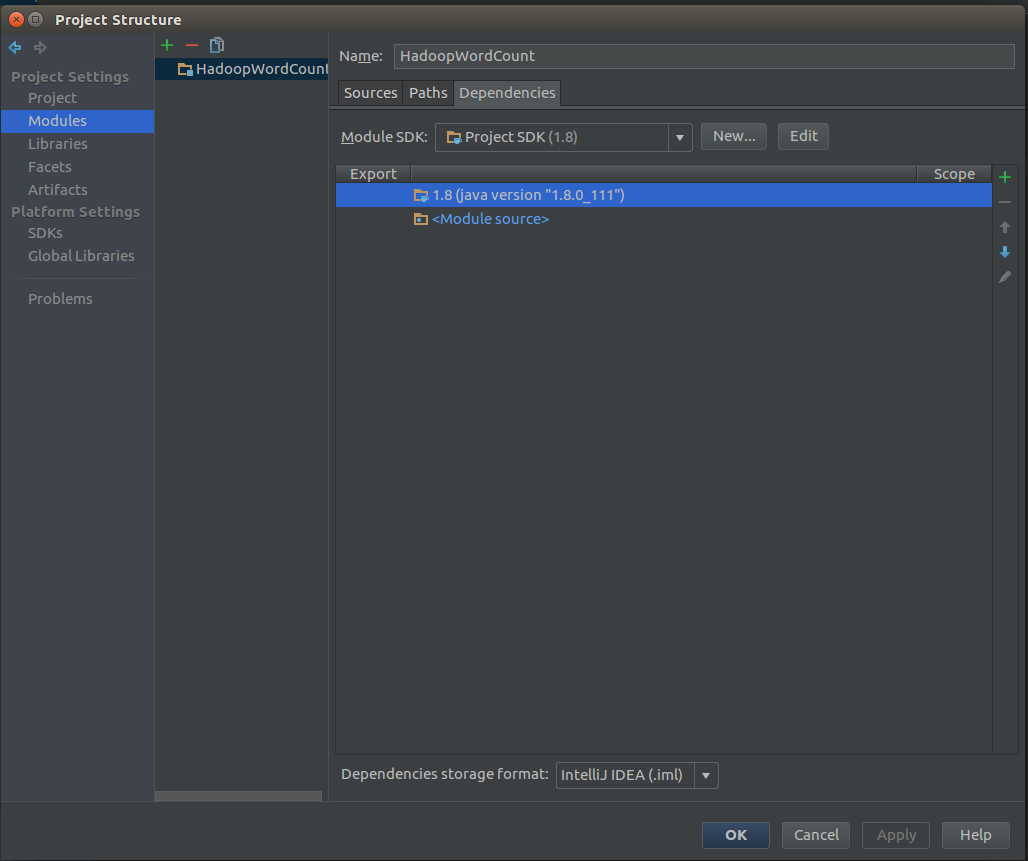
找到module点击右侧的小加号JARS or directories…
添加
添加完成之后应该像下图
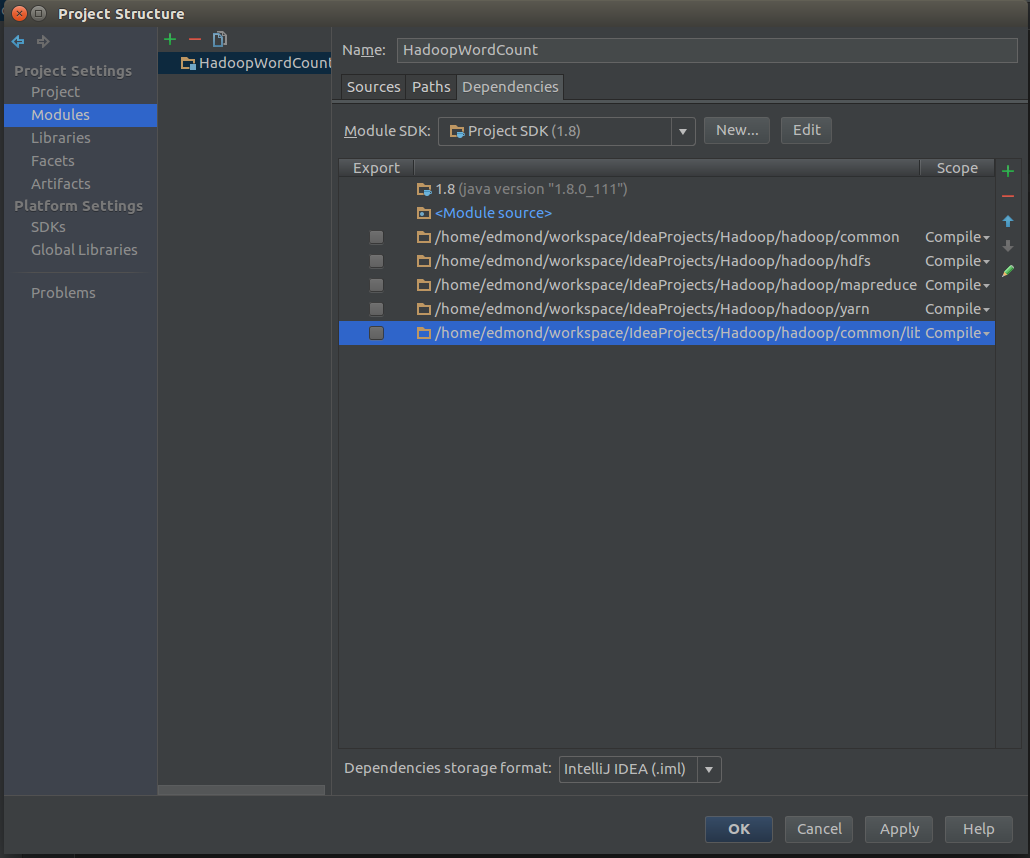
然后是Artifacts

点击加号,新建一个jar,jar->empty
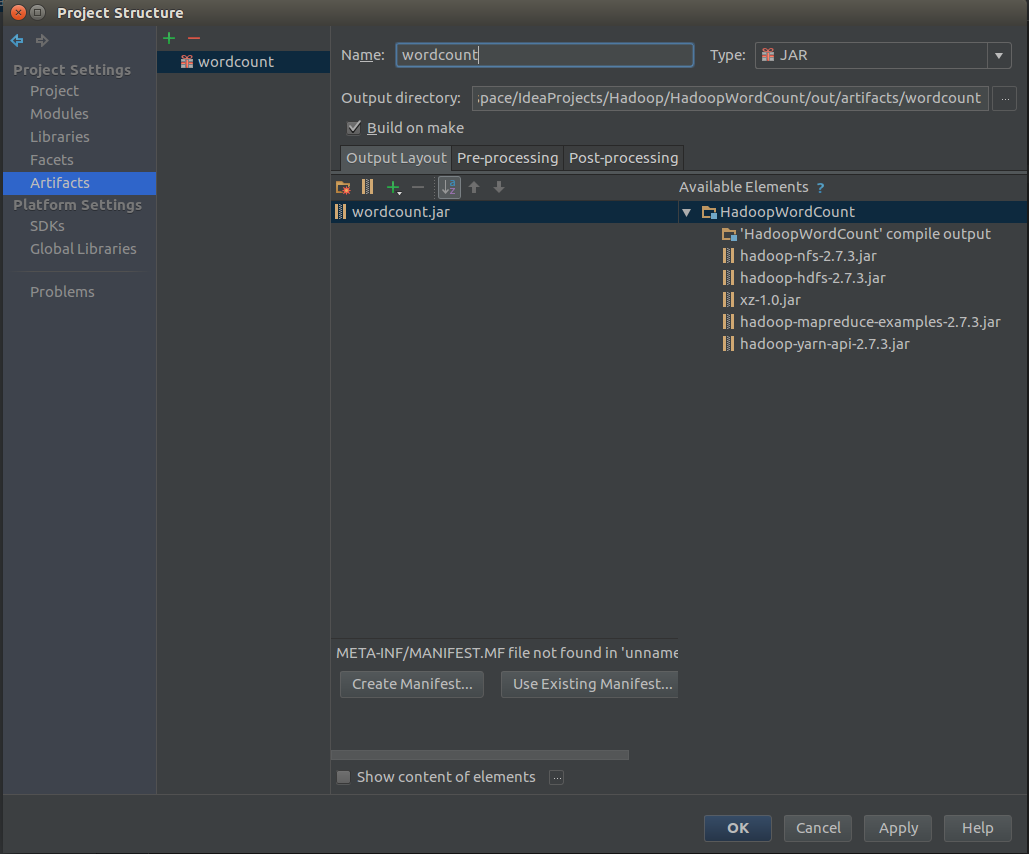
给自己的jar包取个名字,然后点击下面的绿色加号,Module output,在弹出的对话框中选择当前的项目,然后点击ok保存。
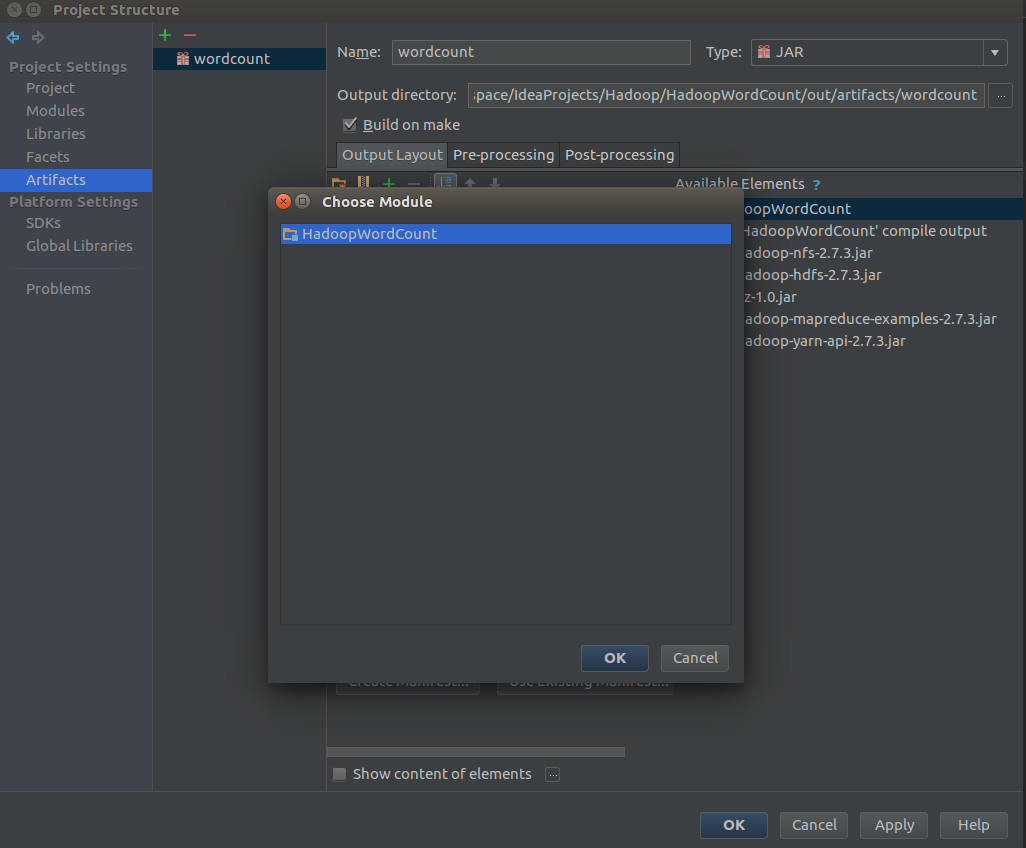
接着要新建一个Application
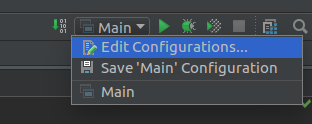
Edit Configurations
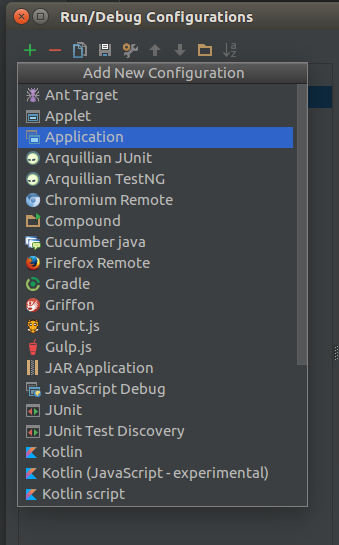
点击加号新建,选择Application
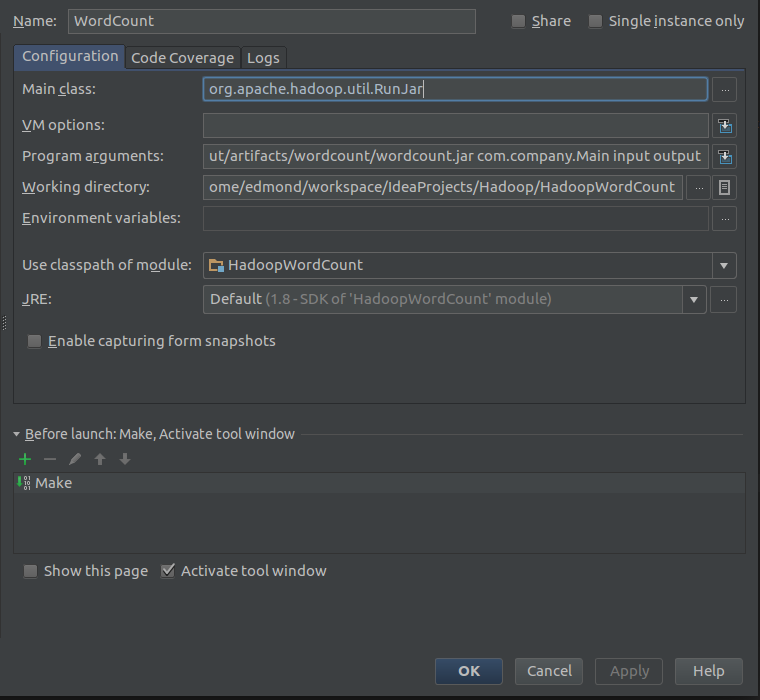

然后取个名字,在右侧的Main class中输入org.apache.hadoop.util.RunJar
Working directory当然是选择当前项目的目录了
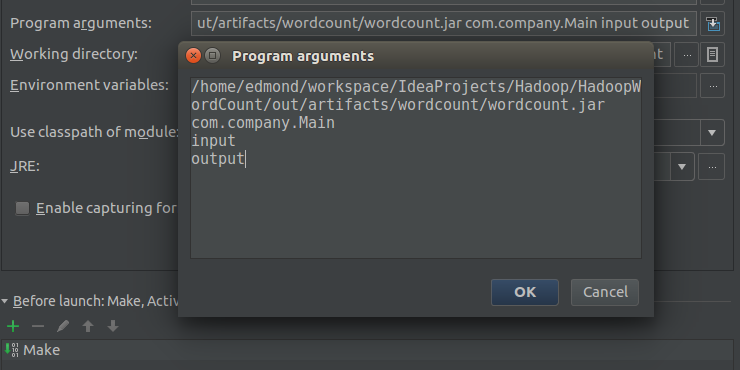
最后是Program arguments,这个是设置默认参数的会在程序执行的时候传递进去
第一个是jar包所在的位置
第二个是Main函数所在的类
第三四两个参数是由自己决定的(这两个参数会作为args[0]和args[1]传入)
点击ok保存。
然后我们需要开始对Mapper以及Reducer进行编写,首先先创建一个Mapper类
如果类都可以正常导入说明jar包没有问题
接着是Reducer类
最后我们需要编写main方法作为测试
这样main方法启动就会使用hadoop的mapper和reducer来处理数据
我们在项目目录下面创建一个input文件夹,在文件夹中创建一个文件,然后在文件中随意输入一些字符串,保存,然后运行刚刚新建的Application,等待运行完成会发现项目目录下多了一个output文件夹,打开里面的‘part-r-00000’文件就会发现里面是对你输入字符串的出现个数的统计。

当你第二次运行的时候因为hadoop不会自动删除output目录所以可能会出现错误,请手动删除之后再运行。
这样就可以使用intellij来开发hadoop程序并进行调试了。
打开Project Structure
找到module点击右侧的小加号JARS or directories…
添加
common hdfs mapreduce yarn comom/lib
添加完成之后应该像下图
然后是Artifacts
点击加号,新建一个jar,jar->empty
给自己的jar包取个名字,然后点击下面的绿色加号,Module output,在弹出的对话框中选择当前的项目,然后点击ok保存。
接着要新建一个Application
Edit Configurations
点击加号新建,选择Application
然后取个名字,在右侧的Main class中输入org.apache.hadoop.util.RunJar
Working directory当然是选择当前项目的目录了
最后是Program arguments,这个是设置默认参数的会在程序执行的时候传递进去
/home/edmond/workspace/IdeaProjects/Hadoop/HadoopWordCount/out/artifacts/wordcount/wordcount.jar com.company.Main input output
第一个是jar包所在的位置
第二个是Main函数所在的类
第三四两个参数是由自己决定的(这两个参数会作为args[0]和args[1]传入)
点击ok保存。
然后我们需要开始对Mapper以及Reducer进行编写,首先先创建一个Mapper类
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word,one);
}
}
}如果类都可以正常导入说明jar包没有问题
接着是Reducer类
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}最后我们需要编写main方法作为测试
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// write your code here
Configuration configuration = new Configuration();
if(args.length!=2){
System.err.println("Usage:wordcount <input><output>");
System.exit(2);
}
Job job = new Job(configuration,"word count");
job.setJarByClass(Main.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}这样main方法启动就会使用hadoop的mapper和reducer来处理数据
我们在项目目录下面创建一个input文件夹,在文件夹中创建一个文件,然后在文件中随意输入一些字符串,保存,然后运行刚刚新建的Application,等待运行完成会发现项目目录下多了一个output文件夹,打开里面的‘part-r-00000’文件就会发现里面是对你输入字符串的出现个数的统计。
当你第二次运行的时候因为hadoop不会自动删除output目录所以可能会出现错误,请手动删除之后再运行。
这样就可以使用intellij来开发hadoop程序并进行调试了。

相关文章推荐
- hadoop的windows远程linux服务进行本地开发环境搭建
- eclipse+maven搭建hadoop本地开发环境
- windows下搭建hadoop-2.6.0本地idea开发环境
- Hadoop 本地源码开发环境搭建
- Windows下搭建hadoop 搭建本地hadoop开发环境
- Hadoop本地开发环境搭建
- MR-eclipse本地开发环境搭建&Hadoop学习总结
- Windows8.1+Eclipse搭建Hadoop2.7.2本地模式开发环境
- windows下搭建hadoop-2.6.0本地idea开发环境
- [置顶] IntelliJ IDEA搭建Hadoop开发环境
- Hadoop2.x实战:Eclipse本地开发环境搭建与本地运行wordcount实例
- win7下Cygwin搭建Hadoop开发环境(由于win7环境不同导致本文章并不一定适合所有的win7用户)
- 如何使用Openshit开发项目和本地环境搭建
- 【环境搭建】hadoop分布式计算开发环境搭建
- 云计算Hadoop配置(四)——Eclipse中搭建Map-reduce开发环境
- 【环境搭建】hadoop分布式计算开发环境搭建
- 来自《Hadoop权威指南》第二版 - Hello Hadoop!云计算开发环境搭建
- windows下hadoop伪分布式模式开发环境的搭建(Cygwin)以及Eclipse集成开发环境下的搭建
- windows下搭建hadoop开发环境(Eclipse)
- win7+Cygwin+Eclipse搭建Hadoop开发环境