Neural Networks and Deep Learning CH4
2016-10-25 15:45
155 查看
Two caveats
Universality with one input and one output
Many input variables
Extension beyond sigmoid neurons
这一章比较简单,主要证明了为什么神经网络可以计算任意的连续函数。无论这个函数是什么,总存在一个神经网络,对任意的输入x,可以从网络中得到近似的f(x)。当函数有多个输入多个输出时也适用。
这个结论告诉我们,神经网络有一种普遍性(universality),无论我们要计算什么样的函数,总有一个神经网络可以计算它。甚至是只需要一层隐藏层就可以实现计算任意函数。因此非常简单的网络就可以很强大了。
本章将会给出一个关于universality theorem简单可视化的解释。
第一,这并不意味着一个网络可以用来精确地(exactly)计算任意的函数,而是获得一个我们想要的最好的近似(approximation)。增加隐藏层可以增加近似的程度。
第二,我们所能近似的函数是连续函数(continuous functions)。但实际中还是可以用连续函数近似不连续的函数的。
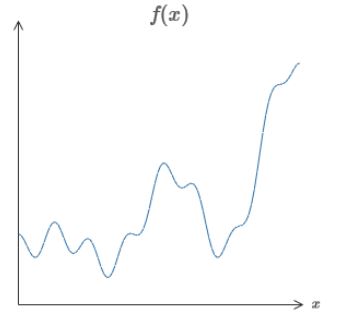
假设用以下神经网络来构造:

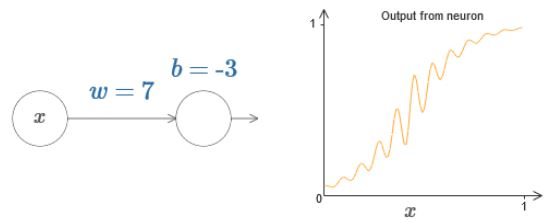
拖动w值和b的值后可以发现:w值增大,输出的中间段会变陡;反之,变缓。b值增大,整个函数向左平移;反之,向右平移。
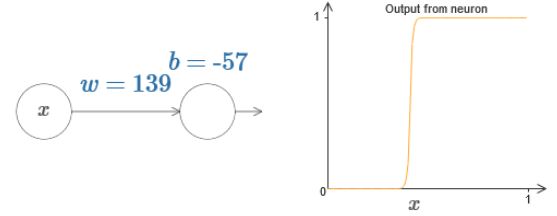
因此,通过控制上图中w和b的值,可以近似出一个step function:
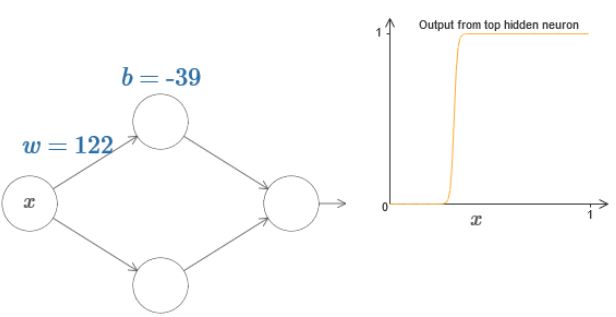
而实际上分析step functions比分析sigmoid functions简单,因为分析一系列的step functions的和比sigmoid functions的和简单。因此我们可以认为我们的神经网络输出的是step function的近似。
并且可以发现,阶跃发生在s=−b/w处。
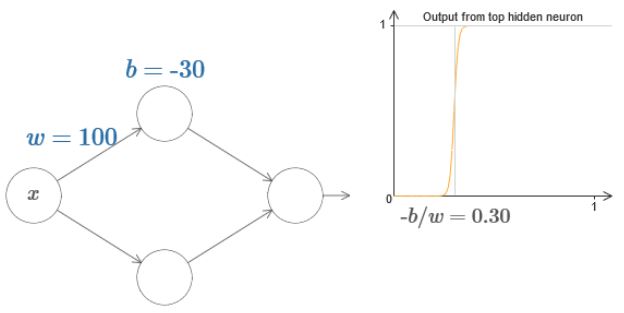
因此可以只用一个s来简化表达:
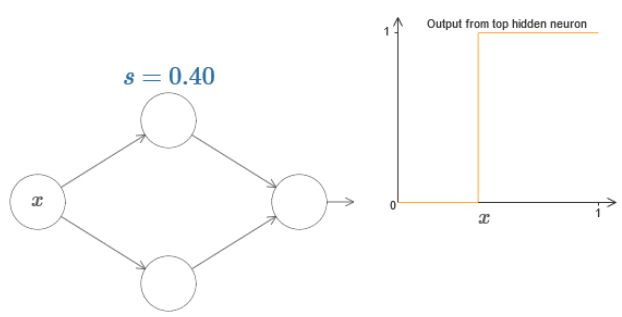
目前为止,我们只考虑了上面的一个神经元,现在我们加入下面的一个神经元以及最后两个weights一起考虑:
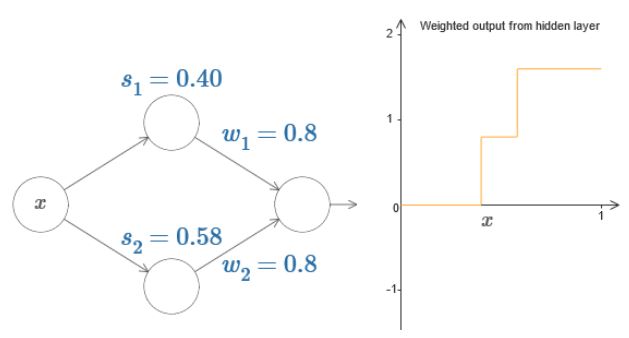
调制参数,可以得到如下图像:
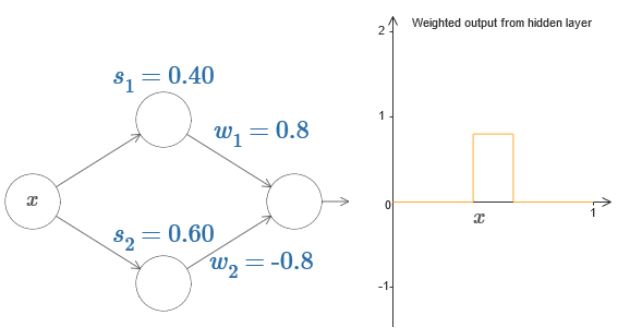
易知上图中w1,w2可以调整凸包的高度,s1,s2调整宽度,于是可以将上图简化表示如下:

继续加入几个神经元,可以达到如下效果:
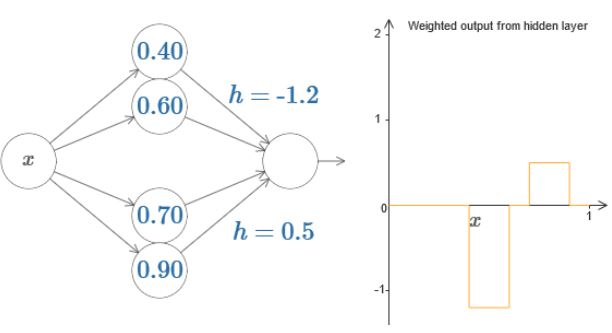
更进一步,可以得到:
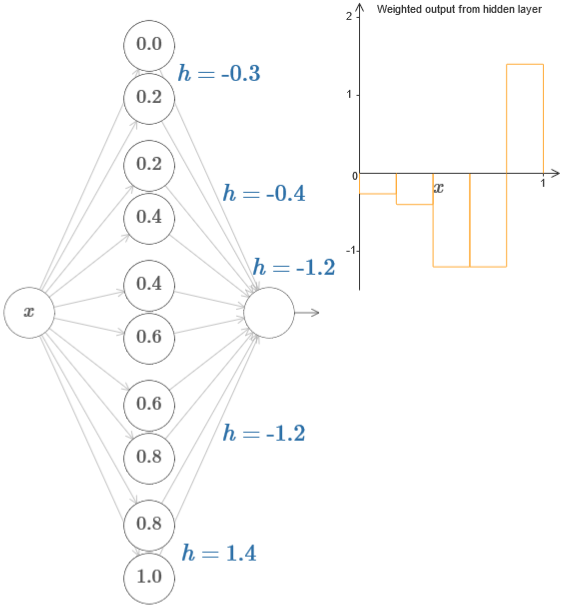
回到原来的问题,我们如何用上面的结论去构造一个函数呢?这里我觉得已经非常简单了,就和积分的推导过程差不多。而书中也是这样的意思:
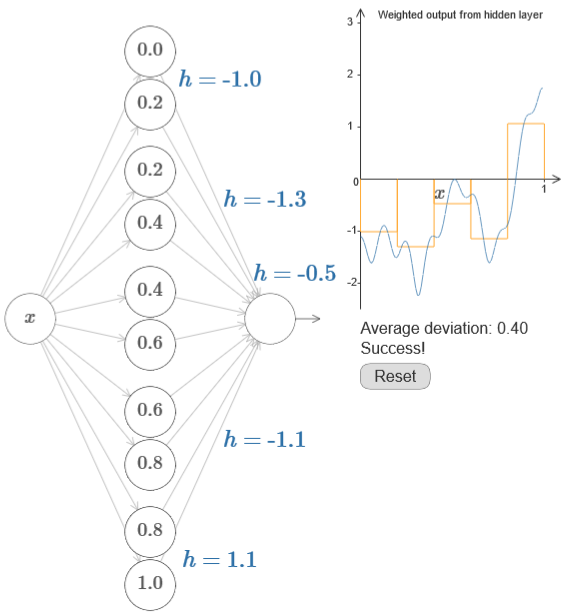
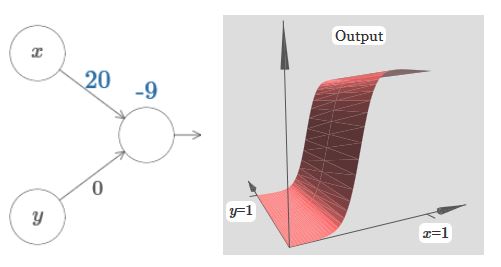
同样可以发现w调整“瀑布”的陡峭程度,越大越陡;而b则调整图像的位置。
依旧可以发现,其阶跃的位置为s=−b/w1。因此,同单输入一样定义:
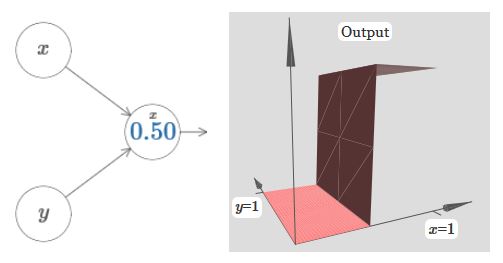
如果由下面那个神经元影响,图像如下:
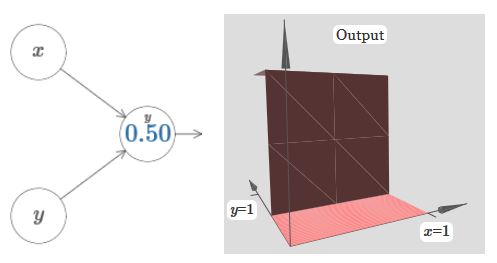
同一维的情况,可以“搭个桥”,注意此时的输出是输出层进入激活函数之前的输出:
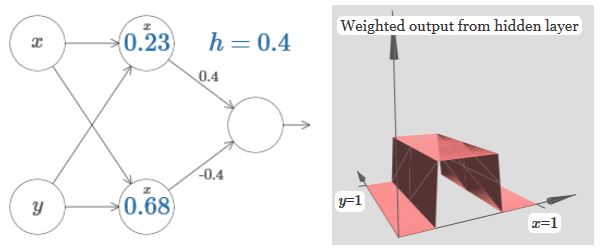
同理如果是y主导的,就换个方向。
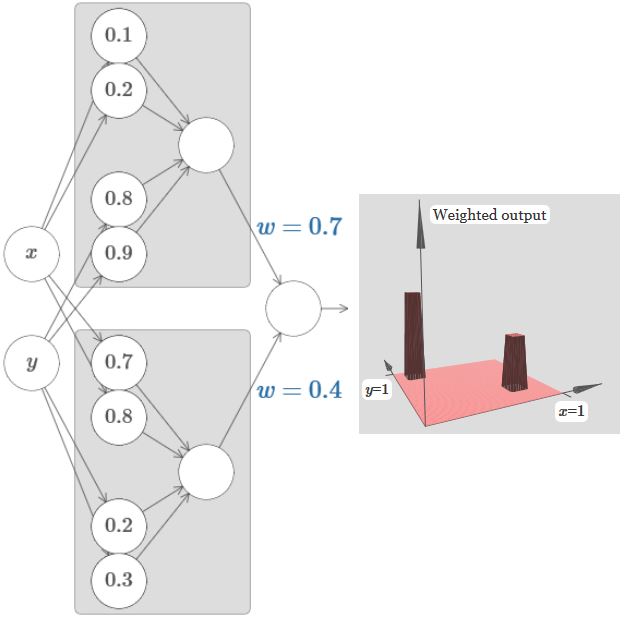
如果将两个方向结合起来,可以组成如下图像,中间一块凸起来是符合规律的,因为x和y重复叠加了:
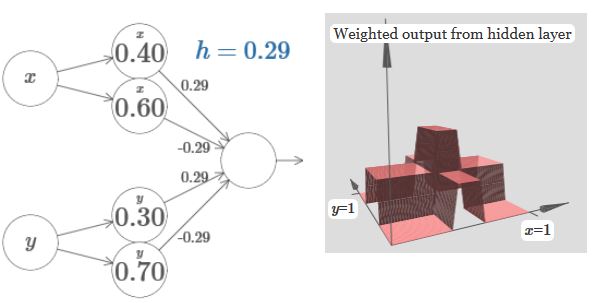
上图省略了边权为0的边。
如果能将上面的图像经过输出层的激活函数后,变为如下的Tower function:

那么我们就可以把许多的Tower function叠加起来:
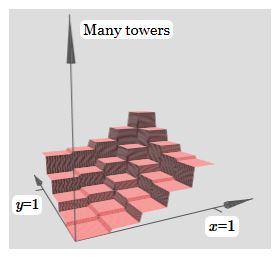
因此,加入输出层的偏差b,考虑如何构造Tower function,尝试后可以发现,当h变大,b变小时,可以达到这个效果:
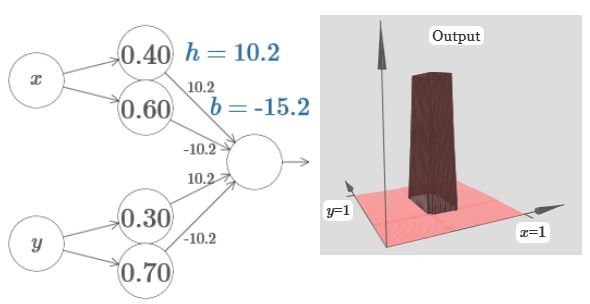
此时可以选择b=−3h/2。
将两个不同模块结合起来,并增加一层输出,可以得到如下效果:
接下来如何构造出一个二维的函数与一维同理。
接着可以往更多维的推导了。
…
经过推导,可以得到一个m维的函数,为了得到类似上面的Tower function,其输出的偏差约为(−m+1/2)h。
至此,便可以解释本章的问题了。
我们依旧可以用这个函数来构造一个step function:
将w调大,调整位置b,可以得到:
我们可以使用上面一节所提到的所有技巧来整合这个函数。
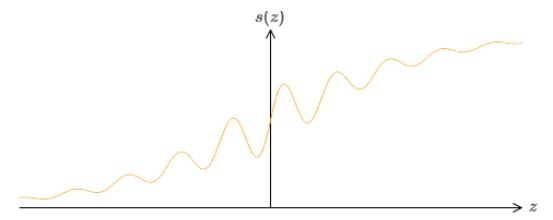
推广到一般,可以实现上述条件的激活函数满足:当z趋于正无穷和负无穷时,函数值趋近于两个值。
因而ReLU是不满足的。那么就有一个问题了,为什么ReLU可以用作激活函数来训练神经网络呢?
这里目前我也还没有答案。
Universality with one input and one output
Many input variables
Extension beyond sigmoid neurons
这一章比较简单,主要证明了为什么神经网络可以计算任意的连续函数。无论这个函数是什么,总存在一个神经网络,对任意的输入x,可以从网络中得到近似的f(x)。当函数有多个输入多个输出时也适用。
这个结论告诉我们,神经网络有一种普遍性(universality),无论我们要计算什么样的函数,总有一个神经网络可以计算它。甚至是只需要一层隐藏层就可以实现计算任意函数。因此非常简单的网络就可以很强大了。
本章将会给出一个关于universality theorem简单可视化的解释。
Two caveats
在进入解释之前,严格定义一下何为“a neural network can compute any function”。第一,这并不意味着一个网络可以用来精确地(exactly)计算任意的函数,而是获得一个我们想要的最好的近似(approximation)。增加隐藏层可以增加近似的程度。
第二,我们所能近似的函数是连续函数(continuous functions)。但实际中还是可以用连续函数近似不连续的函数的。
Universality with one input and one output
为了理解为什么universality theorem成立,从理解神经网络如何构造一个单输入单输出的函数入手:假设用以下神经网络来构造:
拖动w值和b的值后可以发现:w值增大,输出的中间段会变陡;反之,变缓。b值增大,整个函数向左平移;反之,向右平移。
因此,通过控制上图中w和b的值,可以近似出一个step function:
而实际上分析step functions比分析sigmoid functions简单,因为分析一系列的step functions的和比sigmoid functions的和简单。因此我们可以认为我们的神经网络输出的是step function的近似。
并且可以发现,阶跃发生在s=−b/w处。
因此可以只用一个s来简化表达:
目前为止,我们只考虑了上面的一个神经元,现在我们加入下面的一个神经元以及最后两个weights一起考虑:
调制参数,可以得到如下图像:
易知上图中w1,w2可以调整凸包的高度,s1,s2调整宽度,于是可以将上图简化表示如下:
继续加入几个神经元,可以达到如下效果:
更进一步,可以得到:
回到原来的问题,我们如何用上面的结论去构造一个函数呢?这里我觉得已经非常简单了,就和积分的推导过程差不多。而书中也是这样的意思:
Many input variables
接下来先看一个有两个输入的例子,之后就可以推广到更多维度。同样可以发现w调整“瀑布”的陡峭程度,越大越陡;而b则调整图像的位置。
依旧可以发现,其阶跃的位置为s=−b/w1。因此,同单输入一样定义:
如果由下面那个神经元影响,图像如下:
同一维的情况,可以“搭个桥”,注意此时的输出是输出层进入激活函数之前的输出:
同理如果是y主导的,就换个方向。
如果将两个方向结合起来,可以组成如下图像,中间一块凸起来是符合规律的,因为x和y重复叠加了:
上图省略了边权为0的边。
如果能将上面的图像经过输出层的激活函数后,变为如下的Tower function:
那么我们就可以把许多的Tower function叠加起来:
因此,加入输出层的偏差b,考虑如何构造Tower function,尝试后可以发现,当h变大,b变小时,可以达到这个效果:
此时可以选择b=−3h/2。
将两个不同模块结合起来,并增加一层输出,可以得到如下效果:
接下来如何构造出一个二维的函数与一维同理。
接着可以往更多维的推导了。
…
经过推导,可以得到一个m维的函数,为了得到类似上面的Tower function,其输出的偏差约为(−m+1/2)h。
至此,便可以解释本章的问题了。
Extension beyond sigmoid neurons
考虑不同与sigmoid的激活函数,s(z):我们依旧可以用这个函数来构造一个step function:
将w调大,调整位置b,可以得到:
我们可以使用上面一节所提到的所有技巧来整合这个函数。
推广到一般,可以实现上述条件的激活函数满足:当z趋于正无穷和负无穷时,函数值趋近于两个值。
因而ReLU是不满足的。那么就有一个问题了,为什么ReLU可以用作激活函数来训练神经网络呢?
这里目前我也还没有答案。

相关文章推荐
- Neural Networks and Deep Learning 神经网络和深度学习book
- Neural Networks and Deep Learning CH2
- Neural Networks and Deep Learning系列(一)概述
- [置顶] Coursera-Deep Learning Specialization 课程之(一):Neural Networks and Deep Learning-weak3编程作业
- 【deeplearning.ai】Neural Networks and Deep Learning——深层神经网络
- Andrew Ng-Neural Networks and Deep Learning 第三周作业
- Neural Networks and Deep Learning 资料整理
- neural networks and deep learning(Michael Nielsen)笔记(1)
- Coursera-Deep Learning Specialization 课程之(一):Neural Networks and Deep Learning-weak4编程作业
- Neural Networks and Deep Learning 神经网络和深度学习
- Neural Networks and Deep Learning 1
- neural networks and deep learning 吴恩达coursera公开课
- Neural Networks and Deep Learning(神经网络与深度学习)_What this book is about
- Neural Networks and Deep Learning(一)
- Neural Networks and Deep Learning之中文翻译-关于练习与问题
- Neural Networks and Deep Learning 学习笔记
- 【deeplearning.ai】Neural Networks and Deep Learning——浅层神经网络
- Andrew Ng-Neural Networks and Deep Learning 第二周作业
- Neural Networks and Deep Learning之中文翻译-第一章 用神经网络识别手写数字
- Andrew Ng-Neural Networks and Deep Learning 第四周作业【2】