Hadoop(一)--安装、配置与简单测试
2016-10-19 18:54
369 查看
刚刚开始接触Hadoop,发现网上好多安装教程都是适用1.x版本的,但现在都hadoop版本都已经到3.0了,不太适用于一个初学者,查了些资料,看了一些相关视频,才对Hadoop有一个初步了解,简单的配置了Hadoop,我使用的是Hadoop2.7.3,现在将Hadoop的安装配置总结如下:
Hadoop的安装配置(伪分布模式)总共分为三个步骤:
1. 安装Linux(使用CentOS 6.5 64位)
2. 安装JDK(使用jdk-8u101-linux-x64.tar.gz)
3. 安装Hadoop并配置文件(hadoop-2.7.3.tar.gz)
开始之前,还可以使用一些软件,为了便于传输文件:
1. winSCP:用于从windows向linux中传输文件
2. Xshell
使用winSCP将hadoop-2.7.3.tar.gz和jdk-8u101-linux-x64.tar.gz到CentOS中/opt(目录随意)
修改主机名(为了便于区分和之后配置文件)
# vim /etc/sysconfig/network
NETWORKING=yes
修改IP地址,两种方式:
第一种:
# setup(CentOS独有的)
Network configuration –> Device configuration —>选择网卡,设置IP地址,网关等
#ifconfig eth0 up(启动eth0网卡)
但是这样,重启后eth0不会自动启动,需要修改配置文件
第二种:
#vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:6e:fa:2d
TYPE=Ethernet
UUID=145ec129-2505-4e64-b97b-24a9bae43fec
ONBOOT=yes #默认自动启动
NM_CONTROLLED=yes
BOOTPROTO=none
IPADDR=192.168.1.100 #IP地址
NETMASK=255.255.255.0 #掩码
GATEWAY=192.168.1.1 #网关
DNS1=202.106.0.20
IPV6INIT=no
USERCTL=no
退出后更新配置:#source /etc/sysconfig/network-scripts/ifcfg-eth0
修改主机名和IP的映射关系
# vim /etc/hosts
192.168.1.100 master
关闭防火墙
查看防火墙状态
# service iptables status
关闭防火墙
# service iptables stop
查看防火墙开机启动状态
# chkconfig iptables –list
关闭防火墙开机启动
# chkconfig iptables off
#rpm -qa | grep java查看jdk版本
显示如下信息:
jtzdata-java-2013g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
卸载JDK:
# rpm -e –nodeps tzdata-java-2013g-1.el6.noarch
# rpm -e –nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
# rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
解压JDK
# tar -zxvf /opt/jdk-8u101-linux-x64.tar.gz
为了方便,重命名为jdk
# mv jdk-8u101-linux-x64.tar.gz jdk
将java添加到环境变量中
# vim /etc/profile
在文件最后添加:
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
更新配置
#source /etc/profile
# tar -zxvf hadoop-2.7.3.tar.gz
重命名
#mv hadoop-2.7.3.tar.gz hadoop
配置环境
# vim /etc/proflie
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/ipt/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
更新配置
#source /etc/profile
这样,Hadoop的独立模式就配置完成了。
伪分布模式需要配置5个文件,都在HADOOP_HOME/etc/profile中
xml文件配置的内容都在中添加
xml文件的格式:
(1)hadoop-env.sh,hadoop环境文件,这里需要配置Java环境:
# vim hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/jdk
(2)core-site.xml,核心配置文件:
(3) hdfs-site.xml
(4)mapred-site.xml
里面只有一个mapred-site.xml.template文件,执行
# cp mapred-site.xml.template mapred-sit.xml
(5)yarn-site.xml
(6)slaves
i. slaves指定哪些机器上要启动datanodes
ii. 它的默认值是localhost
iii. 第一行设置namenode、其余行设置datanodes
hdfs是一个文件系统,初次使用要格式化:
#hdfs namenode -format
出现has been successfully formated,格式化成功
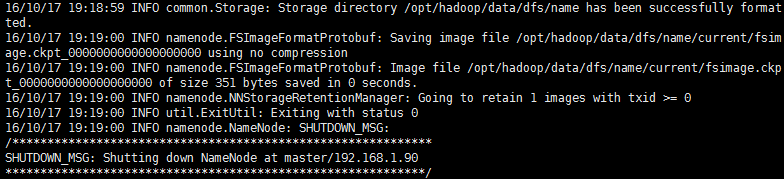
格式化后在HADOOP_HOME/data/dfs/name/current中保存的文件就是元数据fsimage_000000000000000000000:namenode就是管理元数据的(hdfs中某个文件对应了哪些切块,这些切块在哪些datanode主机上面)
启动Hadoop
切换到HADOOP_HOME/sbin下
其中文件有start-all.sh、stop-all.sh、start-dfs.sh、stop-dfs.sh、start-yarn.sh和stop-yarn.sh等,分别为开始和停止进程
需要注意的是,没启动一个节点,都需要输入密码,在最后将介绍无密钥登录以及如何配置多个datanode
先启动hdfs(Hadoop的分布式文件管理系统):# start-dfs.sh

然后启动yarn(资源管理调度):#start-yarn.sh

使用jps查看java进程,出现以下进程,说明启动成功

这样Hadoop的伪分布模式就安装、配置并且启动成功了!!

向hdfs中发送和下载文件
向hdfs传输文件:# hadoop fs -put 文件名(具体路径) hdfs://master:端口号
上传的文件仍然存储在本地,但不是原文件的地址,因为上传到hdfs中的文件,是被切分为了几个小块(BLOCK),保存在了不同的DataNode中(伪分布模式下仍然在NameNode中)
上传的文件可以进入http://master:50070查看,也可以通过# hadoop fs -ls 目录查看
从hdfs下载文件:# hadoop fs -get /目录/文件名 保存的目录/保存的文件名
可以使用“/”代替hdfs:/master:90000
测试MapReduce,运行几个MapReduce中自带的例子,在HADOOP_HOME/share/hadoop/mapreduce下的hadoop-mapreduce-examples-2.7.3.jar中有许多示例程序,切换到该目录下
运行pi,求圆周率:# hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 5 5


运行wordcount,求词频,创建一个包含英文单词的test.txt:
上传文件:# hadoop fs -mkdir /wordcount
# hadoop fs -mkdir /wordcount/input
# hadoop fs -put word.txt /wordcount/input
运行:# hadoop jar hadoop-mapreduce-example-2.7.3.jar wordcount /wordcount/input /wordcount/output,output自动生成
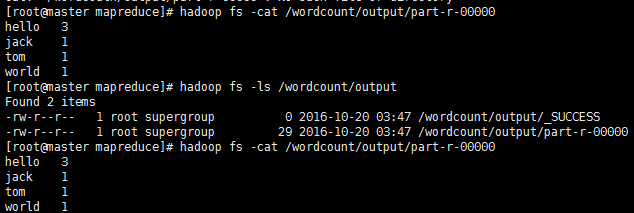
结束后查看结果:
# hadoop fs -ls /wordcount/output
# hadoop fs -cat /wordcount/ouput/part-r-00000
ad63
假设namenode节点的主机是master(192.168.1.100),其余datanode的主机分别为slaver1(192.168.1.101),slaver2(192.168.1.102),slaver3(192.168.1.103)
配置hosts:#vim /etc/hosts,添加如下内容
192.168.1.100 master
192.168.1.101 slaver1
192.168.1.102 slaver2
192.168.1.103 slaver3
分别在各主机检查ssh服务状态(CentOS默认开启)
# service sshd status
如果没有安装:# yum install openssh-server openssh-clients
如果没有启动:# service sshd start
分别在各主机生成密钥
ssh-keygen -t rsa #生成密钥的方法是rsa,一直按回车知道结束
务必在每个主机上都生成,生成目录在家目录的.ssh目录中,其中id_rsa文件为私钥,id_rsa文件为公钥
在每个slaver中(第i个)执行如下命令:
将每个公钥重命名
# scp ~/.ssh/id_rsa.pub ~/.ssh/slaveri.id_rsa.pub
将每个datanode的公钥发送给master
# scp ~/.ssh/slaveri.id_rsa.pub master:~/.ssh
在master中执行,切换到.ssh目录下:
将master自己的公钥放入authorized_keys中:# cp id_rsa.pub authorized_keys
将每个slaver的公钥放入authorized_keys
# cat slaver1.id_rsa.pub >>authorized_keys
# cat slaver2.id_rsa.pub >>authorized_keys
# cat slaver3.id_rsa.pub >>authorized_keys
将authorized_keys再发送给每一个slaver
# scp authorized_keys slaver1:~/.ssh
# scp authorized_keys slaver2:~/.ssh
# scp authorized_keys slaver3:~/.ssh
这样ssh无密钥访问就配置完成了!!就不用每次都输入密码确认了
配置其它datanodes:
在master中配置完成JDK后,使用ssh将jdk发送到其他每个主机(#scp -r /opt/jdk slaver:/opt/,放到同样目录,便于配置),在/etc/profile中添加同样内容即可
在master中将hadoop配置完成后(在slaver文件中添加这三个节点名),同样的将hadoop发送到其他节点,然后在/etc/profile中添加同样内容即可
启动hadoop只需要在master中启动
Hadoop的安装配置(伪分布模式)总共分为三个步骤:
1. 安装Linux(使用CentOS 6.5 64位)
2. 安装JDK(使用jdk-8u101-linux-x64.tar.gz)
3. 安装Hadoop并配置文件(hadoop-2.7.3.tar.gz)
开始之前,还可以使用一些软件,为了便于传输文件:
1. winSCP:用于从windows向linux中传输文件
2. Xshell
使用winSCP将hadoop-2.7.3.tar.gz和jdk-8u101-linux-x64.tar.gz到CentOS中/opt(目录随意)
安装Linux并配置相关项
安装虚拟机和CentOS就不再赘述,为了简单网络连接使用的桥接修改主机名(为了便于区分和之后配置文件)
# vim /etc/sysconfig/network
NETWORKING=yes
修改IP地址,两种方式:
第一种:
# setup(CentOS独有的)
Network configuration –> Device configuration —>选择网卡,设置IP地址,网关等
#ifconfig eth0 up(启动eth0网卡)
但是这样,重启后eth0不会自动启动,需要修改配置文件
第二种:
#vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:6e:fa:2d
TYPE=Ethernet
UUID=145ec129-2505-4e64-b97b-24a9bae43fec
ONBOOT=yes #默认自动启动
NM_CONTROLLED=yes
BOOTPROTO=none
IPADDR=192.168.1.100 #IP地址
NETMASK=255.255.255.0 #掩码
GATEWAY=192.168.1.1 #网关
DNS1=202.106.0.20
IPV6INIT=no
USERCTL=no
退出后更新配置:#source /etc/sysconfig/network-scripts/ifcfg-eth0
修改主机名和IP的映射关系
# vim /etc/hosts
192.168.1.100 master
关闭防火墙
查看防火墙状态
# service iptables status
关闭防火墙
# service iptables stop
查看防火墙开机启动状态
# chkconfig iptables –list
关闭防火墙开机启动
# chkconfig iptables off
安装JDK
首先卸载自带的JDK(好像不卸载也没有问题)#rpm -qa | grep java查看jdk版本
显示如下信息:
jtzdata-java-2013g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
卸载JDK:
# rpm -e –nodeps tzdata-java-2013g-1.el6.noarch
# rpm -e –nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
# rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
解压JDK
# tar -zxvf /opt/jdk-8u101-linux-x64.tar.gz
为了方便,重命名为jdk
# mv jdk-8u101-linux-x64.tar.gz jdk
将java添加到环境变量中
# vim /etc/profile
在文件最后添加:
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
更新配置
#source /etc/profile
安装配置Hadoop
解压hadoop-2.7.3.tar.gz# tar -zxvf hadoop-2.7.3.tar.gz
重命名
#mv hadoop-2.7.3.tar.gz hadoop
配置环境
# vim /etc/proflie
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/ipt/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
更新配置
#source /etc/profile
这样,Hadoop的独立模式就配置完成了。
伪分布模式需要配置5个文件,都在HADOOP_HOME/etc/profile中
xml文件配置的内容都在中添加
xml文件的格式:
<configuration> <property> <name></name> <value></value> </property> …… <property> <name></name> <value></value> </property> </configuration>
(1)hadoop-env.sh,hadoop环境文件,这里需要配置Java环境:
# vim hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/jdk
(2)core-site.xml,核心配置文件:
<property> <!--fs:文件系统,defaultFS:默认的文件系统 ==> hadoop默认采用那种文件系统--> <name>fs.defaultFS</name> <!--采用hdfs,协议://主节点名:端口号(默认9000)--> <value>hdfs://master:9000/</value> </property> <property> <!--配置hadoop的工作目录,本地。存储hadoop在运行期间产生的数据 比如,将文件放入hdfs系统后,对文件进行切块,放在某些datanode中,datanode将切块管理起来,存放在本地主机中,这里就指定了存放的工作目录 这里笼统指定,让系统自己指定子目录,但在实际中应给namenode和datanode单独指定目录,而且要是单独的挂载点,便于管理--> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data/</value> </property>
(3) hdfs-site.xml
<property> <!--hdfs中副本的数量,必须放在不同电脑上--> <name>dfs.replication</name> <!--副本越多,占用存储越多--> <value>1</value> </property> <!--还可以定义blocksize,切块的大小,默认是128M(2.x中)-->
(4)mapred-site.xml
里面只有一个mapred-site.xml.template文件,执行
# cp mapred-site.xml.template mapred-sit.xml
<property> <!--mapreduce应该放在哪个资源调度集群中去跑--> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
(5)yarn-site.xml
<property> <!--yarn中的老大(Resourcemanager)的地址--> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <!--reducer获取数据的方式--> <!--nodemanager是集群中的从节点,配置的东西是的mapreduce程序正常跑 指定mapreduce程序里面map产生的中间结果如何传给reduce,采用shuffle--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
(6)slaves
i. slaves指定哪些机器上要启动datanodes
ii. 它的默认值是localhost
iii. 第一行设置namenode、其余行设置datanodes
hdfs是一个文件系统,初次使用要格式化:
#hdfs namenode -format
出现has been successfully formated,格式化成功
格式化后在HADOOP_HOME/data/dfs/name/current中保存的文件就是元数据fsimage_000000000000000000000:namenode就是管理元数据的(hdfs中某个文件对应了哪些切块,这些切块在哪些datanode主机上面)
启动Hadoop
切换到HADOOP_HOME/sbin下
其中文件有start-all.sh、stop-all.sh、start-dfs.sh、stop-dfs.sh、start-yarn.sh和stop-yarn.sh等,分别为开始和停止进程
需要注意的是,没启动一个节点,都需要输入密码,在最后将介绍无密钥登录以及如何配置多个datanode
先启动hdfs(Hadoop的分布式文件管理系统):# start-dfs.sh
然后启动yarn(资源管理调度):#start-yarn.sh
使用jps查看java进程,出现以下进程,说明启动成功
这样Hadoop的伪分布模式就安装、配置并且启动成功了!!
测试
在浏览器中(如果没有安装CentOS的桌面,可以用你的windows中浏览器)打开http://master:50070,(windows中可以使用http://192.168.1.100:50070)看到如下界面说明成功:向hdfs中发送和下载文件
向hdfs传输文件:# hadoop fs -put 文件名(具体路径) hdfs://master:端口号
上传的文件仍然存储在本地,但不是原文件的地址,因为上传到hdfs中的文件,是被切分为了几个小块(BLOCK),保存在了不同的DataNode中(伪分布模式下仍然在NameNode中)
上传的文件可以进入http://master:50070查看,也可以通过# hadoop fs -ls 目录查看
从hdfs下载文件:# hadoop fs -get /目录/文件名 保存的目录/保存的文件名
可以使用“/”代替hdfs:/master:90000
测试MapReduce,运行几个MapReduce中自带的例子,在HADOOP_HOME/share/hadoop/mapreduce下的hadoop-mapreduce-examples-2.7.3.jar中有许多示例程序,切换到该目录下
运行pi,求圆周率:# hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 5 5
运行wordcount,求词频,创建一个包含英文单词的test.txt:
上传文件:# hadoop fs -mkdir /wordcount
# hadoop fs -mkdir /wordcount/input
# hadoop fs -put word.txt /wordcount/input
运行:# hadoop jar hadoop-mapreduce-example-2.7.3.jar wordcount /wordcount/input /wordcount/output,output自动生成
结束后查看结果:
# hadoop fs -ls /wordcount/output
# hadoop fs -cat /wordcount/ouput/part-r-00000
ad63
配置SSH无密钥访问
这个配置以及ssh的原理在网上很多,这里只简单写一下配置的过程:假设namenode节点的主机是master(192.168.1.100),其余datanode的主机分别为slaver1(192.168.1.101),slaver2(192.168.1.102),slaver3(192.168.1.103)
配置hosts:#vim /etc/hosts,添加如下内容
192.168.1.100 master
192.168.1.101 slaver1
192.168.1.102 slaver2
192.168.1.103 slaver3
分别在各主机检查ssh服务状态(CentOS默认开启)
# service sshd status
如果没有安装:# yum install openssh-server openssh-clients
如果没有启动:# service sshd start
分别在各主机生成密钥
ssh-keygen -t rsa #生成密钥的方法是rsa,一直按回车知道结束
务必在每个主机上都生成,生成目录在家目录的.ssh目录中,其中id_rsa文件为私钥,id_rsa文件为公钥
在每个slaver中(第i个)执行如下命令:
将每个公钥重命名
# scp ~/.ssh/id_rsa.pub ~/.ssh/slaveri.id_rsa.pub
将每个datanode的公钥发送给master
# scp ~/.ssh/slaveri.id_rsa.pub master:~/.ssh
在master中执行,切换到.ssh目录下:
将master自己的公钥放入authorized_keys中:# cp id_rsa.pub authorized_keys
将每个slaver的公钥放入authorized_keys
# cat slaver1.id_rsa.pub >>authorized_keys
# cat slaver2.id_rsa.pub >>authorized_keys
# cat slaver3.id_rsa.pub >>authorized_keys
将authorized_keys再发送给每一个slaver
# scp authorized_keys slaver1:~/.ssh
# scp authorized_keys slaver2:~/.ssh
# scp authorized_keys slaver3:~/.ssh
这样ssh无密钥访问就配置完成了!!就不用每次都输入密码确认了
配置其它datanodes:
在master中配置完成JDK后,使用ssh将jdk发送到其他每个主机(#scp -r /opt/jdk slaver:/opt/,放到同样目录,便于配置),在/etc/profile中添加同样内容即可
在master中将hadoop配置完成后(在slaver文件中添加这三个节点名),同样的将hadoop发送到其他节点,然后在/etc/profile中添加同样内容即可
启动hadoop只需要在master中启动

相关文章推荐
- CentOS6.5+hadoop1.2.1安装配置测试记录
- 从零开始最短路径学习Hadoop之01----Hadoop的安装配置测试
- Mahout 安装配置及一个简单测试
- centos下 redis安装配置及简单测试
- Hadoop+Spark+Scala+R+PostgreSQL+Zeppelin安装过程-Spark的安装配置测试和Scala的安装配置
- redis安装以及主从的简单配置测试
- Expect的安装配置及简单测试脚本
- Hadoop-2.8.0集群搭建、hadoop源码编译和安装、host配置、ssh免密登录、hadoop配置文件中的参数配置参数总结、hadoop集群测试,安装过程中的常见错误
- Hadoop 2.7.3 安装配置及测试
- hadoop源码编译、配置安装、测试
- hadoop 2.2.0 集群模式安装配置和测试
- hadoop单机安装配置及测试通过
- hadoop2集群安装和测试之环境配置
- php源码安装、简单配置、测试及连接数据库
- iBATIS入门之安装配置与简单测试
- CentOS6.5+HADOOP2.7.1安装配置测试编译详细教程
- 简单的hadoop配置(我安装的问题)
- Atlas Sharding 安装、配置及简单测试
- Spark 安装配置简单测试