知乎爬虫之模拟登录
2016-10-13 23:55
211 查看
爬虫简单的原理就是发送一个请求到网站的服务器,服务器进行响应,然后从服务器响应的内容解析出我们想要的数据
这里我们将用requests库来发送请求(Windows上面在控制台通过pip3 install requests 进行安装),
解析可以用beautifulsoup库(用 pip3 install beautifulsoup安装),不过在这里暂时用不到解析,
python版本是3
第一步 分析
使用chrome浏览器和火狐浏览器都可以,这里我将使用火狐浏览器进行示范。
首先打开知乎登录页面,同时按F12打开开发者工具:
然后我们在这里需要对浏览器进行一下设置,勾选启用缓存日志,不然登录的时候你会发现发送登录的请求链接刚开始一秒左右还能看见,加载一会后就消失了:
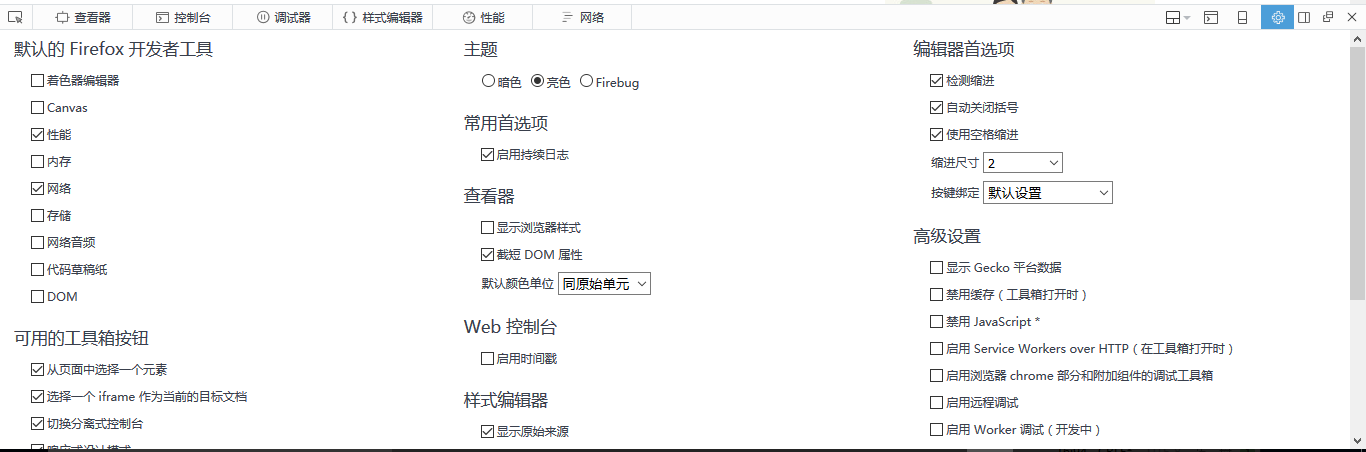
好了,输入账号密码然后点击登录,神奇的一幕出现了:
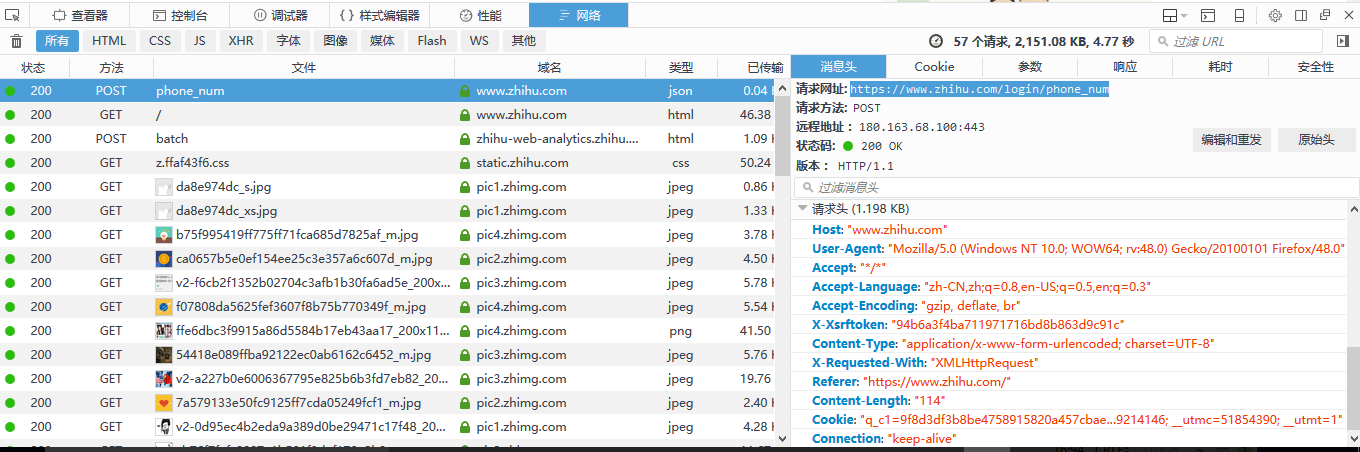
这个phone_num文件就是我们想要找的,点击可以查看到请求的网址是https://www.zhihu.com/login/phone_num和请求头,请求头的信息将会被用到来构建我们代码中的请求头,然后我们再看看参数,这是我们发送请求是传给网站服务器的数据,待会也要用到,这里我就不点开参数了给大家展示了,因为这里有我自己的账号信息
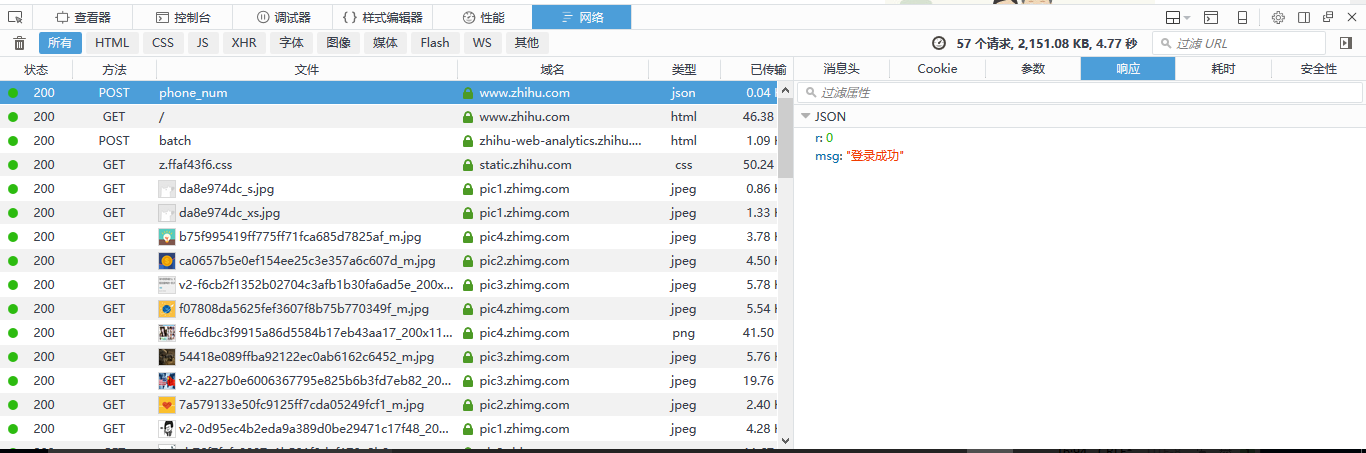
好了,分析过程完了,我们开始写代码了
第二步 写代码
好了,运行程序你就会在控制台看见登录成功的字样。
不过有时候你过于频繁的登录,知乎就会让你输入验证码,验证码怎么搞呢?不用怕,还是箱上面那样在浏览器开发者工具里面找验证码文件,然后查看它的请求URL,这个URL是以时间戳来构造的,我昨天还要输入验证码,今天又不用输入了,所以这里我就不再截图分析了,参考下面的代码
然后控制台会打印登录成功,模拟登录就完成啦。。
每天一小步。。
这里我们将用requests库来发送请求(Windows上面在控制台通过pip3 install requests 进行安装),
解析可以用beautifulsoup库(用 pip3 install beautifulsoup安装),不过在这里暂时用不到解析,
python版本是3
第一步 分析
使用chrome浏览器和火狐浏览器都可以,这里我将使用火狐浏览器进行示范。
首先打开知乎登录页面,同时按F12打开开发者工具:
然后我们在这里需要对浏览器进行一下设置,勾选启用缓存日志,不然登录的时候你会发现发送登录的请求链接刚开始一秒左右还能看见,加载一会后就消失了:
好了,输入账号密码然后点击登录,神奇的一幕出现了:
这个phone_num文件就是我们想要找的,点击可以查看到请求的网址是https://www.zhihu.com/login/phone_num和请求头,请求头的信息将会被用到来构建我们代码中的请求头,然后我们再看看参数,这是我们发送请求是传给网站服务器的数据,待会也要用到,这里我就不点开参数了给大家展示了,因为这里有我自己的账号信息
好了,分析过程完了,我们开始写代码了
第二步 写代码
# -*- coding:utf-8 -*-
__author__="weikairen"
import requests
from bs4 import BeautifulSoup
URL='https://www.zhihu.com/login/phone_num'
User_Agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36X-Requested-With:XMLHttpRequest'
headers = {'user-agent': User_Agent}
data={
'_xsrf':'a626e45048da76595564ec6607fa0c9c',
'password':'*******',
'remember_me':'true',
'phone_num':'********'
}
#requests_session = requests.session()
#response = requests_session.post(url=URL, headers=headers,data=data)
# 这种和下面一行的方法是一样的,这使用session方法是因为可以保存cookie
# 这里你可以先知道有这么个用法
response=requests.post(url=URL, headers=headers,data=data)
print(response.json()['msg'])好了,运行程序你就会在控制台看见登录成功的字样。
不过有时候你过于频繁的登录,知乎就会让你输入验证码,验证码怎么搞呢?不用怕,还是箱上面那样在浏览器开发者工具里面找验证码文件,然后查看它的请求URL,这个URL是以时间戳来构造的,我昨天还要输入验证码,今天又不用输入了,所以这里我就不再截图分析了,参考下面的代码
# -*- coding:utf-8 -*-
__author__="weikairen"
import requests
from bs4 import BeautifulSoup
import time
BASE_URL='https://www.zhihu.com/'
LOGIN_URL=BASE_URL+'login/phone_num'
CAPTCHA_URL=BASE_URL+'captcha.gif?r='+str(int(time.time())*1000)+'&type=login'
def login():
headers={
'host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0',
'referer':"https://www.zhihu.com/",
'X - Requested - With': "XMLHttpRequest"
} #构造请求头,讲它伪装成为浏览器
captcha_content=requests.get(CAPTCHA_URL,headers=headers).content
with open('C:\cap.gif','wb') as cap: #将验证码图片下载下来存储到C盘的根目录下面
cap.write(captcha_content)
captcha=input('请输入验证码: ')
data={
'_xsrf': "94b6a3f4ba711971716bd8b863d9c91c",
'password': "********",
'captcha_type': "cn",
'remember_me': "true",
'phone_num': "********"
}
session = requests.session() #这里使用了session方法是因为可以自动保存cookie在session中
response=session.post(LOGIN_URL,data=data,headers=headers)
print(response.json()['msg'])
login()然后控制台会打印登录成功,模拟登录就完成啦。。
每天一小步。。

相关文章推荐
- Python网络爬虫之模拟登录(以知乎为例)
- Java爬虫——模拟登录知乎
- Python爬虫之模拟知乎登录的方法教程
- python--python3爬虫之模拟登录知乎
- 【python爬虫03】使用Scrapy框架模拟登录知乎
- 【python爬虫01】使用requests库模拟登录知乎
- 爬虫入门到精通-headers的详细讲解(模拟登录知乎)
- Python爬虫初学(三)—— 模拟登录知乎
- Python网络爬虫之模拟登录(以知乎为例)
- Java爬虫——模拟登录知乎
- python -- 拉勾网爬虫模拟登录
- python爬虫实战(四)--------豆瓣网的模拟登录(模拟登录和验证码的处理----scrapy)
- scrapy爬虫之模拟登录豆瓣
- [python和大数据-1]利用爬虫登录知乎进行BFS搜索抓取用户信息本地mysql分析【PART1】
- 知乎改版使用restapi后模拟登录
- Android(Java) 模拟登录知乎并抓取用户信息
- Java爬虫——人人网模拟登录
- selenium模拟登录知乎
- Python使用Srapy框架爬虫模拟登陆并抓取知乎内容
- 爬虫记录(3)——模拟登录获取cookie,访问私信页面