python -- 拉勾网爬虫模拟登录
2017-09-06 16:21
603 查看
入门爬虫一段时间,最近在做一个拉勾网的数据爬虫分析,项目也快接近尾声了,于是抽个时间写一下这个项目中遇到的一些问题。
目前拉勾网的反爬虫机制还是可以的,一开始用scrapy shell 分析拉勾网,发现拉勾网要校验useragent,然后访问不到几次就会被重定向到登录页面,即拉勾网会校验cookie。
下面是模拟登陆的思路:
拉勾网登录页面: https://passport.lagou.com/login/login.html
抓包分析一下

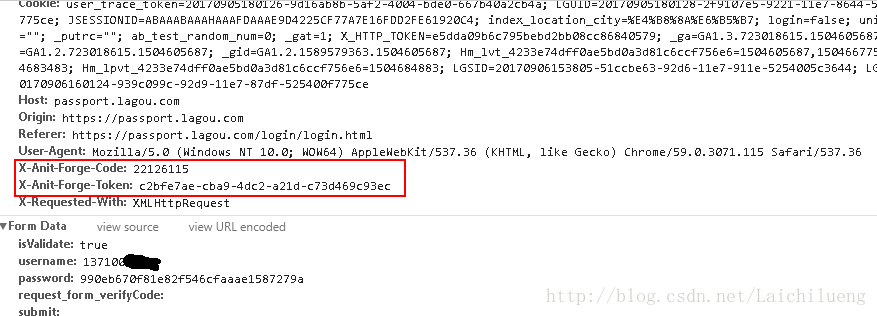
可以分析出模拟登陆需要的参数:
url = “https://passport.lagou.com/login/login.html”
postData = {
‘isValidate’ : ‘true’,
‘username’ : username,
‘password’: password,
‘request_form_verifyCode’: ”,
‘submit’: ”
}
HEADERS = {
‘Referer’: ‘https://passport.lagou.com/login/login.html‘,
‘User-Agent’: ”,
‘X-Requested-With’: ‘XMLHttpRequest’,
‘X-Anit-Forge-Token’: ”,
‘X-Anit-Forge-Code’, ”,
}
那么如何去获取X-Anit-Forge-Token、X-Anit-Forge-Code这两个参数呢?
我们打开F12认真看登录页面的源代码
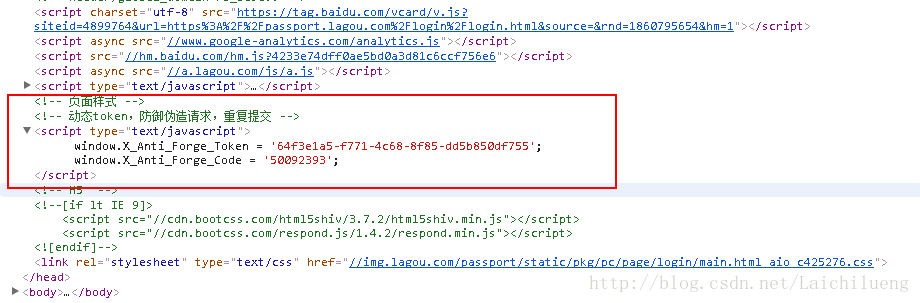
可以在head标签里面可以找到这两个值,只需要用正则去匹配出来就可以了。
那么登录的密码是怎么加密的呢?
从源码里可以看出,登录页面 加载的js并不多,那么就一个一个找吧。
在 main.html_aio_f95e644.js (“https://img.lagou.com/passport/static/pkg/pc/page/login/main.html_aio_f95e644.js“)
这个js里面发现了加密的方法:

首先对密码进行一次md5加密:password = md5(password)
然后前后加上veenike这串字符: password = “veenike” + password + “veenike”
最后再次进行md5加密:password = md5(password)
那么到这里分析就差不多了,下面为模拟登录的代码
控制台结果
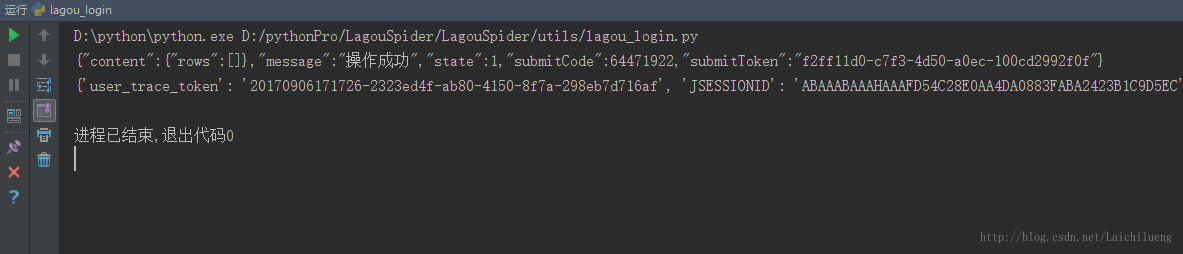
模拟登录以后便能获取到cookie,为爬虫做准备。代码拷贝就即能跑,不过拉勾网的登录校验随时会改变,若发现登录失败的可以在下面评论,我会抽空更新代码。
github地址:https://github.com/laichilueng/lagou_login
喜欢的可以去点个赞,谢谢
目前拉勾网的反爬虫机制还是可以的,一开始用scrapy shell 分析拉勾网,发现拉勾网要校验useragent,然后访问不到几次就会被重定向到登录页面,即拉勾网会校验cookie。
下面是模拟登陆的思路:
拉勾网登录页面: https://passport.lagou.com/login/login.html
抓包分析一下
可以分析出模拟登陆需要的参数:
url = “https://passport.lagou.com/login/login.html”
postData = {
‘isValidate’ : ‘true’,
‘username’ : username,
‘password’: password,
‘request_form_verifyCode’: ”,
‘submit’: ”
}
HEADERS = {
‘Referer’: ‘https://passport.lagou.com/login/login.html‘,
‘User-Agent’: ”,
‘X-Requested-With’: ‘XMLHttpRequest’,
‘X-Anit-Forge-Token’: ”,
‘X-Anit-Forge-Code’, ”,
}
那么如何去获取X-Anit-Forge-Token、X-Anit-Forge-Code这两个参数呢?
我们打开F12认真看登录页面的源代码
可以在head标签里面可以找到这两个值,只需要用正则去匹配出来就可以了。
那么登录的密码是怎么加密的呢?
从源码里可以看出,登录页面 加载的js并不多,那么就一个一个找吧。
在 main.html_aio_f95e644.js (“https://img.lagou.com/passport/static/pkg/pc/page/login/main.html_aio_f95e644.js“)
这个js里面发现了加密的方法:
首先对密码进行一次md5加密:password = md5(password)
然后前后加上veenike这串字符: password = “veenike” + password + “veenike”
最后再次进行md5加密:password = md5(password)
那么到这里分析就差不多了,下面为模拟登录的代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import hashlib
import re
#请求对象
session = requests.session()
#请求头信息
HEADERS = {
'Referer': 'https://passport.lagou.com/login/login.html',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:51.0) Gecko/20100101 Firefox/51.0',
}
def get_password(passwd):
'''这里对密码进行了md5双重加密 veennike 这个值是在main.html_aio_f95e644.js文件找到的 '''
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
passwd = 'veenike' + passwd + 'veenike'
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
return passwd
def get_token():
Forge_Token = ""
Forge_Code = ""
login_page = 'https://passport.lagou.com/login/login.html'
data = session.get(login_page, headers=HEADERS)
match_obj = re.match(r'.*X_Anti_Forge_Token = \'(.*?)\';.*X_Anti_Forge_Code = \'(\d+?)\'', data.text, re.DOTALL)
if match_obj:
Forge_Token = match_obj.group(1)
Forge_Code = match_obj.group(2)
return Forge_Token, Forge_Code
def login(username, passwd):
X_Anti_Forge_Token, X_Anti_Forge_Code = get_token()
login_headers = HEADERS.copy()
login_headers.update({'X-Requested-With': 'XMLHttpRequest', 'X-Anit-Forge-Token': X_Anti_Forge_Token, 'X-Anit-Forge-Code': X_Anti_Forge_Code})
postData = {
'isValidate': 'true',
'username': username,
'password': get_password(passwd),
'request_form_verifyCode': '',
'submit': '',
}
response = session.post('https://passport.lagou.com/login/login.json', data=postData, headers=login_headers)
print(response.text)
def get_cookies():
return requests.utils.dict_from_cookiejar(session.cookies)
if __name__ == "__main__":
username = '1371XXXXXXX'
passwd = 'xxxxxxxxxx'
login(username, passwd)
print(get_cookies())控制台结果
模拟登录以后便能获取到cookie,为爬虫做准备。代码拷贝就即能跑,不过拉勾网的登录校验随时会改变,若发现登录失败的可以在下面评论,我会抽空更新代码。
github地址:https://github.com/laichilueng/lagou_login
喜欢的可以去点个赞,谢谢

相关文章推荐
- Python爬虫:模拟登录带验证码网站
- Python网络爬虫之模拟登录(以知乎为例)
- Python爬虫模拟登录带验证码网站
- Python爬虫实战——模拟登录教务系统
- Python爬虫之模拟登录豆瓣获取最近看过的电影
- Python爬虫(四)——模拟登录imooc实战(利用cookie)
- [置顶]定向爬虫 - Python模拟新浪微博登录
- Python爬虫初学(三)—— 模拟登录知乎
- python爬虫获取强智科技教务系统学科成绩(模拟登录+成绩获取)
- python 爬虫 利用selenium模拟登录帐号 向requests中重设 cookie
- Python爬虫——5-2.使用selenium和phantomjs模拟QQ空间登录
- 【Python3.6爬虫学习记录】(八)Selenium模拟登录新浪邮箱并发送邮件
- Python爬虫实战之爬取链家广州房价_04链家的模拟登录(记录)
- 【python爬虫03】使用Scrapy框架模拟登录知乎
- 转载:python爬虫实践之模拟登录
- 【网络爬虫】【python】网络爬虫(三):模拟登录——伪装浏览器登录爬取过程
- Python爬虫入门:Urllib库使用详解(模拟CSDN登录)
- Python爬虫之模拟登录总结
- Python爬虫教程——模拟登录