Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
2016-10-08 09:33
579 查看
Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
2013-04-10 19:34:58| 分类:linux-NET |举报 |字号 订阅


下载LOFTER
我的照片书 |
本文分析基于Linux Kernel 1.2.13
原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7492423
更多请看专栏,地址http://blog.csdn.net/column/details/linux-kernel-net.html
作者:闫明
注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”(上)“表示分析是从底层向上分析、”(下)“表示分析是从上向下分析。
上一篇博文中我们从宏观上分析了Linux内核中网络栈的初始化过程,这里我们再从宏观上分析一下一个数据包在各网络层的传递的过程。
我们知道网络的OSI模型和TCP/IP模型层次结构如下:

上文中我们看到了网络栈的层次结构:
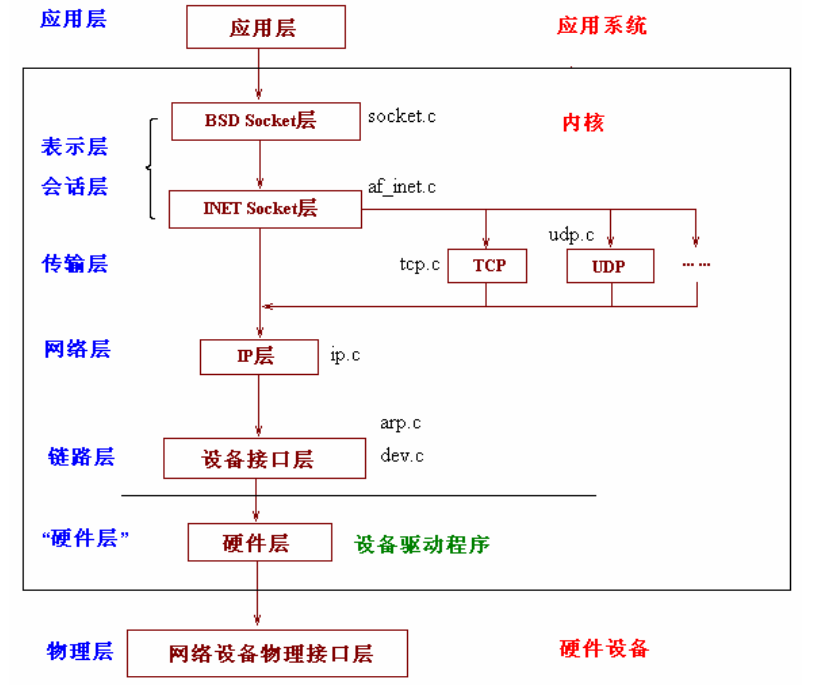
我们就从最底层开始追溯一个数据包的传递流程。
1、网络接口层
* 硬件监听物理介质,进行数据的接收,当接收的数据填满了缓冲区,硬件就会产生中断,中断产生后,系统会转向中断服务子程序。
* 在中断服务子程序中,数据会从硬件的缓冲区复制到内核的空间缓冲区,并包装成一个数据结构(sk_buff),然后调用对驱动层的接口函数netif_rx()将数据包发送给链路层。该函数的实现在net/inet/dev.c中,(在整个网络栈实现中dev.c文件的作用重大,它衔接了其下的驱动层和其上的网络层,可以称它为链路层模块的实现)
该函数的实现如下:
int netif_rx(struct sk_buff *skb)
{
int ret;
/* if netpoll wants it, pretend we never saw it */
if (netpoll_rx(skb))
return NET_RX_DROP;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
接着看函数enqueue_to_backlog
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
sd = &per_cpu(softnet_data, cpu);
local_irq_save(flags);
rps_lock(sd);
if (skb_queue_len(&sd->input_pkt_queue) <= netdev_max_backlog) {
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
sd->dropped++;
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
____napi_schedule()触发网络软中断
--------------------------------------
____napi_schedule()-->
__raise_softirq_irqoff(NET_RX_SOFTIRQ)
该函数中用到了bootom half技术,该技术的原理是将中断处理程序人为的分为两部分,上半部分是实时性要求较高的任务,后半部分可以稍后完成,这样就可以节省中断程序的处理时间。
在初始化中net_dev_init有一句open_softirq(NET_RX_SOFTIRQ, net_rx_action);
这样就转到net_rx_action执行下半部分了;
static void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
struct napi_struct *n;
int work, weight;
/* If softirq window is exhuasted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after(jiffies, time_limit)))
goto softnet_break;
local_irq_enable();
/* Even though interrupts have been re-enabled, this
* access is safe because interrupts can only add new
* entries to the tail of this list, and only ->poll()
* calls can remove this head entry from the list.
*/
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
have = netpoll_poll_lock(n);
weight = n->weight;
/* This NAPI_STATE_SCHED test is for avoiding a race
* with netpoll's poll_napi(). Only the entity which
* obtains the lock and sees NAPI_STATE_SCHED set will
* actually make the ->poll() call. Therefore we avoid
* accidentally calling ->poll() when NAPI is not scheduled.
*/
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
WARN_ON_ONCE(work > weight);
budget -= work;
local_irq_disable();
......
return;
softnet_break:
sd->time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
初始化时有设置sd->backlog.poll = process_backlog;下面看
static int process_backlog(struct napi_struct *napi, int quota)
{
int work = 0;
struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
#ifdef CONFIG_RPS
/* Check if we have pending ipi, its better to send them now,
* not waiting net_rx_action() end.
*/
if (sd->rps_ipi_list) {
local_irq_disable();
net_rps_action_and_irq_enable(sd);
}
#endif
napi->weight = weight_p;
local_irq_disable();
while (work < quota) {
struct sk_buff *skb;
unsigned int qlen;
while ((skb = __skb_dequeue(&sd->process_queue))) {
local_irq_enable();
__netif_receive_skb(skb);
local_irq_disable();
input_queue_head_incr(sd);
if (++work >= quota) {
local_irq_enable();
return work;
}
}
.......
return work;
}
进入netif_receive_skb()函数list_for_each_entry_rcu(ptype,&ptype_base[ntohs(type)
& PTYPE_HASH_MASK], list)按照协议类型依次由相应的协议模块进行处理,而所以的协议模块处理都会注册在ptype_base中,实际是链表结构。
static struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
而相应的协议模块是通过dev_add_pack()函数加入的
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
以IP为例,在kernel/net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.gso_send_check = inet_gso_send_check,
.gso_segment = inet_gso_segment,
.gro_receive = inet_gro_receive,
.gro_complete = inet_gro_complete,
};
在inet_init中有dev_add_pack(&ip_packet_type);
如果协议匹配成功,将会执行 ip_rcv,从而跳转到网络层
2、网络层
* 就以IP数据包为例来说明,那么从链路层向网络层传递时将调用ip_rcv函数。该函数完成本层的处理后会根据IP首部中使用的传输层协议来调用相应协议的处理函数。
UDP对应udp_rcv、TCP对应tcp_rcv、ICMP对应icmp_rcv、IGMP对应igmp_rcv(虽然这里的ICMP,IGMP一般成为网络层协议,但是实际上他们都封装在IP协议里面,作为传输层对待)
这个函数比较复杂,后续会详细分析。这里粘贴一下,让我们对整体了解更清楚
3、传输层
如果在IP数据报的首部标明的是使用TCP传输数据,则在上述函数中会调用tcp_rcv函数。该函数的大体处理流程为:
“所有使用TCP 协议的套接字对应sock 结构都被挂入tcp_prot 全局变量表示的proto 结构之sock_array 数组中,采用以本地端口号为索引的插入方式,所以当tcp_rcv 函数接收到一个数据包,在完成必要的检查和处理后,其将以TCP 协议首部中目的端口号(对于一个接收的数据包而言,其目的端口号就是本地所使用的端口号)为索引,在tcp_prot 对应sock 结构之sock_array 数组中得到正确的sock 结构队列,在辅之以其他条件遍历该队列进行对应sock 结构的查询,在得到匹配的sock
结构后,将数据包挂入该sock 结构中的缓存队列中(由sock 结构中receive_queue 字段指向),从而完成数据包的最终接收。”
该函数的实现也会比较复杂,这是由TCP协议的复杂功能决定的。附代码如下:
4、应用层
当用户需要接收数据时,首先根据文件描述符inode得到socket结构和sock结构,然后从sock结构中指向的队列recieve_queue中读取数据包,将数据包COPY到用户空间缓冲区。数据就完整的从硬件中传输到用户空间。这样也完成了一次完整的从下到上的传输。

相关文章推荐
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
- Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
- Linux内核--网络栈实现分析(二)--数据包的传递过程--转
- Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
- Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
- Linux内核--网络栈实现分析(二)--数据包的传递过程(上)
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
- Linux内核--网络栈实现分析(六)--应用层获取数据包(上)
- Linux内核--网络栈实现分析(六)--应用层获取数据包(上)
- Linux内核--网络栈实现分析(六)--应用层获取数据包(上)
- Linux内核--网络栈实现分析(十一)--驱动程序层(下)
- Linux内核--网络栈实现分析(八)--应用层发送数据(下)
- Linux内核--网络栈实现分析(一)--网络栈初始化--转
- 消息传递机制的具体实现过程(分析源码之后的总结)
- Linux内核源码分析--内核启动命令行的传递过程(Linux-3.0 ARMv7)