Hadoop学习笔记(10)-简述分布式数据仓库Hive原理
2016-10-04 23:32
746 查看
0.什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。简单的说就是:数据仓库是决策支持系统(dss)和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息的问题。
1.Hive简介
Hive是一个基于Hadoop的分布式数据仓库工具。也就是其是用来在分布式系统Hadoop框架上进行数据分析用的。其目的是为了分析查询结构化的海量数据。实际上,Hive最早是Facebook用于分析大量的数据用户和日志数据用的。之前学习的Hdfs,MapReduce,Hbase,他们在程序中使用API基本都涉及到java编程。Hive正好是给那些只懂得SQL语句,而不太懂得java编程的人使用的。Hive提供HiveSQL语言(类SQL编程接口),能直接转化为MapReduce程序在hadoop上跑。
下图1:展示Hive在Hadoop框架中的位置
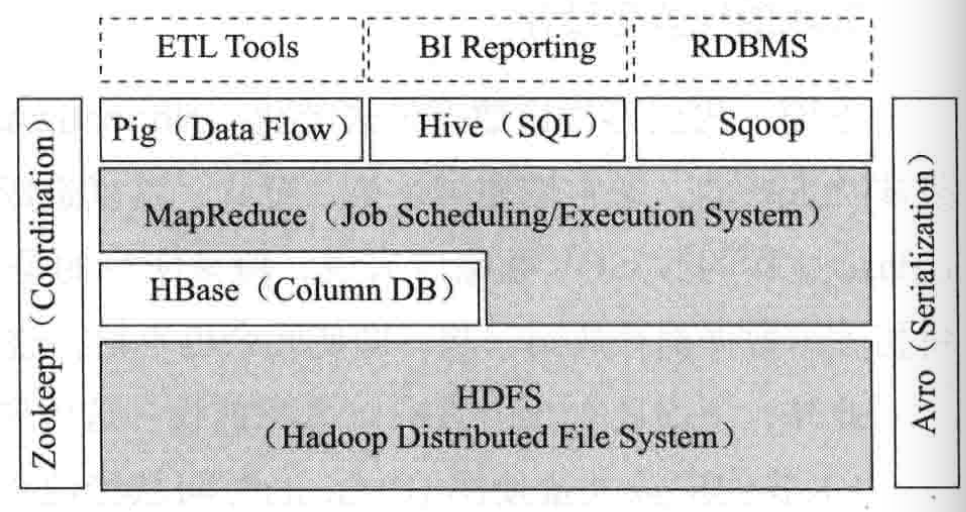
图1:Hive在Hadoop框架中的位置
可以看出,Hive是可以配置多种ETL(数据清洗:Extract-Transform-Load)工具使用的。
2.Hive结构组成
先看这张图2,这就是Hive的结构组成。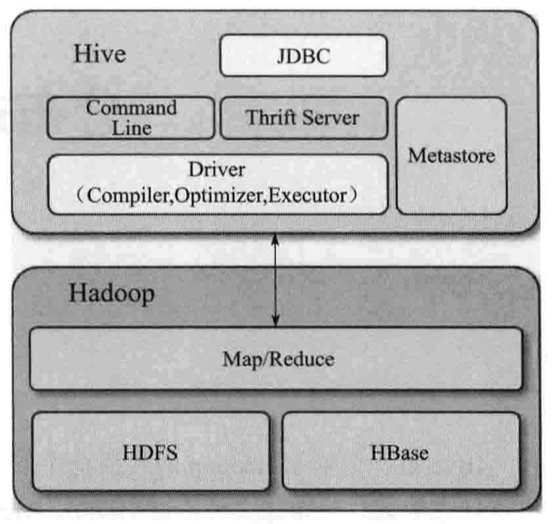
图2:Hive的结构组成
从图看其组成有如下部分:
1)编程接口JDBC:可提供用户进行编程使用。当然也有另外的用户接口:命令行和web UI。
2)命令行Command Line:也是提供给用户的接口。
3)Thrift Server:这个要展开说下。Apache Thrift 是 Facebook 实现的一种高效的、支持多种编程语言的远程服务调用的框架。目前流行的服务调用方式有很多种,例如基于 SOAP 消息格式的 Web Service,基于 JSON 消息格式的 RESTful 服务等。(还是有点抽象,笔试没完全明白,请笔者自行查找学习)。
4)元数据存储Metastore:用来存储Hive中的表结构信息,数据对象的格式信息。末日使用本地的Derby数据库,用户使用JDBC连接就要改成,支持远程货或本地JDBC的数据库,如MySQL。
5)Hive驱动Driver:驱动顾名思义是将各个部分组合成一个有机的执行系统。其中包括编译器(Comiler),执行引擎(Executor),Optimizer。
6)Hadoop数据存储和其处理:HiveSQL会编译成Hadoop的MapReduce程序运行。
另外说明:HiveServer2提供了一个新的命令行工具Beeline,本文不多说明(因为笔者还没学过)
3.Hive数据模型
有四个主要数据模型:表(Table),外部表(External Table),分区(Partition)和桶(Bucket)1)表:Hive对数据的管理维护是利用表来实现的。Hive表逻辑上分两部分,一部分是真实数据,另一部分是描述表形式(格式信息)的元数据。物理上是每个表的数据存储在一个HDFS文件目录下,表的数据形式的元数据存在关系型数据库中,默认Derby,常改到Mysql上。
2)外部表:默认数据都有Hive管理,所以数据会移动到数据仓库目录内(在HDFS的位置:“/…/hive/warehouse“,you hive
-site.xml文件配置)。但是当某些数据要求被其他数据库公用呢?于是就有了外部表。这个时候表的数据不写入数据仓库目录。即在HDFS的/hive/warehouse里也是看不到的。
注:外部表盒普通表不同,Load(加载)时候普通表写入HDFS数据仓库目录,而外部表不写入,但元数据都会创建在关系型数据库中。Drop(删除)时候普通表从HDFS数据仓库目录删除,在关系型数据库里的元数据也删除,而外部表仅删除元数据,保存在外部HDFS目录的数据不会删除。
3)分区:为了对表进行管理和高效查询,Hive有了分区功能。手动建立分区需要在HiveSQL语句中使用PARTITIONED BY子句。如:
CREATE TABLE logs(timestamp BIGINT,line STRING) PARTITIONED BY (date STRING, county STRING);
上面的命令是从data做主分区,county做子分区。
4)桶:Hive还能把表组织成桶。做法是一旦用户使用CLUSTERED BY命令分割出桶,Hive会对制定列进行hash计算,通过得到的hash值将列下数据切割成一组桶,并使每个桶对应于该列下的一个存储文件。这样有了桶后,查询就能更高效,因为是在查询列时,先通过hash值找到桶再做查找,避免的对所以数据的查询。另一方面,这样不遍历所有数据,取样也变的更加方面了。
如下语句:
CREAT TABLE users(id INT,name STRING) CLUSTERED BY (id) INTO 4 BUCKETS;
这里创建的users表就是以列id进行分割桶,通过hash计算来分割成4个桶。查找时候会先通过hash值,找到4个桶中一个,再进行查找,这样就高效多了,避免了查找所以数据。
4.元数据存储
Hive系统安装自带Derby数据库。但为了让多用户和远程可访问,一般更换成更大的数据库:如MySQL。注:hive可以有三种模式链接数据库:
1)单用户模式:利用内部的Derby,一般用于单机模式测试
2)多用户模式:从一台机器通过JDBC和网络连接到另一台机器的Hive。这里要换数据库,不能再用Derby,可改MySQL。
3)远程服务器模式:用于非java客户端链接远程的Hive,用启动一个MetaStoreServer,然后客户端通过Thrift协议访问(这里笔者没这个实验条件,所以也知道具体操作)
5.Hive数据类型
Hive支持多种数据类型,见下图3。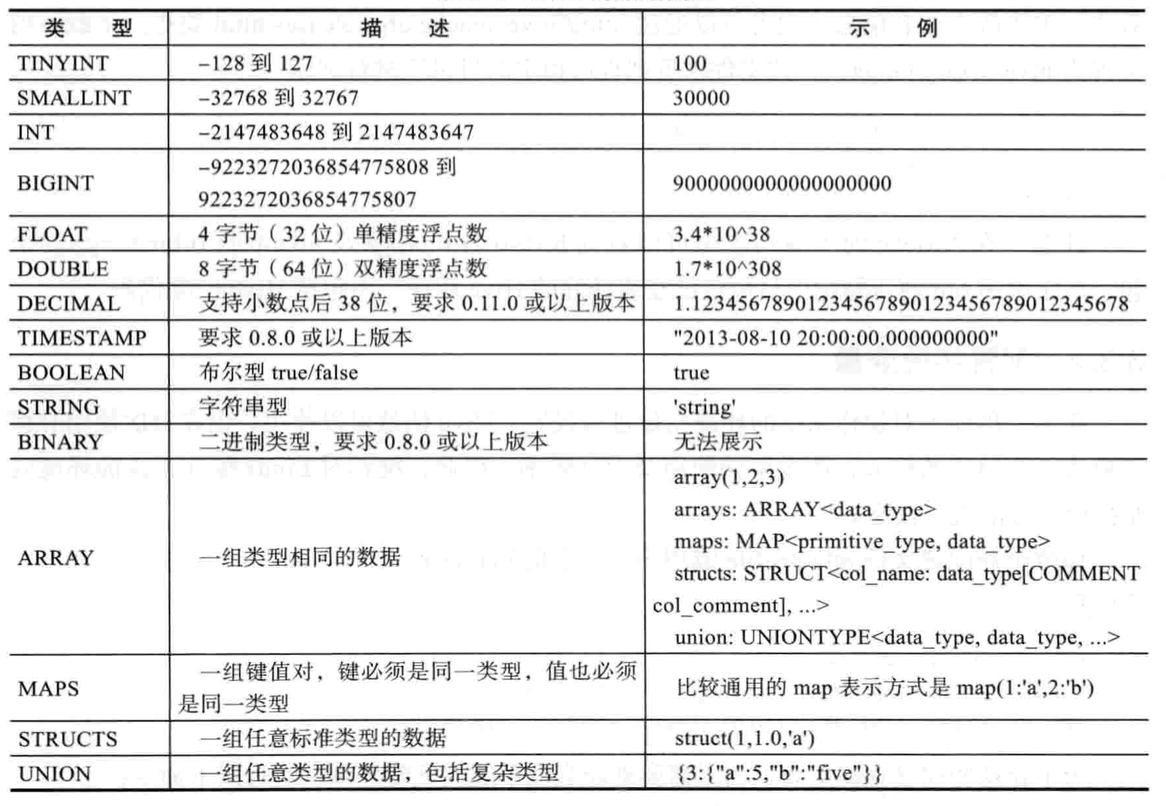
图3:Hive数据类型
Xianming

相关文章推荐
- Hadoop学习笔记(6)-简述分布式文件系统HDFS原理
- 基于Hadoop的数据仓库Hive 学习指南
- 大数据笔记10:大数据之Hadoop的MapReduce的原理
- hadoop学习笔记之HiveSQL 数据查询
- Hadoop学习笔记(7)-简述MapReduce计算框架原理
- ES学习笔记-elasticsearch-hadoop导入hive数据到es的实现探究
- hive--基于Hadoop的数据仓库Hive 学习指南
- 大数据-Hadoop学习笔记10
- 基于Hadoop的数据仓库Hive 学习指南
- Hadoop学习笔记(8)-简述分布式数据库Hbase原理
- 基于Hadoop的数据仓库Hive 学习指南
- 数据、进程-云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战-by小雨
- 【C Prime Plus】学习笔记,Chapter 10,用const 修饰形参 保护数据,以防修改
- Hadoop学习笔记(七):使用distcp并行拷贝大数据文件
- 云计算学习笔记003---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- IOS学习笔记(10)UITableView展示数据 cell删除 构建页眉页脚
- 数据仓库学习笔记
- oracle 11g 学习笔记 10_31_管理表空间和数据文件
- BI学习笔记之六 - 数据仓库介绍
- oracle 11g 学习笔记 10_31(2)_维护数据的完整性