大数据笔记10:大数据之Hadoop的MapReduce的原理
2015-09-20 11:02
337 查看
1. MapReduce(并行处理的框架)
思想:分而治之,一个大任务分解成多个小的子任务(map),并行执行后,合并结果(Reduce)
(1)大任务分解成多个小任务,这个过程就是map;
(2)多个小任务结果的合并,这个过程就是Reduce;
2.通过一个案例说明MapReduce思想如下:
一副牌(不含大小王)有52张,共有1000副牌,也就是说应该有52000张扑克牌,但是如果其中少了1张,也就是变成了51999张扑克牌,如下:

现在少了1张牌,我们想把它找出来,该怎么办呢?
(1)第1步:首先我们把这个51999张牌,分成5份(相当于map操作,一个大任务分解成多个小任务):
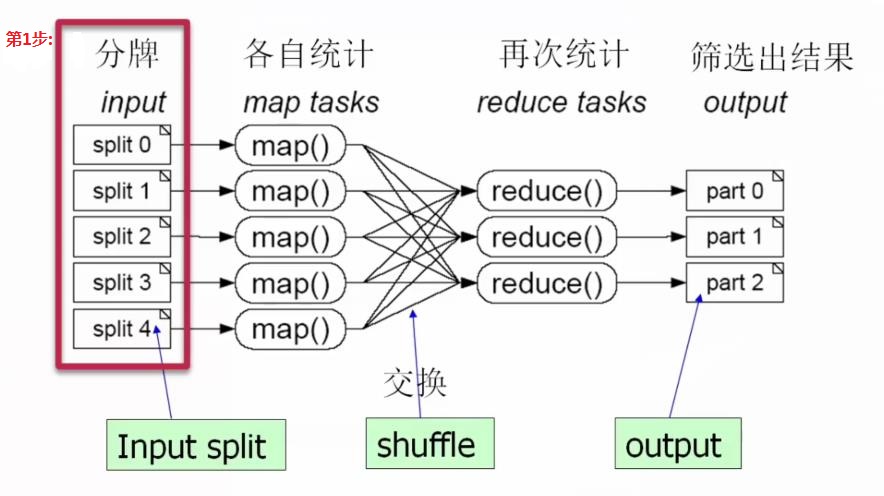
这里把51999张牌,分成5份([b]随机分配,可以不均等),分成给5个人去做:[/b]

(2)第2步:51999张牌,分成5份,分给5个人去做,这5个人的中每个人都执行map tasks操作,如下:

每个map tasks任务都是各自执行统计扑克牌中不同花色以及不同花色的数量(每个map tasks都是针对分配给自己那一份扑克牌进行操作)
(3)第3步:进行数据交换操作,如下:
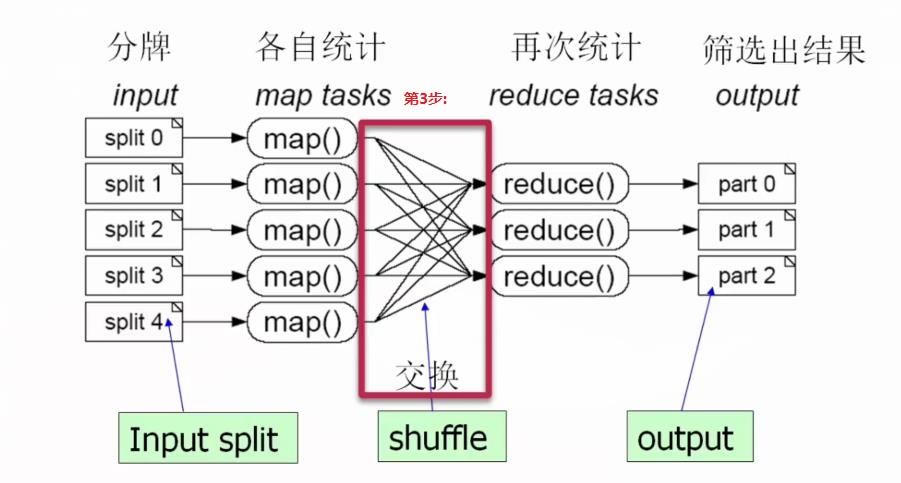
(4)第4步:对数据进行规约操作,[b]规约就是把上面不同map tasks得到结果" 合并同类项 ",进行再次统计,如下:[/b]
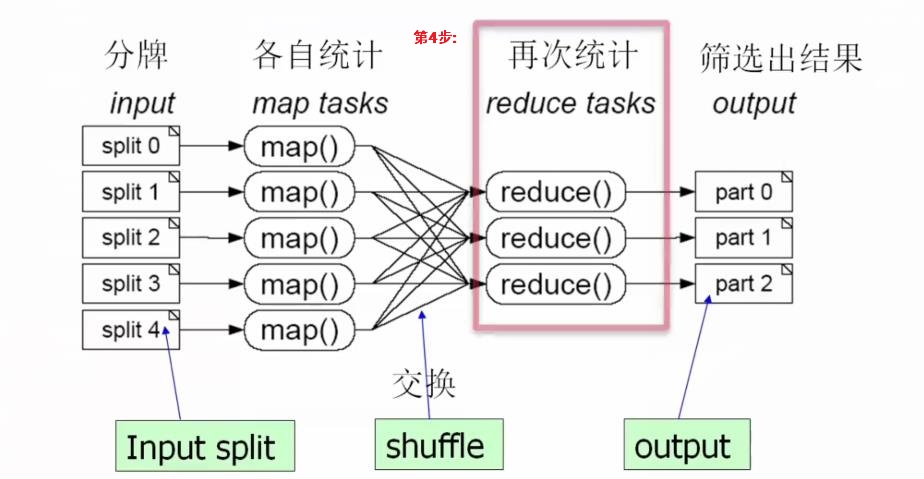
e.g:

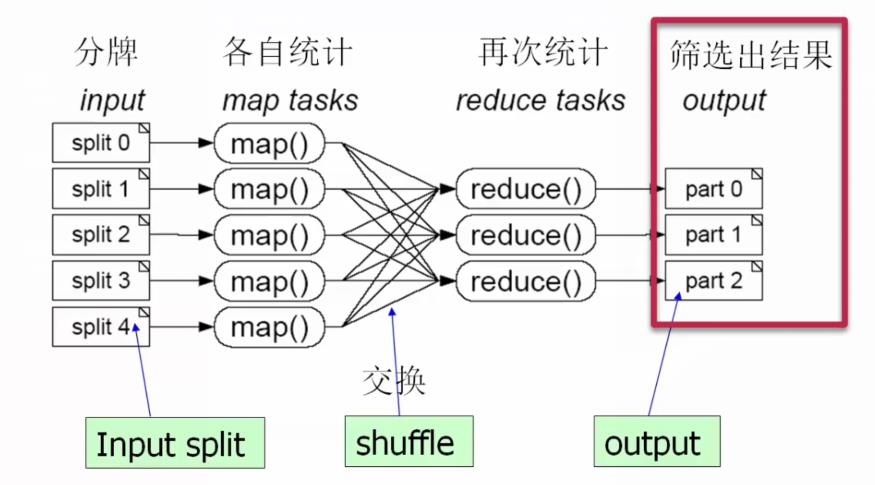
(5)第5步:导出了统计结果。
思想:分而治之,一个大任务分解成多个小的子任务(map),并行执行后,合并结果(Reduce)
(1)大任务分解成多个小任务,这个过程就是map;
(2)多个小任务结果的合并,这个过程就是Reduce;
2.通过一个案例说明MapReduce思想如下:
一副牌(不含大小王)有52张,共有1000副牌,也就是说应该有52000张扑克牌,但是如果其中少了1张,也就是变成了51999张扑克牌,如下:
现在少了1张牌,我们想把它找出来,该怎么办呢?
(1)第1步:首先我们把这个51999张牌,分成5份(相当于map操作,一个大任务分解成多个小任务):
这里把51999张牌,分成5份([b]随机分配,可以不均等),分成给5个人去做:[/b]
(2)第2步:51999张牌,分成5份,分给5个人去做,这5个人的中每个人都执行map tasks操作,如下:
每个map tasks任务都是各自执行统计扑克牌中不同花色以及不同花色的数量(每个map tasks都是针对分配给自己那一份扑克牌进行操作)
(3)第3步:进行数据交换操作,如下:
(4)第4步:对数据进行规约操作,[b]规约就是把上面不同map tasks得到结果" 合并同类项 ",进行再次统计,如下:[/b]
e.g:
(5)第5步:导出了统计结果。

相关文章推荐
- VS2010编译Boost 1.56 http://blog.csdn.net/kangroger/article/details/39393769
- 大数据笔记09:大数据之Hadoop的HDFS使用
- Aizu 2249 Road Construction(SPFA算法变形,好题)
- Failed to read key from keystore解决方案
- 大数据笔记08:云计算(云)
- Climbing Stairs 解答
- CLOSE_WAIT的产生以及影响和解决方案
- 读完这100篇论文 就能成大数据高手
- YoMail,Gmail死忠粉的福音——直接收发Gmail邮件
- YoMail,Gmail死忠粉的福音——直接收发Gmail邮件
- dojo EnhancedGrid的两种实现方式对比,转载自http://blog.csdn.net/earthhour/article/details/17203515
- AIDL--------应用之间的通信接口
- Codeforces Round #320 (Div. 2) 579A Raising Bacteria(脑洞)
- Paint
- Trailing Zeroes (III)(lightoj 二分好题)
- 大数据滥用 借贷平台肆意妄为的背后
- relocation R_ARM_THM_MOVW_ABS_NC against `a local symbol' can not be used when making a shared objec
- 增益 Gain 分贝 dB
- Light oj 1138 - Trailing Zeroes (III)
- mexTrainDL - SPAms