机器学习的一些基本概念
2016-09-21 16:16
246 查看
初入人工智能专业的小菜鸟,导师让先看看深度学习方面的论文,查找了几天资料,发现如果一些基础不打牢,是没办法继续后序的学习的。为此,先饿补饿补深度学习方面的一些基础知识。
大牛说, 深度学习的概念源于人工神经网络的研究,建立在含多隐层的神经网络模型基础上。 因此,首先我们要学习神经网络相关知识,而在学习神经网络之前,又需要我们对机器学习一些基本概念进行了解。
这是目前遇到的一些概念,后续遇到新的概念将在此继续增加。
ANN:
人工神经网络(Artificial
Neural Networks)
DNN:
深度神经网络(Deep Neural Networks)
CNN:
卷积神经网络(Convolutional
Neural Network)
CNN是深度学习算法在图像处理领域的一个应用。
监督学习((supervised learning)):
简单而言,对于一个学习器,如果我们知道它的输入数据和输出数据,根据这些输入和输出数据,我们训练出来一些参数,然后利用这些参数去预测未知的新输入的数据,得到输出,最后将输出作简单的判断来达到分类的目的。其中利用已知样本(包括输入和输出数据)去训练参数的过程,可以称为监督学习。 与无监督的学习相比,监督学习的特点在于,对每一个输入数据都有已知的输出数据与之对应。也就是说,监督学习更像是一个分类器,我们已知哪些数据对应哪些类别,对新来的数据,通过训练出来的参数,将其划分到已知的类别中。例如,假设我们已知如下样本,输入1,2,3,4得到A,输入5,6,7,8得到B,训练后,此时再输入数据5,学习器将把5判为类别B,即学习器在已学到的类别A和B中选择。
无监督学习(unsupervised learning):
无监督学习的特点在于,只有一堆输入数据,我们并不知道输出是什么,即不知道有哪些类,无监督学习相当于聚类,即将一堆复杂的数据,通过学习,找出数据之间的规律,自动将数据分类几类。 举个例子,我们外行人并不知道蝴蝶有哪些种类,如果现在给我们一群蝴蝶,我们可以根据肉眼,将长得像的蝴蝶放在一起(虽然并不知道这类蝴蝶叫什么名字),就这样将这群蝴蝶进行聚类,下次再来一只蝴蝶,我们可以蝴蝶的外貌,将其分到长得像的那堆里面。
像这种事先并不知道输出结果,在输入数据中寻找数据特征进行聚类的学习过程,就是无监督的学习过程。
人工规则:
就是数据本来没有规则,即并不知道数据对应的输出,但是通过人工手段,手工将输入数据对应到一个输出,并进行训练的学习过程,成为有人工规则参与的学习过程。
sigmoid函数:
对于二分类问题,输出层是sigmoid函数:


逻辑回归:
采用sigmoid函数为回归函数的模型成为逻辑回归模型,该回归也称为逻辑回归,常用于处理二分类问题。
逻辑回归是非线性回归,除了回归函数与线性回归不一致,其他的处理方法与线性回归一致。
二部图:
二分图也叫二部图,是图论中一种特殊模型。
设G=(V,E)是一个无向图,如果顶点集合V可分割为两个互不相交的子集(A,B),且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集,则称图G为一个二分图。
高斯分布:
正态分布也叫高斯分布,高斯分布由均值和方差两个参数来确定
高斯变量:
符合正态随机分布的变量,称为高斯变量
混合高斯模型(GMM,Gaussian Mixture Model):
高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。
在深度学习中,混合高斯模型常被用于语音识别领域。
激活函数:
在神经网络模型中,对输入x,其对应的输出为 y=f(x),其中映射关系f()称为激活函数。
激活值:
激活函数的输出值,即神经网络中每层每个神经元的输出值。
向前传播:
神经网络里面,由输入层向输出层方向,由前面一层的输出,作为下一层的输入,一层一层计算每层的输出过程,这种方向的计算方法称为向前传播。
代价函数:
个人理解,又可称为目标函数,即为使模型达到最优值,建立的一个关于自变量的函数,例如:
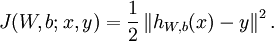
残差:
是指实际值与估计值之间的差
熵:
信息熵反应的是一个系统的有序程度,系统越有序,其对应的熵值越低
相对熵:
相对熵用来描述两个随机分布的差异程度,两个分布差异越大,其对应的相对熵也越大。设两个分布的概率密度函数分别为p(x)和q(x),则他们的信息熵为:

平凡解:
Ax=0中,x=0的解称为平凡解。
浅层学习:
早期的人工神经网络模型,如BP神经网络模型,以及由BP神经网络模型引申的SVN、Boosting等模型,这些模型的结构大都可以看成隐含层只包含一层节点,或者甚至隐含层没有节点,这些模型可以称为浅层模型,其进行的学习是浅层学习。
深度学习:
深度学习相对浅层学习,有以下两个特点:
1、增加隐含层的节点层数,通常有5/6层,有时甚至超过10层
2、强调数据特征的提取,将输入数据原有的特征空间,经过逐层特征变换,映射到一个新的特征空间,从而进行更好的分类和预测。
大牛说, 深度学习的概念源于人工神经网络的研究,建立在含多隐层的神经网络模型基础上。 因此,首先我们要学习神经网络相关知识,而在学习神经网络之前,又需要我们对机器学习一些基本概念进行了解。
这是目前遇到的一些概念,后续遇到新的概念将在此继续增加。
ANN:
人工神经网络(Artificial
Neural Networks)
DNN:
深度神经网络(Deep Neural Networks)
CNN:
卷积神经网络(Convolutional
Neural Network)
CNN是深度学习算法在图像处理领域的一个应用。
监督学习((supervised learning)):
简单而言,对于一个学习器,如果我们知道它的输入数据和输出数据,根据这些输入和输出数据,我们训练出来一些参数,然后利用这些参数去预测未知的新输入的数据,得到输出,最后将输出作简单的判断来达到分类的目的。其中利用已知样本(包括输入和输出数据)去训练参数的过程,可以称为监督学习。 与无监督的学习相比,监督学习的特点在于,对每一个输入数据都有已知的输出数据与之对应。也就是说,监督学习更像是一个分类器,我们已知哪些数据对应哪些类别,对新来的数据,通过训练出来的参数,将其划分到已知的类别中。例如,假设我们已知如下样本,输入1,2,3,4得到A,输入5,6,7,8得到B,训练后,此时再输入数据5,学习器将把5判为类别B,即学习器在已学到的类别A和B中选择。
无监督学习(unsupervised learning):
无监督学习的特点在于,只有一堆输入数据,我们并不知道输出是什么,即不知道有哪些类,无监督学习相当于聚类,即将一堆复杂的数据,通过学习,找出数据之间的规律,自动将数据分类几类。 举个例子,我们外行人并不知道蝴蝶有哪些种类,如果现在给我们一群蝴蝶,我们可以根据肉眼,将长得像的蝴蝶放在一起(虽然并不知道这类蝴蝶叫什么名字),就这样将这群蝴蝶进行聚类,下次再来一只蝴蝶,我们可以蝴蝶的外貌,将其分到长得像的那堆里面。
像这种事先并不知道输出结果,在输入数据中寻找数据特征进行聚类的学习过程,就是无监督的学习过程。
人工规则:
就是数据本来没有规则,即并不知道数据对应的输出,但是通过人工手段,手工将输入数据对应到一个输出,并进行训练的学习过程,成为有人工规则参与的学习过程。
sigmoid函数:
对于二分类问题,输出层是sigmoid函数:
这是因为sigmoid函数可以把实数域光滑的映射到[0,1]空间。函数值恰好可以解释为属于正类的概率(概率的取值范围是0~1)。另外,sigmoid函数单调递增,连续可导,导数形式非常简单,是一个比较合适的函数。
逻辑回归:
采用sigmoid函数为回归函数的模型成为逻辑回归模型,该回归也称为逻辑回归,常用于处理二分类问题。
逻辑回归是非线性回归,除了回归函数与线性回归不一致,其他的处理方法与线性回归一致。
二部图:
二分图也叫二部图,是图论中一种特殊模型。
设G=(V,E)是一个无向图,如果顶点集合V可分割为两个互不相交的子集(A,B),且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集,则称图G为一个二分图。
高斯分布:
正态分布也叫高斯分布,高斯分布由均值和方差两个参数来确定
高斯变量:
符合正态随机分布的变量,称为高斯变量
混合高斯模型(GMM,Gaussian Mixture Model):
高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。
在深度学习中,混合高斯模型常被用于语音识别领域。
激活函数:
在神经网络模型中,对输入x,其对应的输出为 y=f(x),其中映射关系f()称为激活函数。
激活值:
激活函数的输出值,即神经网络中每层每个神经元的输出值。
向前传播:
神经网络里面,由输入层向输出层方向,由前面一层的输出,作为下一层的输入,一层一层计算每层的输出过程,这种方向的计算方法称为向前传播。
代价函数:
个人理解,又可称为目标函数,即为使模型达到最优值,建立的一个关于自变量的函数,例如:
残差:
是指实际值与估计值之间的差
熵:
信息熵反应的是一个系统的有序程度,系统越有序,其对应的熵值越低
相对熵:
相对熵用来描述两个随机分布的差异程度,两个分布差异越大,其对应的相对熵也越大。设两个分布的概率密度函数分别为p(x)和q(x),则他们的信息熵为:
平凡解:
Ax=0中,x=0的解称为平凡解。
浅层学习:
早期的人工神经网络模型,如BP神经网络模型,以及由BP神经网络模型引申的SVN、Boosting等模型,这些模型的结构大都可以看成隐含层只包含一层节点,或者甚至隐含层没有节点,这些模型可以称为浅层模型,其进行的学习是浅层学习。
深度学习:
深度学习相对浅层学习,有以下两个特点:
1、增加隐含层的节点层数,通常有5/6层,有时甚至超过10层
2、强调数据特征的提取,将输入数据原有的特征空间,经过逐层特征变换,映射到一个新的特征空间,从而进行更好的分类和预测。

相关文章推荐
- 【机器学习】一些基本概念及符号系统
- 机器学习的一些基本概念
- 机器学习一些基本概念(笔记)
- 机器学习之一些基本概念及符号系统
- 机器学习中的一些基本概念 (未完待续)
- 机器学习的一些基本概念
- 【模式识别与机器学习】模式识别中的一些基本概念
- 机器学习中的一些基本概念
- 数据库设计的一些基本概念(读书笔记)
- 概率论的一些基本概念
- BI的一些基本概念,体系结构
- 数字证书的一些基本概念
- 一些最基本的概念,适合刚接触java者
- C++中一些基本概念
- 数据结构中关于图的一些基本概念
- 数据结构中关于树的一些基本概念--随时更新 推荐
- Xml的一些基本概念
- UML学习笔记(二):复习面向对象的一些基本概念
- 数据库一些基本概念
- 有关MQ中的一些基本概念(二)