深度学习算法--自动编码器
2016-09-22 21:32
246 查看
深度学习最常见的一种算法,就是自动编码器算法了。
这种算法的大致思想是:将神经网络的隐含层看成是一个编码器和解码器,输入数据经过隐含层的编码和解码,到达输出层时,确保输出的结果尽量与输入数据保持一致。也就是说,隐含层是尽量保证输出数据等于输入数据的。 这样做的一个好处是,隐含层能够抓住输入数据的特点,使其特征保持不变。例如,假设输入层有100个神经元,隐含层只有50个神经元,输出层有100个神经元,通过自动编码器算法,我们只用隐含层的50个神经元就找到了100个输入层数据的特点,能够保证输出数据和输入数据大致一致,就大大降低了隐含层的维度。
既然隐含层的任务是尽量找输入数据的特征,也就是说,尽量用最少的维度来代表输入数据,因此,我们可以想象,隐含层各层之间的参数构成的参数矩阵,应该尽量是个稀疏矩阵,即各层之间有越多的参数为0就越好。
假设隐含层每个神经元的平均激活值为:
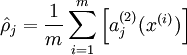
,其中
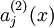
表示在给定输入为

情况下,自编码神经网络隐藏神经元

的激活值,由各层参数
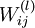
和偏置项
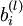
,以及输入数据构成。
我们的目标是,让尽可能多的神经元处于抑制状态,即
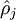
越小越好,于是令:
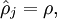
其中
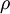
是稀疏性参数,通常是接近0的最小值。
为了使
尽可能地接近
,我们采用 相对熵
类似的概念来刻画
与
的接近程度(相对熵用来描述两个随机分布的差异程度,两个分布差异越大,其对应的相对熵也越大,如果两个分布相同,则它们的相对熵为0。设两个分布的概率密度函数分别为p(x)和q(x),则他们的信息熵为:

)。因此,我们构造函数(也成惩罚因子):
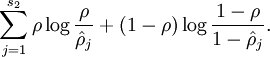
令
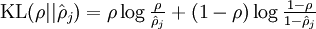
,则上式也可表示为:
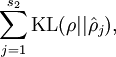
最后,把我们自动编码器模型的目标函数设为:
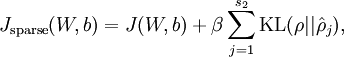
其中,
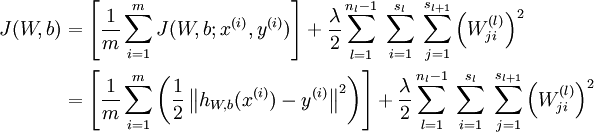
称为全局代价函数,
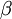
为惩罚因子的权重。这个全局目标函数,是关于参数
和
的函数。通过类似反向梯度求导算法,求得
min
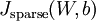
时各参数的值,即可得到局部最优解。
这种算法的大致思想是:将神经网络的隐含层看成是一个编码器和解码器,输入数据经过隐含层的编码和解码,到达输出层时,确保输出的结果尽量与输入数据保持一致。也就是说,隐含层是尽量保证输出数据等于输入数据的。 这样做的一个好处是,隐含层能够抓住输入数据的特点,使其特征保持不变。例如,假设输入层有100个神经元,隐含层只有50个神经元,输出层有100个神经元,通过自动编码器算法,我们只用隐含层的50个神经元就找到了100个输入层数据的特点,能够保证输出数据和输入数据大致一致,就大大降低了隐含层的维度。
既然隐含层的任务是尽量找输入数据的特征,也就是说,尽量用最少的维度来代表输入数据,因此,我们可以想象,隐含层各层之间的参数构成的参数矩阵,应该尽量是个稀疏矩阵,即各层之间有越多的参数为0就越好。
假设隐含层每个神经元的平均激活值为:
,其中
表示在给定输入为
情况下,自编码神经网络隐藏神经元
的激活值,由各层参数
和偏置项
,以及输入数据构成。
我们的目标是,让尽可能多的神经元处于抑制状态,即
越小越好,于是令:
其中
是稀疏性参数,通常是接近0的最小值。
为了使
尽可能地接近
,我们采用 相对熵
类似的概念来刻画
与
的接近程度(相对熵用来描述两个随机分布的差异程度,两个分布差异越大,其对应的相对熵也越大,如果两个分布相同,则它们的相对熵为0。设两个分布的概率密度函数分别为p(x)和q(x),则他们的信息熵为:
)。因此,我们构造函数(也成惩罚因子):
令
,则上式也可表示为:
最后,把我们自动编码器模型的目标函数设为:
其中,
称为全局代价函数,
为惩罚因子的权重。这个全局目标函数,是关于参数
和
的函数。通过类似反向梯度求导算法,求得
min
时各参数的值,即可得到局部最优解。

相关文章推荐
- 可变数组
- 重新初始化RAC的OCR盘和Votedisk盘,修复RAC系统
- VNC连接Linux
- 打印完全平方数
- 利用两个队列模仿队列
- xenomai 的权限配置
- 第六章 第九节 焦点与tab顺序
- UNIX命令行基础(一)
- 搭建caffe环境时“error: hdf5.h”找不到的解决方法
- explain、profile
- struts 和servlet APi的耦合方式
- macos 10.12无法关机解决办法
- web_custom_request和web_submit_data
- 网上推荐的学习ucosii的三本书
- Java Sokect编程之HTTP请求
- 文件I/O实践(3) --文件共享与fcntl
- centos 7配置网络 更新yum源
- java集合类深入分析之PriorityQueue(二)
- struts 的解耦和方式
- AndroidStudio中使用AndroidAnnotation的简单介绍