一个分布式服务器集群架构方案
2016-09-14 09:00
567 查看
| [align=left]问题导读[/align] [align=left] [/align] [align=left]1.分布式和集群是如何提升效率的?[/align] [align=left]2.HAProxy有哪些优点?[/align]   0x01.大型网站演化 [align=left]简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。[/align] [align=left]集群主要分为:高可用集群(High Availability Cluster),负载均衡集群(Load Balance Cluster,nginx即可实现),科学计算集群(High Performance Computing Cluster)。[/align] [align=left]分布式是指将不同的业务分布在不同的地方;而集群指的是将几台服务器集中在一起,实现同一业务。分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。[/align] [align=left]之前在网上看到一篇关于大型网站演化的博客。http://www.cnblogs.com/leefreeman/p/3993449.html[/align] [align=left]每个大型网站都会有不同的架构模式,而架构内容也就是在处理均衡负载,缓存,数据库,文件系统等,只是在不同的环境下,不同的条件下,架构的模型不一样,目的旨在提高网站的性能。[/align] [align=left]最初的架构只有应用程序,数据库,文件服务。[/align]  [align=left]到后来,分布式服务、集群架设。[/align]  0x02.关于均衡负载方案 [align=left]在上一篇,《Nginx反向代理实现均衡负载》讨论过过的nginx现实均衡负载方案,这里选择另一种HAProxy+Keepalived双机高可用均衡负载方案。[/align] [align=left]HAProxy是免费、极速且可靠的用于为TCP和基于HTTP应用程序提供高可用、负载均衡和代理服务的解决方案,尤其适用于高负载且需要持久连接或7层处理机制的web站点。[/align] [align=left]不论是Haproxy还是Keepalived甚至是上游服务器均提高生产力并增强可用性,也就是如下架构中Haproxy,Keepalived,Httpd服务器任意宕机一台服务还是可以正常运行的。[/align] [align=left]HAProxy的优点:[/align] [align=left]1、HAProxy是支持虚拟主机的,可以工作在4、7层(支持多网段);[/align] [align=left]2、能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作;[/align] [align=left]3、支持url检测后端的服务器;[/align] [align=left]4、本身仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的;[/align] [align=left]5、HAProxy可以对Mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡;[/align] 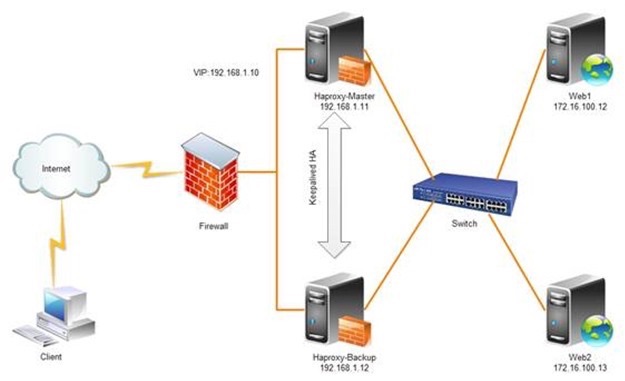 0x03.关于Redis缓存方案 [align=left]缓存分为服务器缓存和应用程序缓存。[/align] [align=left]关于应用程序内缓存,已经在Jue后台框架里面做了模块处理了。[/align] [align=left]关于服务器缓存,主要缓存服务器文件,减少服务器和php交互,减少均衡负载服务器和应用程序服务器交互。[/align] [align=left]缓存里面有一种典型的memcached,现在用的多的是redis轻量级缓存方案。[/align] [align=left]关于memcached与redis,看这篇 《Memcached vs Redis?》[/align] [align=left]Redis主要将数据存储在各种格式:列表,数组,集合和排序集,一次能接受多个命令,阻塞读写,等待直到另一个进程将数据写入高速缓存。[/align]  [align=left]一篇关于Reids缓存方案。《高可用、开源的Redis缓存集群方案》[/align] 0x04.关于搜索引擎Sphinx方案 [align=left](第一期不做,后期需求时候考虑)[/align] [align=left]Sphinx是俄罗斯人开发的,号称是很吊啦,千万级数据检索,每秒10MB/s,搭过环境。[/align] [align=left]Sphinx和MySQL是基于数据库的全文引擎,创建索引是B+树和hash key-value的方式。[/align] [align=left]原理类似于用底层C检索MySQL,然后弄出一个sphinx.conf配置文件,索引与搜索均以这个文件为依据进行,要进行全文检索,首先就要配置好sphinx.conf,告诉sphinx哪些字段需要进行索引,哪些字段需要在where,orderby,groupby中用到。[/align] [align=left]Sphinx中文[/align] 0x05.关于NoSQL快速存储方案 [align=left]NoSQL在这里的使用价值是处理一些琐事,比如用户个人网站的一些css值,height,width,color等等的小而繁多的数据,采用NoSQL旨在提升数据库速度,减少对MySQL的SELECT请求。[/align] [align=left]关于NoSQL的方案很多了,选一个简单的MongDB好了。[/align] 0x06.关于分布式MySQL方案 [align=left](做分布式MySQL还没尝试过,初期也不清楚mysql所需要的压力,所以第一期不打算做分布式MySQL)[/align] [align=left]《标准MySQL数据库外的5个开源兼容方案》[/align] 0x07.分布式集群方案 [align=left]综合起来,大致就是如下模型,初探分布式架构,很多模块将就形势做调整,时时更新中,待续。。。[/align]  本文出自夏日小草:http://homeway.me/2014/12/10/think-about-distributed-clusters/ |

相关文章推荐
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 一个分布式服务器集群架构方案
- 分布式服务器集群架构方案思考
- 分布式服务器集群架构方案思考
- 分布式服务器集群架构方案思考
- 分布式服务器集群架构方案思考
- 大数据分布式集群架构上gis应用方案-开源greenplum+开源postgis搭建
- 架构分布式____Redis集群架构各种方案分析