storm消费kafka实现实时计算
2016-09-05 15:53
429 查看
大致架构
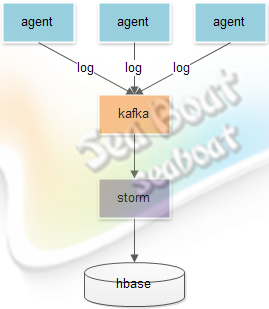
* 每个应用实例部署一个日志agent
* agent实时将日志发送到kafka
* storm实时计算日志
* storm计算结果保存到hbase
storm消费kafka
创建实时计算项目并引入storm和kafka相关的依赖<dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.0.2</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <version>1.0.2</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.8.2.0</version> </dependency>
创建消费kafka的spout,直接用storm提供的KafkaSpout即可。
创建处理从kafka读取数据的Bolt,JsonBolt负责解析kafka读取到的json并发送到下个Bolt进一步处理(下一步处理的Bolt不再写,只要继承BaseRichBolt就可以对tuple处理)。
public class JsonBolt extends BaseRichBolt {
private static final Logger LOG = LoggerFactory
.getLogger(JsonBolt.class);
private Fields fields;
private OutputCollector collector;
public JsonBolt() {
this.fields = new Fields("hostIp", "instanceName", "className",
"methodName", "createTime", "callTime", "errorCode");
}
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String spanDataJson = tuple.getString(0);
LOG.info("source data:{}", spanDataJson);
Map<String, Object> map = (Map<String, Object>) JSONValue
.parse(spanDataJson);
Values values = new Values();
for (int i = 0, size = this.fields.size(); i < size; i++) {
values.add(map.get(this.fields.get(i)));
}
this.collector.emit(tuple, values);
this.collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(this.fields);
}
}创建拓扑MyTopology,先配置好KafkaSpout的配置SpoutConfig,其中zk的地址端口和根节点,将id为KAFKA_SPOUT_ID的spout通过shuffleGrouping关联到jsonBolt对象。
public class MyTopology {
private static final String TOPOLOGY_NAME = "SPAN-DATA-TOPOLOGY";
private static final String KAFKA_SPOUT_ID = "kafka-stream";
private static final String JsonProject_BOLT_ID = "jsonProject-bolt";
public static void main(String[] args) throws Exception {
String zks = "132.122.252.51:2181";
String topic = "span-data-topic";
String zkRoot = "/kafka-storm";
BrokerHosts brokerHosts = new ZkHosts(zks);
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, zkRoot,
KAFKA_SPOUT_ID);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.zkServers = Arrays.asList(new String[] { "132.122.252.51" });
spoutConf.zkPort = 2181;
JsonBolt jsonBolt = new JsonBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(KAFKA_SPOUT_ID, new KafkaSpout(spoutConf));
builder.setBolt(JsonProject_BOLT_ID, jsonBolt).shuffleGrouping(
KAFKA_SPOUT_ID);
Config config = new Config();
config.setNumWorkers(1);
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config,
builder.createTopology());
Utils.waitForSeconds(100);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], config,
builder.createTopology());
}
}
}本地测试时直接不带运行参数运行即可,放到集群是需带拓扑名称作为参数。
另外需要注意的是:KafkaSpout默认从上次运行停止时的位置开始继续消费,即不会从头开始消费一遍,因为KafkaSpout默认每2秒钟会提交一次kafka的offset位置到zk上,如果要每次运行都从头开始消费可以通过配置实现。
========广告时间========
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
为什么写《Tomcat内核设计剖析》
=========================
欢迎关注:


相关文章推荐
- storm消费kafka实现实时计算
- [bigdata] flume+kafka+storm实现实时分析计算
- 使用Java代码实现实时消费kafka的消息
- storm实时消费kafka数据
- Spark kafka实时消费实现
- Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(程序案例篇)
- Storm+Kafka实时计算框架搭建
- 【实时计算架构系列1】WePay如何基于谷歌云平台(GCP)和kafka实现实时流式欺诈检测
- Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(案例测试篇)
- Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)
- Vertica实时消费kafka实现
- Storm实时计算编程入门:概念讲解及编程实现
- 【Twitter Storm系列】flume-ng+Kafka+Storm+HDFS 实时系统搭建
- [Bdata] Twitter Storm:开源实时流计算
- FW:分布式实时计算storm&nbsp;原理…
- FW:分布式实时计算storm&nbsp;原理…
- FW:分布式实时计算storm&nbsp;原理…
- 网页中实现一个计算当年还剩多少时间的倒数计时程序,要求网页上实时动态显示“××年还剩××天××时××分××秒”
- 实时流式计算框架Storm 0.9.0发布通知(中文版)
- 实时流式计算框架Storm 0.9.0发布通知(中文版)