Vertica实时消费kafka实现
2017-06-20 16:13
483 查看
一、 安装环境
Vertica官方提供了消费kafka的方法,需要注意版本对应

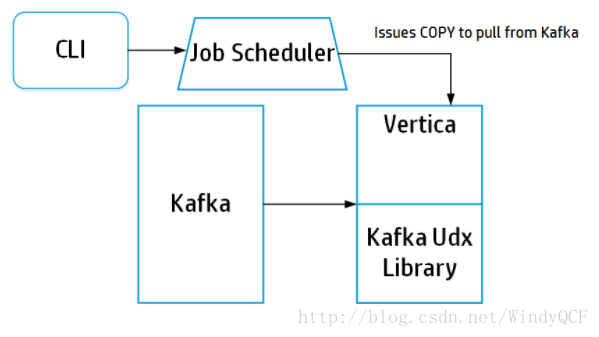
消费kafka原理,是Vertica提供的Udx
首先需要安装相应的环境
判断是否安装成功
二、 单次消费kafka
参考官方文档 Using COPY with Kafka
三、 实时消费kafka
参考官方文档Using Kafka with Vertica
1. 首先创建一个Scheduler
使用conf封装Vertica数据库登录信息
创建Scheduler脚本
创建kafka集群信息
读取topic
发布Scheduler
删除scheduler
删除topic接收
PS:
通过最新对Vertica消费kafka的使用,发现这个功能比较鸡肋。多个topic也只能放到一个scheduler里面执行消费,而且每次修改增加都需要停下所有topic的消费进程。另外在使用过程中也发现了丢失数据的现象。
Vertica官方提供了消费kafka的方法,需要注意版本对应
消费kafka原理,是Vertica提供的Udx
首先需要安装相应的环境
/${vertica}/packages/kafka/ddl/install.sql判断是否安装成功
/${vertica}/packages/kafka/ddl/isinstalled.sql二、 单次消费kafka
参考官方文档 Using COPY with Kafka
COPY schema.target_table SOURCE KafkaSource (stream='topic1|1|1,topic2|2|2', brokers='host1:9092, host2:9092',duration= INTERVAL'timeslice',stop_on_eof=TRUE, eof_timeout= INTERVAL'timeslice') PARSER KafkaJSONParser(flatten_arrays=False, flatten_maps=False) REJECTED DATA AS TABLE schema.rejection_table TRICKLE;
三、 实时消费kafka
参考官方文档Using Kafka with Vertica
1. 首先创建一个Scheduler
/opt/vertica/packages/kafka/bin/vkconfig scheduler --add --config-schema myScheduler --operator user1
使用conf封装Vertica数据库登录信息
kafka_config=”—cinfig-schema kafka01 –dbhoust 172.17.12.1 –username dbadmin –password pass1”
创建Scheduler脚本
/opt/vertica/packages/kafka/bin/vkconfig scheduler –add ${ kafka_config } –config-schema kafka_config --operator dbadmin创建kafka集群信息
BROKERS=”172.17.12.2:9099, 172.17.12.3:9099, 172.17.12.4:9099”
/opt/vertica/packages/kafka/bin/vkconfig kafka-cluster –add ${ kafka_config } --onfig-schema kafka_config --cluster KafkaCluster –brokers $ BROKERS读取topic
/opt/vertica/packages/kafka/bin/vkconfig topic –add ${ kafka_config } –target public.kafka_tgt –rejection-table public.kafka_rej –cluster KafkaCluster –topic web_pagelogs –number-partitions 1发布Scheduler
/opt/vertica/packages/kafka/bin/vkconfig launch ${ kafka_config } -- onfig-schema kafka_config –instance-name webpagelogs删除scheduler
/opt/vertica/packages/kafka/bin/vkconfig scheduler ${kafka_config} –remove –config-schema kafka_config删除topic接收
/opt/vertica/packages/kafka/bin/vkconfig topic ${kafka_config} –remove –target public.kafka_tgtPS:
通过最新对Vertica消费kafka的使用,发现这个功能比较鸡肋。多个topic也只能放到一个scheduler里面执行消费,而且每次修改增加都需要停下所有topic的消费进程。另外在使用过程中也发现了丢失数据的现象。

相关文章推荐
- Spark kafka实时消费实现
- storm消费kafka实现实时计算
- storm消费kafka实现实时计算
- 使用Java代码实现实时消费kafka的消息
- kafka0.8.2集群的环境搭建并实现基本的生产消费
- Spark Streaming消费Kafka Direct方式数据零丢失实现
- c语言使用librdkafka库实现kafka的生产和消费实例
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
- Spark Streaming消费Kafka Direct方式数据零丢失实现
- WebSocket和kafka实现数据实时推送到前端
- [bigdata] flume+kafka+storm实现实时分析计算
- 用redis实现消息队列(实时消费+ack机制)
- 利用Kafka, Cloudera Search以及Hue实现实时日志分析系统
- 【实时计算架构系列1】WePay如何基于谷歌云平台(GCP)和kafka实现实时流式欺诈检测
- Kafka offset存储方式与获取消费实现
- c++(11)使用librdkafka库实现kafka的消费实例
- Kafka实战:从RDBMS到Hadoop,七步实现实时传输
- flume实现kafka到hdfs实时数据采集 - 有负载均衡策略
- Kafka 在行动:7步实现从RDBMS到Hadoop的实时流传输
- kafka实现实时收集Spark Steaming任务日志