机器学习第二课:概率与统计的部分说明
2016-09-03 22:29
337 查看
由于本人加入系统学习机器学习课程,所以我从头整理知识点。这是总结课上的内容。内容主要来源于 大数据文摘
什么叫参数估计?就是你就知道一堆观测值,你要利用洪荒之力玄学思想选定一个模型。
然后你开始计算(估计)模型的参数吧。怎么估计我们可以用“矩估计”方法,“极大似然估计”方法。

我们一步一步分析。下面我们来以程小博士与二彪子(你)问答的方式来解决这个问题。
程小博士:事件X1,X2,X3,⋯是独立同分布。观测值为x1,x2,x3,⋯二彪子同学,x1的概率怎么表示?
你:
程小博士:如果改成条件概率,模型中的参数θ=θ1,那么在θ1条件下
你:p(x1|θ1)
程小博士:厉害。现在我发现一个问题:是在θ1条件下,x1,x2,x3,⋯全出现了。哎呀我不知道怎么表示?
你:既然是独立同分布的你就乘一下呗。你不就是要表示p(x1,x2,x3,⋯|θ1)吗?你不知道还有这样一个式子叫p(x1,x2,x3,⋯|θ1)=p(x1|θ1)p(x2|θ1)p(x3|θ1)...
程小博士:你越来越聪明了,这个东西就叫”似然函数”。
你:这东西有什么用?
程小博士:这个式子有欺骗性。你以为乘积是本体?你以为x观测数列是本体?都错了。似然函数的本体是模型的参数θ。
我们站在上帝视角看事件X1,X2,X3,⋯是独立同分布。万能的上帝肯定知道分布模型的参数θ是多少。但是我们不知道。
当站在人类视角,我们仅能看见x1,x2,x3,⋯这些数列。我们要想知道θ的精确值基本不可能。我们只能估计。
你:怎么估计这个模型的本体θ?
程小博士:我们发现一个问题,当参数θ的估计量θ1越契合于上帝手中的值时p(x1,x2,x3,⋯|θ1)值越大。
你:必须的。x序列如果足够大,分布肯定像上帝的模型。当你拿个不像上帝的模型去套他,肯定契合概率小。当你拿个像上帝的模型的东西去套他,契合概率肯定大。
程小博士:那么我们接下来求最大值不就行了吗?
你:最大值哪有这么好求!!!???
程小博士:其实这种简单函数,极大值就是最大值。
你:那又怎样?
程小博士:其实这种简单函数,导数等于0就行,二阶导都不用求。
你:。。。。。你们也太粗狂了,
程小博士:其实这种连乘的简单函数,可以用取对数方式乘法变加法,简便运算。
你:。。。。。。。。
后验概率=似然函数×先验概率/证据因子
这其实是贝叶斯公式。你看:
P(B|A)=P(A|B)∗P(B)P(A)P(θ1|x1,x2,x3,⋯)=P(x1,x2,x3,⋯|θ1)∗P(θ1)P(x1,x2,x3,⋅)
P(x1,x2,x3,⋯|θ1):上文说了就是似然函数
P(x1,x2,x3,⋯):这不就是我们仅仅知道的证据吗?
P(θ1):先验概率,但极大似然估计的例子中知道它比较难。
P(θ1|x1,x2,x3,⋯):β后验概率,知道结果了那么条件出现的概率是什么?
http://blog.csdn.net/dajiabudongdao/article/details/51893046
这个东西在《程序员的数学2》中有详细记载。大约花了好几章的进行前提铺垫。
如果随机变量 X 服从参数为 n 和 p 的二项分布,那么它的概率由概率质量函数(对于连续随机变量,则为概率密度函数)为:
p(x)=Cxnqx(1−q)n−x(1)
下面把离散函数连续化。把它表示为变量 q 的函数,即只有 q 这一个变量,这样Cxn就是个常数,可以写成如下相关形式:
f(q)∝qa(1−q)b(2)
其中 a 和 b 是常量。接下来就是概率密度基本规划为1的过程。
为了把上公式变成一个分布,可以给它乘上一个因子,使它对 q 从0到1积分为1即可。(这个因子通常是 a 和 b 的函数,而不是 q 。如果是q不就不能算。)
B(a+1,b+1)=∫10qa(1−q)bdq(3)
有人这样规范化后的就是一个分布了(事实上我也不知道)
f(q;a+1,b+1)=qa(1−q)b∫10qa(1−q)bdq=qa(1−q)bB(a+1,b+1)(4)
取 α=a+1, β=b+1 ,并将积分变量 q 改为 t得Beta函数(因为其他地方也会用到故用红色表示):
B(α,β)=∫10tα−1(1−t)β−1dt
变量 q 改为 x ,得Beta分布:
f(x;α,β)=xα−1(1−x)β−1∫10xα−1(1−x)β−1dx=xα−1(1−x)β−1∫10uα−1(1−u)β−1du=xα−1(1−x)β−1B(α,β)
下图为 Beta 分布的概率密度函数(PDF)和累积密度函数(CDF)(图片来自Wiki):

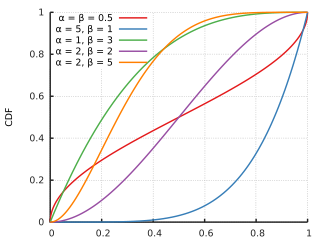
这么说Beta函数与二项分布共轭也没什么不对
什么叫参数估计?就是你就知道一堆观测值,你要利用洪荒之力玄学思想选定一个模型。
然后你开始计算(估计)模型的参数吧。怎么估计我们可以用“矩估计”方法,“极大似然估计”方法。
一、极大似然估计方法的理解
极大似然估计的理解
老师在课上其实是这么说的我们一步一步分析。下面我们来以程小博士与二彪子(你)问答的方式来解决这个问题。
程小博士:事件X1,X2,X3,⋯是独立同分布。观测值为x1,x2,x3,⋯二彪子同学,x1的概率怎么表示?
你:
$p(x_1)$
程小博士:如果改成条件概率,模型中的参数θ=θ1,那么在θ1条件下
$x_1$的概率怎么表示?
你:p(x1|θ1)
程小博士:厉害。现在我发现一个问题:是在θ1条件下,x1,x2,x3,⋯全出现了。哎呀我不知道怎么表示?
你:既然是独立同分布的你就乘一下呗。你不就是要表示p(x1,x2,x3,⋯|θ1)吗?你不知道还有这样一个式子叫p(x1,x2,x3,⋯|θ1)=p(x1|θ1)p(x2|θ1)p(x3|θ1)...
程小博士:你越来越聪明了,这个东西就叫”似然函数”。
你:这东西有什么用?
程小博士:这个式子有欺骗性。你以为乘积是本体?你以为x观测数列是本体?都错了。似然函数的本体是模型的参数θ。
我们站在上帝视角看事件X1,X2,X3,⋯是独立同分布。万能的上帝肯定知道分布模型的参数θ是多少。但是我们不知道。
当站在人类视角,我们仅能看见x1,x2,x3,⋯这些数列。我们要想知道θ的精确值基本不可能。我们只能估计。
你:怎么估计这个模型的本体θ?
程小博士:我们发现一个问题,当参数θ的估计量θ1越契合于上帝手中的值时p(x1,x2,x3,⋯|θ1)值越大。
你:必须的。x序列如果足够大,分布肯定像上帝的模型。当你拿个不像上帝的模型去套他,肯定契合概率小。当你拿个像上帝的模型的东西去套他,契合概率肯定大。
程小博士:那么我们接下来求最大值不就行了吗?
你:最大值哪有这么好求!!!???
程小博士:其实这种简单函数,极大值就是最大值。
你:那又怎样?
程小博士:其实这种简单函数,导数等于0就行,二阶导都不用求。
你:。。。。。你们也太粗狂了,
程小博士:其实这种连乘的简单函数,可以用取对数方式乘法变加法,简便运算。
你:。。。。。。。。
先验,后验,似然函数,证据因子的关系
这个问题来自一个同学提出的式子:后验概率=似然函数×先验概率/证据因子
这其实是贝叶斯公式。你看:
P(B|A)=P(A|B)∗P(B)P(A)P(θ1|x1,x2,x3,⋯)=P(x1,x2,x3,⋯|θ1)∗P(θ1)P(x1,x2,x3,⋅)
P(x1,x2,x3,⋯|θ1):上文说了就是似然函数
P(x1,x2,x3,⋯):这不就是我们仅仅知道的证据吗?
P(θ1):先验概率,但极大似然估计的例子中知道它比较难。
P(θ1|x1,x2,x3,⋯):β后验概率,知道结果了那么条件出现的概率是什么?
二、多元高斯分布
这里发个广告,这里记载关于我混合高斯模型(GMM)的详细记录http://blog.csdn.net/dajiabudongdao/article/details/51893046
这个东西在《程序员的数学2》中有详细记载。大约花了好几章的进行前提铺垫。
三、Beta函数与二项分布
课上就说了一下,但是我肯定不满足仅说一点点。本篇文章大部分来自这个CSDN的blog潇水汀寒这是个离散分布连续化的故事。 为了解释为什么:Beta函数与二项分布共轭????
如果随机变量 X 服从参数为 n 和 p 的二项分布,那么它的概率由概率质量函数(对于连续随机变量,则为概率密度函数)为:
p(x)=Cxnqx(1−q)n−x(1)
下面把离散函数连续化。把它表示为变量 q 的函数,即只有 q 这一个变量,这样Cxn就是个常数,可以写成如下相关形式:
f(q)∝qa(1−q)b(2)
其中 a 和 b 是常量。接下来就是概率密度基本规划为1的过程。
为了把上公式变成一个分布,可以给它乘上一个因子,使它对 q 从0到1积分为1即可。(这个因子通常是 a 和 b 的函数,而不是 q 。如果是q不就不能算。)
B(a+1,b+1)=∫10qa(1−q)bdq(3)
有人这样规范化后的就是一个分布了(事实上我也不知道)
f(q;a+1,b+1)=qa(1−q)b∫10qa(1−q)bdq=qa(1−q)bB(a+1,b+1)(4)
取 α=a+1, β=b+1 ,并将积分变量 q 改为 t得Beta函数(因为其他地方也会用到故用红色表示):
B(α,β)=∫10tα−1(1−t)β−1dt
变量 q 改为 x ,得Beta分布:
f(x;α,β)=xα−1(1−x)β−1∫10xα−1(1−x)β−1dx=xα−1(1−x)β−1∫10uα−1(1−u)β−1du=xα−1(1−x)β−1B(α,β)
下图为 Beta 分布的概率密度函数(PDF)和累积密度函数(CDF)(图片来自Wiki):
这么说Beta函数与二项分布共轭也没什么不对

相关文章推荐
- [(机器学习)概率统计]极大似然估计MLE原理+python实现
- 机器学习之数学基础(概率与统计推断、矩阵、凸优化)
- 概率统计与机器学习:机器学习常见名词解释(过拟合,偏差方差)
- 【机器学习系列之四】概率统计学习基础
- 第二部分 任务说明
- 概率与统计推断第二讲homework
- 基于统计概率和机器学习的文本分类技术
- 机器学习、大数据、深度学习、数据挖掘、统计、决策和风险分析、概率和模糊逻辑的常见问题解答
- 概率统计与机器学习:极大后验概率以及正则化项
- 机器学习笔记--概率与数理统计
- Apache Client使用说明第一章(第二部分)
- Atitit 算法之道 attilax著 1. 第二部分(Part II) 排序与顺序统计(Sorting and Order Statistics) 1 2. 第六章 堆排序(Heapsort)
- 认知的概率模型(ESSLLI教程) - 第二部分译文 - 条件
- Spring说明文档翻译2——第二部分 Spring3.0新特性
- oracle学习笔记 oracle软件安装准备工作 第二部分 安装前说明
- 机器学习之概率与统计(三)- 极大似然估计
- 机器学习、大数据、深度学习、数据挖掘、统计、决策和风险分析、概率和模糊逻辑的常见问题解答
- 概率统计与机器学习:独立同分布,极大似然估计,线性最小二乘回归
- 使用机器学习预测天气(第二部分)
- 第16周项目1——字符统计任务(第二部分)