程序员的机器学习入门笔记(三):数据挖掘中矩阵的那些事
2016-08-24 10:54
519 查看
前面两篇文章对机器学习中的一些概念,以及开发环境的搭建做了简单的介绍。本文主要用来总结关于矩阵的一些知识。
“矩阵”这个词听起来充满了数学色彩,一看到这个词,一大堆的数据公式,符号,等等已经在我脑海中进行闪现,可是等我硬着头皮把相关的知识点看完后,觉得也就没有那么难了,毕竟我们知识搬运工,所以对它也不需要研究的那么深入,只需要知道一些基础知识就可以了。
定义
数学系的定义:“由 m×n 个数组成的一个 m 行 n 列的矩形表格“
程序员的定义:"具有相同属性的对象的集合"
综合定义:
矩阵为具有相同特征和特征数量的对象集合,表现为一张二维数据表
一个对象表示为矩阵中的一行,一个特征表示为矩阵中的一列,每个特
征都有数值型的取值,而不能是某些文字描述
特征相同、取值相异的对象集合所构成的矩阵,使对象之间既相互独立,
又相互联系;
在机器学习中的作用
通过解线性方程组,达到聚类、分类或预测的目的
聚类,分类
为了说明矩阵是怎么在聚类,分类的计算中起到作用的,用一个书上的例子来表达.
下表中列出了几种生物的体重以及生命周期/保质期,从重量和生命周期两个特征中,苹果和梨具有相似性,大象和鲨鱼具有相似性。从表格的数字上可以很直观的看出,大象与鲨鱼的重量较之苹果(或梨)的重量更相似;或者大象与鲨鱼的寿命较之苹果(或梨)的保质期更相似;由于这种相似性,我们很自然地可以将苹果和梨分为一类:水果(区别于植物);大象和鲨鱼分为一类:大型动物。
如果使用重量以及生命周期作为坐标描绘在二维的平面坐标系上的话,也可以比较明显的看出4个物种的关系,向量在这方面的作用也就是通过将对象集转变为一个平面直角坐标系内的点集,通过计算点与点之间的距离,完成聚类、分类,类似的运算完全可以扩展到多维的情况。
预测
为了说明矩阵是如何作用在预测方面的,同样通过一个例子来说明,下面的图是男生身高对照表:
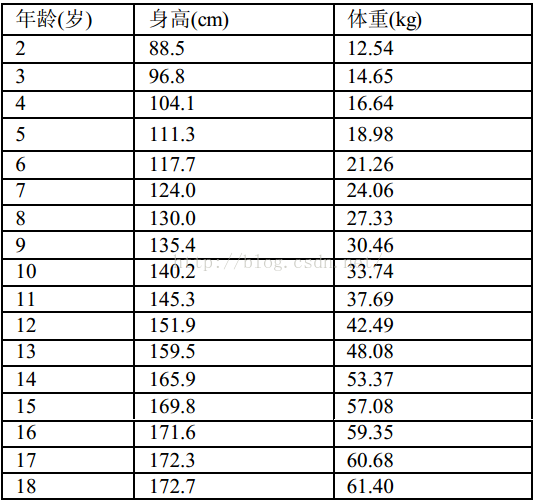
这个表列举了 2~18 岁男生的正常体重、身高的变化。数值上呈现一种递增的趋势,每个对象都与上一行或下一行的对象在时间上相关,并且时间间隔相等,都为 1 年。这种时间上的相关性使矩阵反映出某一事物在时间上连续变化的过程。
由此可见,预测或回归可以看作根据对象在某种序列(时间)上的相关性,表现为特
征取值变化的一种趋势。
总结:分类、聚类和回归是机器学习最基本的主题。通过矩阵,可以构建客观事物的多维度数学模型,并通过条件概率分布、梯度、神经网络、协方差等等运算方式,多角度认识和分析事物。
方程降次,也就是利用矩阵的二次型,通过升维将线性不可分的数据集映射到高维中,转换为线性可分的情形,这是支持向量机的基本原理之一
矩阵可以通过特征值和特征向量,完成维度约简,简化类似图片这种高维数据集的运算,主成分分析使用的就是这个原理。
程序员怎么用
如果你是一名Python的程序员,那么你很幸运,有个叫Numpy的库已经帮你把矩阵的操作全部封装好了,你只需要调用即可,如果你是一名Java的程序员,则可以使用Apache Commons Math library,或是使用成熟的机器学习的库,具体请参见:http://www.csdn.net/article/2015-12-25/2826560
常见基本运算
在程序设计中,我们可以从形式上把矩阵理解为一个二维数组。以 Python 语言为例,矩阵就是嵌套着若干个 list 的一个大 list。内部的每个 list 都是等长的,其中每个元素都是整型或浮点型的数值。内部的 list 就是行向量,即一个对象。
本人是有着Java经验的Python程序员,本着简单的原则,学习机器学习的过程中果断的选择的Python作为主要的使用语言,下面就以Numpy为例,通过一长段代码介绍一些常用的矩阵运算。
“矩阵”这个词听起来充满了数学色彩,一看到这个词,一大堆的数据公式,符号,等等已经在我脑海中进行闪现,可是等我硬着头皮把相关的知识点看完后,觉得也就没有那么难了,毕竟我们知识搬运工,所以对它也不需要研究的那么深入,只需要知道一些基础知识就可以了。
定义
数学系的定义:“由 m×n 个数组成的一个 m 行 n 列的矩形表格“
程序员的定义:"具有相同属性的对象的集合"
综合定义:
矩阵为具有相同特征和特征数量的对象集合,表现为一张二维数据表
一个对象表示为矩阵中的一行,一个特征表示为矩阵中的一列,每个特
征都有数值型的取值,而不能是某些文字描述
特征相同、取值相异的对象集合所构成的矩阵,使对象之间既相互独立,
又相互联系;
在机器学习中的作用
通过解线性方程组,达到聚类、分类或预测的目的
聚类,分类
为了说明矩阵是怎么在聚类,分类的计算中起到作用的,用一个书上的例子来表达.
下表中列出了几种生物的体重以及生命周期/保质期,从重量和生命周期两个特征中,苹果和梨具有相似性,大象和鲨鱼具有相似性。从表格的数字上可以很直观的看出,大象与鲨鱼的重量较之苹果(或梨)的重量更相似;或者大象与鲨鱼的寿命较之苹果(或梨)的保质期更相似;由于这种相似性,我们很自然地可以将苹果和梨分为一类:水果(区别于植物);大象和鲨鱼分为一类:大型动物。
| 名称 | 重量(KG) | 生命周期/保质期 |
| 大象 | 5000 | 70*365 |
| 鲨鱼 | 4800 | 68*365 |
| 苹果 | 0.2 | 10 |
| 梨 | 0.3 | 7 |
预测
为了说明矩阵是如何作用在预测方面的,同样通过一个例子来说明,下面的图是男生身高对照表:
这个表列举了 2~18 岁男生的正常体重、身高的变化。数值上呈现一种递增的趋势,每个对象都与上一行或下一行的对象在时间上相关,并且时间间隔相等,都为 1 年。这种时间上的相关性使矩阵反映出某一事物在时间上连续变化的过程。
由此可见,预测或回归可以看作根据对象在某种序列(时间)上的相关性,表现为特
征取值变化的一种趋势。
总结:分类、聚类和回归是机器学习最基本的主题。通过矩阵,可以构建客观事物的多维度数学模型,并通过条件概率分布、梯度、神经网络、协方差等等运算方式,多角度认识和分析事物。
方程降次,也就是利用矩阵的二次型,通过升维将线性不可分的数据集映射到高维中,转换为线性可分的情形,这是支持向量机的基本原理之一
矩阵可以通过特征值和特征向量,完成维度约简,简化类似图片这种高维数据集的运算,主成分分析使用的就是这个原理。
程序员怎么用
如果你是一名Python的程序员,那么你很幸运,有个叫Numpy的库已经帮你把矩阵的操作全部封装好了,你只需要调用即可,如果你是一名Java的程序员,则可以使用Apache Commons Math library,或是使用成熟的机器学习的库,具体请参见:http://www.csdn.net/article/2015-12-25/2826560
常见基本运算
在程序设计中,我们可以从形式上把矩阵理解为一个二维数组。以 Python 语言为例,矩阵就是嵌套着若干个 list 的一个大 list。内部的每个 list 都是等长的,其中每个元素都是整型或浮点型的数值。内部的 list 就是行向量,即一个对象。
本人是有着Java经验的Python程序员,本着简单的原则,学习机器学习的过程中果断的选择的Python作为主要的使用语言,下面就以Numpy为例,通过一长段代码介绍一些常用的矩阵运算。
# -*- coding: utf-8 -*- __author__ = 'eric.sun' import numpy as np #初始化matrix def init_matrix(): zeros=np.zeros([3,5]) ones=np.ones([3,3]) print ones print zeros #生成固定维度的matrix def gen_random_matrix(): rand_matrix=np.random.rand(3,4) print rand_matrix #生成单位矩阵 def gen_unit_matrix(): unit_matrix=np.eye(5) print unit_matrix matrix_add=lambda m_a,m_b:m_a+m_b matrix_sub=lambda m_a,m_b:m_a-m_b #矩阵的相加,相减,维度必须相同 def matrix_add_sub(): matrix1=np.ones([3,3]) matrix2=np.eye(3) print matrix_add(matrix1,matrix2) print matrix_sub(matrix1,matrix2) #一个整数乘以一个矩阵 def multi_matrix(): matrix=np.eye(3) print 3*matrix #矩阵和矩阵的相乘 def multi_matrix2(): ori=[[ 3,4,2,4],[ 0,3,1,2],[ 2,6,4,3],[ 2,6,4,1]] ori2=[[ 1,4,3,1],[ 2,1,1,2],[ 1,2,4,3],[ 2,6,4,5]] ori3=2*[[ 4,3,2,3],[ 2,1,1,1]] #相同维度的相乘,相同坐标元素的相乘 print np.multiply(ori,ori2) print '\n' #不同维度的相乘,相同坐标元素的相乘 print np.multiply(np.mat(ori),ori3) print '\n' # print np.mat(ori)*np.mat(ori3) def others(): ori=[[ 3,4,2,4],[ 0,3,1,2],[ 2,6,4,3],[ 2,6,4,1]] matrix=np.mat(ori) [m,n]=np.shape(matrix) #得到矩阵的行列数 print m,n #行切片 print matrix[0] #列切片 print matrix.T[0] #matrix的sum操作 def matrix_sum(): ori=[[ 3,4,2],[ 0,3,1],[ 2,6,4]] print ori matrix=np.mat(ori) print matrix print np.sum(matrix) #matrix的次方 def power_matrix(): ori=[[ 3,4,2],[ 0,3,1],[ 2,6,4]] print np.power(np.mat(ori),10) if __name__ == '__main__': # init_matrix() # gen_random_matrix() # gen_unit_matrix() # matrix_add_sub() # multi_matrix() matrix_sum() # multi_matrix2() # power_matrix() # others()

相关文章推荐
- 机器学习入门的书单(数据挖掘、模式识别等一样)
- 笔记 加州理工学院公开课:机器学习与数据挖掘 一
- 程序员的机器学习入门笔记(十一):简单人脸识别系统实践
- 机器学习笔记6:TensorFlow入门之MNIST数据集训练
- Weka中数据挖掘与机器学习系列之为什么要写Weka这一系列学习笔记?(一)
- 机器学习入门的书单(数据挖掘、模式识别等一样)
- 程序员的机器学习入门笔记(六):决策树的入门介绍
- 《python数据挖掘入门与实践》笔记1
- 程序员的机器学习入门笔记(八):最优化与计算复杂度概述
- 数据分析、数据挖掘、机器学习、神经网络、深度学习和人工智能概念区别(入门级别)
- 机器学习入门的书单(数据挖掘、模式识别等一样)
- 面向程序员的数据挖掘指南-----第二章:推荐系统入门
- 程序员的机器学习入门笔记(二):Python常用库的介绍,及安装(Centos 6.5)
- 《python数据挖掘入门与实践》笔记2
- 机器学习入门的书单(数据挖掘、模式识别等一样)转
- 数据挖掘入门笔记(一)--认识数据
- 数据挖掘学习笔记-入门基础篇
- 程序员的机器学习入门笔记(零):博客说明
- 机器学习与数据挖掘入门指导
- 《python数据挖掘入门与实践》“电影推荐” 笔记3