LCA(最近公共祖先)离线算法之tarjan
2016-08-13 23:35
197 查看
初步学习了一下用tarjan算法求最近公共祖先(LCA),下面是敝人的拙见:
tarjan是一个离线算法,所谓离线算法就是在所有询问均存储完之后再做操作。而tarjan算法对这些询问并不一定按存储时的顺序去操作,这就是tarjan算法的时间复杂度能达到O(n+q)的关键所在(q为询问的数量),至于是按什么顺序,待读者看完文章自然会明白。
首先我们来看到tarjan算法的原理:
既然要求LCA,自然是树形结构。首先讲一下,tarjan算法是基于DFS和并查集的,DFS用于查找待求节点的LCA,并查集用于存储结点间的父子关系。现在我们来看一棵树:
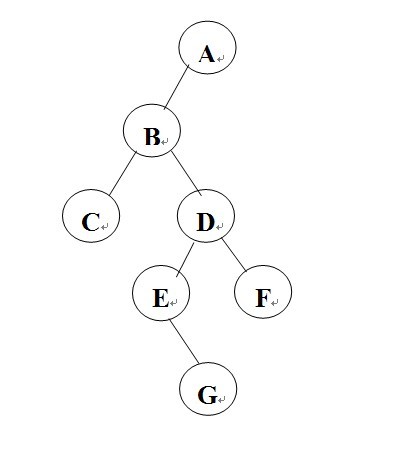
对于这颗树,假设现在我们要求结点 E 和结点 F 的LCA,显然是 D 。那么为什么 D 会是 E 和 F 的LCA呢?我们来思考一下,把 D 看作根节点作为一颗单独的树,E和F都是D结点的后代,所以D自然史E、F的最近公共祖先。可为什么不是B呢?E、F也是B的后代啊,当然是因为D最近啦。所以现在我们的任务就是找到一颗树(大树小树不管什么树都行),事得待求的两个节点同时存在于该树下。至于如何找,前面讲到tarjan算法是基于DFS的。我们现在来模拟一下DFS找LCA的过程,首先从根节点A开始,向下深搜;搜到B,则此时可把B当作一棵树(本来也是一棵树)向下深搜,这里需要记录的是我们当前是在B这颗树下搜索。知道搜索到D的时候,在以D为基础向下搜索的时候我们同时搜索到了待求点E、F,那么所求的LCA就是D了。DFS部分就到这了,下面是并查集部分。我们每搜到一棵树,都将其的祖先修改为本身,也就是自成一派。而在将这棵树的所有子树全都搜索完之后,如果找到了待求点,则此时记录的最近祖先就是该子树树根。随后再将其祖先修改为原本逻辑上的父亲,以此递归搜索。如果赤裸裸的文字难以理解的话,也可能是我描述不清,下面上赤裸裸的代码,跟着代码的思路自己写一遍的话很快就能学会了。
到此,基本的tarjan 思路就已经理清,也可能博主语言表达能力有限并没有阐述清楚,还望批评指正。在学习算法的过程中,如果单纯的看文字描述无法理解的话,其实可以先找一道裸题自己敲一敲,即使是对着题解或者模板敲也是有用的。这里提供一道裸题:codevs1036
tarjan是一个离线算法,所谓离线算法就是在所有询问均存储完之后再做操作。而tarjan算法对这些询问并不一定按存储时的顺序去操作,这就是tarjan算法的时间复杂度能达到O(n+q)的关键所在(q为询问的数量),至于是按什么顺序,待读者看完文章自然会明白。
首先我们来看到tarjan算法的原理:
既然要求LCA,自然是树形结构。首先讲一下,tarjan算法是基于DFS和并查集的,DFS用于查找待求节点的LCA,并查集用于存储结点间的父子关系。现在我们来看一棵树:
对于这颗树,假设现在我们要求结点 E 和结点 F 的LCA,显然是 D 。那么为什么 D 会是 E 和 F 的LCA呢?我们来思考一下,把 D 看作根节点作为一颗单独的树,E和F都是D结点的后代,所以D自然史E、F的最近公共祖先。可为什么不是B呢?E、F也是B的后代啊,当然是因为D最近啦。所以现在我们的任务就是找到一颗树(大树小树不管什么树都行),事得待求的两个节点同时存在于该树下。至于如何找,前面讲到tarjan算法是基于DFS的。我们现在来模拟一下DFS找LCA的过程,首先从根节点A开始,向下深搜;搜到B,则此时可把B当作一棵树(本来也是一棵树)向下深搜,这里需要记录的是我们当前是在B这颗树下搜索。知道搜索到D的时候,在以D为基础向下搜索的时候我们同时搜索到了待求点E、F,那么所求的LCA就是D了。DFS部分就到这了,下面是并查集部分。我们每搜到一棵树,都将其的祖先修改为本身,也就是自成一派。而在将这棵树的所有子树全都搜索完之后,如果找到了待求点,则此时记录的最近祖先就是该子树树根。随后再将其祖先修改为原本逻辑上的父亲,以此递归搜索。如果赤裸裸的文字难以理解的话,也可能是我描述不清,下面上赤裸裸的代码,跟着代码的思路自己写一遍的话很快就能学会了。
void tarjan(int x) {//x为当前搜到的结点
fa[x]=x;//将x的祖先修改为其本身
vis[x]=1;//标记x为已被搜索
int num=que[x].size();
/*这里que是一个vector数组,存储的是询问
出现在这里是要判断是否有关于x,即当前搜到的结点的寻问
*/
for(int i=0; i<num; i++) {//如果有关于x的询问,则找到与其对应的另一个节点
int y=que[x][i];
if(vis[y]) {//判断如果另一个节点也已访问过,则说明此时它们处于同一子树下可以求出它们的LCA
int lca=find(y);
/*这里需要注意的是,由于y在x之前已经被访问过了,
所以y的祖先就是它们的LCA,因为在搜索y这颗树时,
而如果是在搜索y这颗树的时候索搜到了x
则说明x是在y这颗树下,此时find(y)就是y,也是他们的LCA
而如果在搜索完y这棵树后并没有索搜到x,
则会将y的祖先修改为其原本逻辑上的父亲,
再继续做y的父亲这棵树的搜索(这是DFS的特点,不多描述),
如果在做y的父亲这棵树的搜索时搜索到了x,
则此时返回的find(x)也是他们的LCA,
而如果在搜索y的父亲的时候还是没有搜索到x,
下面自己推吧。
*/
LCA[x][y]=LCA[y][x]=lca;
//这里存储x、y的LCA,如果需要其他应用,也可以在这里操作
}
}
int size=son[x].size();
//son也是一个vector数组,存储x逻辑上的后代,即存储树形结构
for(int i=0; i<size; i++) {
int y=son[x][i];
tarjan(y);//这里递归搜索x的后代,类似深搜
fa[y]=x;//再将y搜索完以后把y的父亲修改为x
}
}到此,基本的tarjan 思路就已经理清,也可能博主语言表达能力有限并没有阐述清楚,还望批评指正。在学习算法的过程中,如果单纯的看文字描述无法理解的话,其实可以先找一道裸题自己敲一敲,即使是对着题解或者模板敲也是有用的。这里提供一道裸题:codevs1036

相关文章推荐
- [图论] LCA(最近公共祖先)Tarjan 离线算法
- LCA最近公共祖先的离线算法(Tarjan)和在线算法(ST)
- [笔记]LCA 最近公共祖先---tarjan离线算法
- Tarjan离线算法求最近公共祖先(LCA)
- POJ1470Closest Common Ancestors 最近公共祖先LCA 的 离线算法 Tarjan
- LCA(最近公共祖先)离线算法Tarjan+并查集
- POJ 1470 Closest Common Ancestors (最近公共祖先LCA 的离线算法Tarjan)
- POJ1986 DistanceQueries 最近公共祖先LCA 离线算法Tarjan
- tarjan离线算法-LCA最近公共祖先算法模板(详细)
- LCA(最近公共祖先)离线算法Tarjan
- 树上两点的最近公共祖先-Tarjan_LCA离线算法
- 树上两点的最近公共祖先-Tarjan_LCA离线算法
- hihocoder 1067 最近公共祖先·二(tarjan LCA 离线算法O(n))
- LCA最近公共祖先问题(Tarjan离线算法)
- LCA最近公共祖先(tarjan离线算法)
- 最近公共祖先LCA Tarjan 离线算法
- POJ1986 DistanceQueries 最近公共祖先LCA 离线算法Tarjan
- LCA最近公共祖先 Tarjan离线算法
- Tarjan离线算法求最近公共祖先(LCA)
- POJ1470Closest Common Ancestors 最近公共祖先LCA 的 离线算法 Tarjan