论文笔记《Rich Feature Hierarchies for accurate object detection and semantic segmentation》
2016-06-12 22:16
776 查看
RCNN是CNN应用在object detection的开山之作,加上后续的Fast-RCNN,Faster-RCNN都是非常经典的工作,这三篇文章一环套一环的改进思路简直是快准狠(跪拜rbg大牛><)。笔者不是做检测的(所以没有折腾过代码不清楚实验细节),在paper reading听了别人报告之后很喜欢RCNN系列文章,就记录下对原理的理解和感悟吧。
代码
这里finetune CNN时,用和groud truth的IoU overlap>0.5的proposal作为该类的正例样本,其余的都是反例样本,而因为正例太少,所以实验中固定正反例样本比例为1:3
训练SVM时,用ground truth作为正例样本,和ground truth的IoU overlap<0.3的作为反例样本
用proposal 的的pool5特征Φ5(Pi)学习一个w∗=argminw∗∑Ni(ti∗−wT∗Φ5(Pi))2+λ||w∗||2, 其中P1是4维向量,代表第i个proposal的左上角点坐标(x,y)和proposal的(width, height).
根据w计算一个对于位置的变换d∗(P)=wT∗Φ5(P), 其中d就是代表proposal和对应的ground truth之间的变换。
较复杂的pipeline
对一张图的proposal分别提取CNN,因为大量proposal互相重复导致对图片的区域进行多次计算。
warp使region失真
后续的Fast、Faster RCNN也都主要是根据以上几点改进模型。
1 论文信息
发表会议:CVPR2014代码
2 Motivation
就像论文开头所说,“Features matter”,描述力强的特征对目标检测任务来说十分有必要,考虑将CNN强大的表示能力用于目标检测中,就是考虑“fill the gap between image classification and object detection”,而对于一个目标来说,要判断它是哪个目标,实质上是一个分类问题。3 Method
3.1 简介
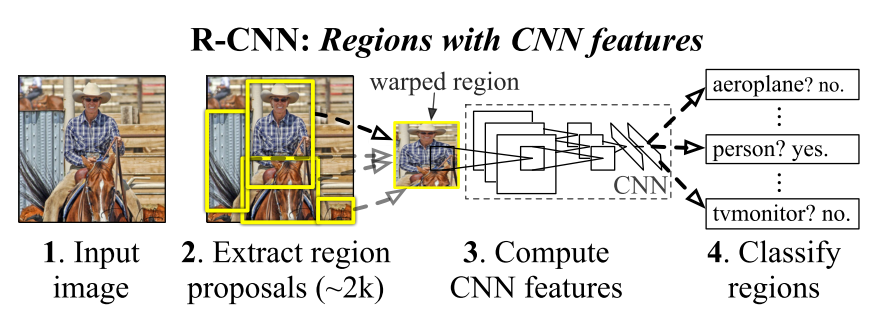
RCNN是pipeline approach,主要流程是,获取proposal(selective search)–> 提特征(CNN)–> 得到每个proposal的得分(SVM)–> 目标定位(bounding box regression),如下图:3.2 细节记录
3.2.1 selective search
这一步得到2k左右个proposal。3.2.2 Extract CNN features
上一步的proposal直接忽视长宽比,把warped region输入CNN网络这里finetune CNN时,用和groud truth的IoU overlap>0.5的proposal作为该类的正例样本,其余的都是反例样本,而因为正例太少,所以实验中固定正反例样本比例为1:3
3.2.3 Compute score
为每个类训练SVM,这样每个框都会得到对应于每个类的score训练SVM时,用ground truth作为正例样本,和ground truth的IoU overlap<0.3的作为反例样本
3.2.4 bounding box regression
取和ground truth的IoU overlap>0.6的proposal用于训练回归模型用proposal 的的pool5特征Φ5(Pi)学习一个w∗=argminw∗∑Ni(ti∗−wT∗Φ5(Pi))2+λ||w∗||2, 其中P1是4维向量,代表第i个proposal的左上角点坐标(x,y)和proposal的(width, height).
根据w计算一个对于位置的变换d∗(P)=wT∗Φ5(P), 其中d就是代表proposal和对应的ground truth之间的变换。
4 Experiment
本文中实验占了较大篇幅,对于细节问题的探讨也很值得学习。4.1 怎么warp
即如何把大小不一的region proposal统一到CNN要求的输入大小,作者尝试多种方案后决定直接忽略长宽比做resize。4.2 正反例的定义
可以看到在finetune CNN时和训练SVM时,对于正反例的定义是不一样的,作者应该做了大量实验去找overlap的合适取值。相对而言对SVM的正反例定义要严格些,因为它得出的score要拿出来分类,而CNN只是提特征,且CNN训练需要较多的数据。4.3 softmax还是SVM
CNN本身就是分类网络,其中softmax分类器的输出可以作为proposal的score,一方面是实验结果显示用SVM效果好,另一方面,由于finetune CNN用的正反例不是真实的正反例,只是一种近似。4.4 CNN为什么rich
在论文的Fig6中,对比了CNN对于多种object特性(截断,视角,长宽比等)的敏感度(越不敏感说明泛化能力越好)。5 Summary
CNN这种rich feature确实提升了目标检测的性能,当前RCNN的需要改进的地方有:较复杂的pipeline
对一张图的proposal分别提取CNN,因为大量proposal互相重复导致对图片的区域进行多次计算。
warp使region失真
后续的Fast、Faster RCNN也都主要是根据以上几点改进模型。

相关文章推荐
- 100 个最佳 Ubuntu 应用(中)
- 在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用
- 24 个必备的 Linux 应用程序
- 注册表趣味应用小集
- 远程控制技术的应用
- 路由器访问列表的应用
- xDSL技术及其应用
- 基于XML的桌面应用
- SQL Server 2008 R2 应用及多服务器管理
- Node.js 应用跑得更快 10 个技巧
- ExtJS 2.0实用简明教程之应用ExtJS
- 全面解析Ajax综合应用(全)
- JSP应用的安全问题
- 前端开发必须知道的JS之闭包及应用
- Android编程实现应用自动更新、下载、安装的方法
- Geohash的原理、算法和具体应用探究
- PHP开发中AJAX技术的简单应用
- PHP答题类应用接口实例
- ASP.NET过滤器的应用方法介绍
- Android编程实现将应用强制安装到手机内存的方法