Spark Transformation —— mapPartitions
2016-07-22 20:41
260 查看
原理
def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]
该函数和map函数类似,只不过映射函数的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器。如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的过。
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
参数preservesPartitioning表示是否保留父RDD的partitioner分区信息。
var rdd1 = sc.makeRDD(1 to 5,2)
//rdd1有两个分区
scala> var rdd3 = rdd1.mapPartitions{ x => {
| var result = List[Int]()
| var i = 0
| while(x.hasNext){
| i += x.next()
| }
| result.::(i).iterator
| }}
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[84] at mapPartitions at :23
//rdd3将rdd1中每个分区中的数值累加
scala> rdd3.collect
res65: Array[Int] = Array(3, 12)//1+2 = 3,3+4+5 =12 函数对每个分区的迭代器使用
scala> rdd3.partitions.size
res66: Int = 2原理图
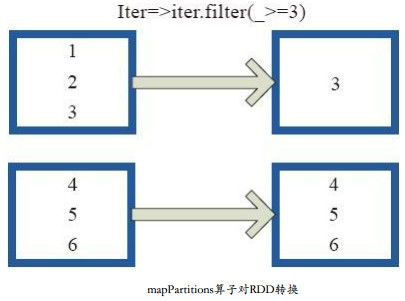
mapPartitions函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭代器对整个分区的元素进行操作。 内部实现是生成MapPartitionsRDD。
图中,用户通过函数f(iter) => iter.filter(_>=3)对分区中的所有数据进行过滤,>=3的数据保留。一个方块代表一个RDD分区,含有1、 2、 3的分区过滤只剩下元素3。
源码实现
/**
* Return a new RDD by applying a function to each partition of this RDD.
*
* `preservesPartitioning` indicates whether the input function preserves the partitioner, which
* should be `false` unless this is a pair RDD and the input function doesn't modify the keys.
*/
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] = {
val func = (context: TaskContext, index: Int, iter: Iterator[T]) => f(iter)
new MapPartitionsRDD(this, sc.clean(func), preservesPartitioning)
}S

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- ClassNotFoundException:scala.PreDef$
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- 使用java代码提交Spark的hive sql任务,run as java application
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- Spark机器学习(二) 局部向量 Local-- Data Types - MLlib
- Spark机器学习(三) Labeled point-- Data Types
- Spark初探
- Spark Streaming初探
- Spark本地开发环境搭建
- 搭建hadoop/spark集群环境
- Spark HA部署方案
- Spark HA原理架构图
- spark内存概述