Spark应用(app jar)发布到Hadoop集群的过程
2016-07-19 16:13
411 查看
记录了Spark,Hadoop集群的开启,关闭,以及Spark应用提交到Hadoop集群的过程,通过web端监控运行状态。
我的集群安装位置是/opt/hadoop下,可以根据自己路径修改。
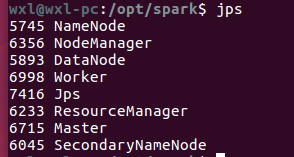
使用jps命令查看集群是否全部正确开启
注意spark-examples-1.6.2-hadoop2.6.0.jar,需要根据你的版本来看自带的版本号。
/opt/spark/logs/
http://localhost:8080/
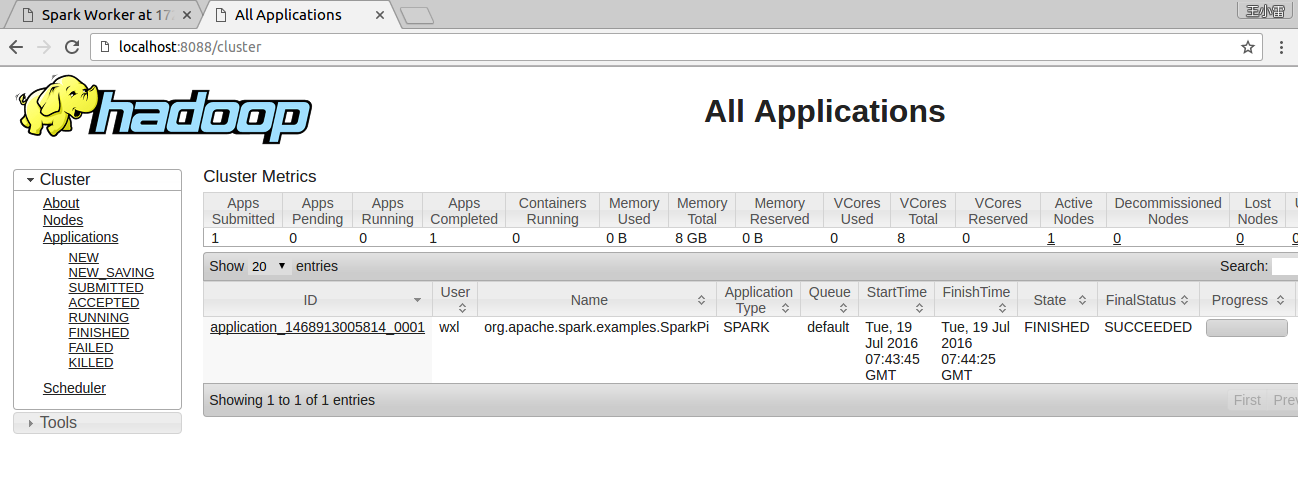
通过http://localhost:8088/cluster/apps看到执行成功SUCCEEDED
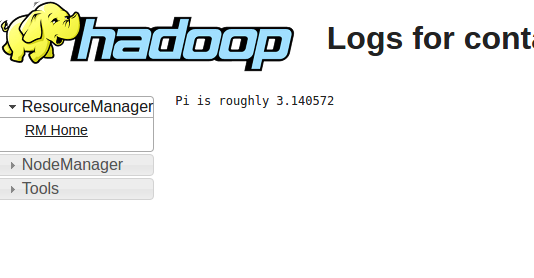
查看SparkPi运行结果,结果为Pi is roughly 3.140572。数值可能稍有不同。总之成功了!

1.绝对路径开启集群
(每次集群重启,默认配置的hadoop集群中tmp文件被清空所以需要重新format)我的集群安装位置是/opt/hadoop下,可以根据自己路径修改。
/opt/hadoop/bin/hdfs namenode -format
/opt/hadoop/sbin/start-all.sh /opt/spark/sbin/start-all.sh
使用jps命令查看集群是否全部正确开启
2.绝对路径关闭集群
/opt/hadoop/sbin/stop-all.sh /opt/spark/sbin/stop-all.sh
3.Spark业务(app)发布到Hadoop YARN集群方式
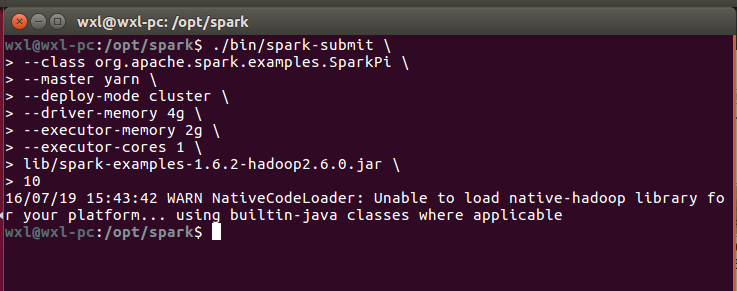
这里发布一个spark本身自带的jar发到hadoop集群中(此时hadoop和spark都已开启)cd /opt/spark
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 4g \ --executor-memory 2g \ --executor-cores 1 \ lib/spark-examples-1.6.2-hadoop2.6.0.jar \ 10
注意spark-examples-1.6.2-hadoop2.6.0.jar,需要根据你的版本来看自带的版本号。
4.log地址(方便查看错误信息)
/opt/hadoop/logs//opt/spark/logs/
5.web地址查看(可以直观的查看集群执行情况)
http://localhost:8088/cluster/appshttp://localhost:8080/
通过http://localhost:8088/cluster/apps看到执行成功SUCCEEDED
查看SparkPi运行结果,结果为Pi is roughly 3.140572。数值可能稍有不同。总之成功了!

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- Spark随谈——开发指南(译)
- 100 个最佳 Ubuntu 应用(中)
- 在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用
- 单机版搭建Hadoop环境图文教程详解
- Spark,一种快速数据分析替代方案
- windows用windeployqt发布qt quick application程序
- 24 个必备的 Linux 应用程序
- 注册表趣味应用小集
- 远程控制技术的应用
- 路由器访问列表的应用
- xDSL技术及其应用
- 基于XML的桌面应用
- Java 版的 Ruby 解释器 JRuby 1.7.14 发布
- Fedora Linux 7 Test 4 发布 下载地址
- SQL Server 2008 R2 应用及多服务器管理