Topic Model
2016-07-15 11:42
197 查看
Topic Model
标签(空格分隔): 机器学习Γ函数
Γ函数可以看做是阶乘在实数域上的推广,即:Γ(x)=∫+∞0tx−1e−tdt=(x−1)!
性质:Γ(x)Γ(x−1)=x−1
Beta分布
Beta分布的概率密度:f(x)={1B(α,β)1e377
xα−1(1−x)β−1,0,x∈[0,1]others
其中,B为∫10xα−1(1−x)β−1dx=Γ(α)Γ(β)Γ(α+β);
Beta分布的期望:E(x)=∫10x⋅f(x)dx=∫10x⋅1B(α,β)xα−1(1−x)β−1dx=αα+β
共轭先验分布
在贝叶斯决策中,已知先验概率和似然函数,求后验概率,则可以根据贝叶斯公式求得:P(θ|x)=P(x|θ)P(θ)P(x)∝P(x|θ)P(θ)
而如果后验概率P(θ|x)和先验概率P(θ)满足同样的分布律,那么,先验分布和后验分布叫做共轭分布,此时,先验分布叫做似然函数的共轭先验分布。
(当变量x是离散的时候叫做分布律,连续的时候叫做概率密度)
伯努利分布的共轭先验是Beta分布
伯努利分布的似然:P(x|θ)=θx(1−θ)1−x;先验函数为:P(θ|α,β)=1B(α,β)θα−1(1−\theta)β−1;
则后验概率为:P(θ|x)∝P(x|θ)P(θ)∝θ(x+a)−1(1−θ)(1−x+β)−1
后验概率的形式与先验概率的形式是一样的,所以伯努利分布的共轭先验是Beta分布。
从Beta分布Dirichlet分布
从2到K,* 二项分布推到多项分布;
* Beta分布推到Dirichlet分布。
Beta分布的概率密度:f(x)={1B(α,β)xα−1(1−x)β−1,0,x∈[0,1]others
其中,B(α,β)=Γ(α)Γ(β)Γ(α+β);
Dirichlet分布的概率密度:f(p|α)={1Δ(α)ΠKk=1pαk−1k,0,pk∈[0,1]others
其中,Δ(α)=ΠKk=1Γ(αk)Γ(∑Kk=1αk)
对称的Dirichlet分布
即参数αi的值都是相等的。当α=1时,退化为均匀分布;
当α>1时,p1=p2=p3=...=pk的概率增大;
当α<1时,pi=1,p非i=0的概率增大
在狄利克雷分布中,αi是参数,那么参数αi对分布有什么影响呢?
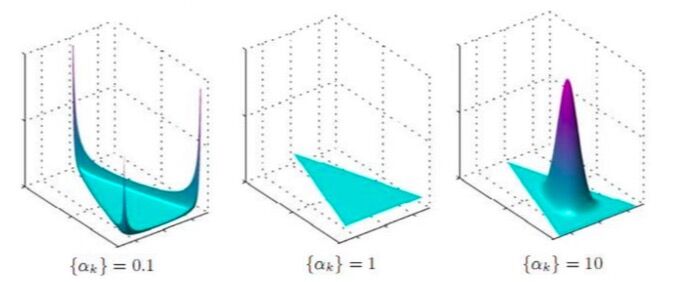
当αk<1时,即所有的参数都取k,小于1,当某个变量趋于0时,分布会取到最大值;
当αk=1时,即所有的参数都取1时,分布趋于均匀分布;
当αk>1时,即所有的参数都取k,大于1,当自变量取值都相等时,分布会取到最大值。
LDA解释 —— 贝叶斯学派的典型应用
LDA是典型的无监督学习,事先不需要知道label,也不需要知道每个topic具体是什么含义,只需给出topic的数目即可。Topic Model与聚类、降维的关系。
Topic Model可以看做是聚类,即若干个文档在K个话题下的软聚类;
Topic Model也可以看做是降维,由原来维度较高的次分布变为维度较低的主题分布,大大降低了特征向量的维度。
为什么使用多话题呢?
– 如果语料中存在一词多义和多词一义的问题,如果使用词向量作为文档的特征,一词多义和多词一义会造成基三文档间相似度的不准确性。
– 所以通过增加主题的方式解决上述问题。一个词可能被映射到多个主题中,多个词可能被映射到某个主题的概率很高。
共有m篇文档,K个主题;
每篇文章(长度为N)都有各自的主题分布(多项分布),该多项分布的参数服从Dirichlet分布,参数为为α;
每个主题都有各自的词分布(多项分布),该多项分布的参数服从Dirichlet分布,参数为β;
对于每篇文章中的第n个词,首先从该文章的主题分布中采样一个主题,然后在这个主题对应的词分布中采样一个词。不断的重塑这个随机生成过程,直到m篇文章全部完成上述过程。
LDA的概率图模型为:
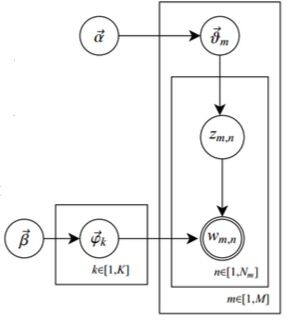
其中,α和β为先验分布的参数,一般是需要事先给定,比如取0.1的堆成Dirichlet分布,表示在参数学习结束之后,期望每个文档的主题不会十分集中;
θ是每篇文档的主题分布,是长度为K的向量;
φk表示第k个主题的词分布;
由zij选择φzij,表示由词分布φzij确定term,即得到观测值wij。
参数的学习
给定一个文档集合,wm,n是可以观察到的已知变量,α和β是根据经验给定的先验参数,其他的变量zm,n,θ,φ都是未知的隐变量,需要根据观察到的变量来学习估计。则LDA所有变量的联合分布为:p(wm,zm,θm,Φ|α,β)=ΠNmn=1p(wm,n|φzm,n)p(zm,n|θm)p(θm|α)p(Φ|β)
Gibbs Sampling
吉布斯采样算法的运行方式是每次选取概率向量的一个维度,给定其他维度的变量值采样当前维度的值。不断迭代直到收敛输出待估计的参数。初始时随机给文本中的每个词分配主题z(0),然后统计每个主题z下出现词t的数量以及每个文档m下出现主题z的数量,每一轮计算p(zi|z−i,d,w),即排除当前词的主题分布;
根据其他所有词的主题分布估计当前词分配各个主题的概率;
当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词采样一个新的主题;
用同样的方法更新下一个词的主题,直到发现每个文档的主题分布θi和每个主题的词分布φi收敛。算法停止,输出待估计的参数θ和φ,同时每个单词的主题也可以得出

相关文章推荐
- linux 免密码登录详解
- Topic Model
- Linux free 命令详解
- shell去掉最后一个字符
- linux上nginx的安装启动以及配合php-fpm的使用
- 在Linux环境下mysql的root密码忘记解决方法
- sync 数据同步写入磁盘
- cocopods的安装与使用
- CentOS7 配置YUM服务器和客户端
- Bash引用变量和转义
- find 命令的参数详解
- man 帮助
- OpenGL学习笔记(一)
- linux系统编程手册 I/O复用
- nginx的配置、虚拟主机、负载均衡和反向代理
- H5 学习资源网站
- 三、文件搜索命令【基础篇】
- Linux Bash shell (for循环)
- date 显示日期与时间
- 防御Linux下DDOS攻击