再论EM算法的收敛性和K-Means的收敛性
2016-09-19 14:47
204 查看
标签(空格分隔): 机器学习
(最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性。在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。。)
通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数θ,能够使最大似然目标函数取最大值。但是直接计算 l(θ)=∑mi=1log∑zp(x,z;θ)比较困难,所以我们希望能够找到一个不带隐变量z的函数γ(x|θ)≤l(x,z;θ)恒成立,并用γ(x|θ)逼近目标函数。
如下图所示:
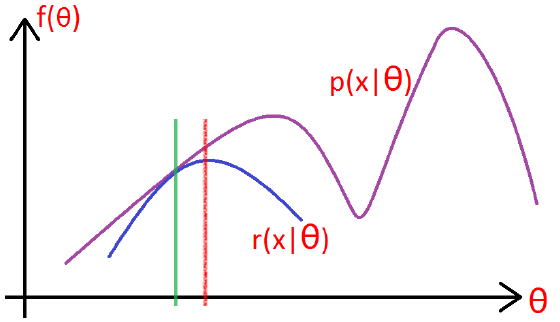
在绿色线位置,找到一个γ函数,能够使得该函数最接近目标函数,
固定γ函数,找到最大值,然后更新θ,得到红线;
对于红线位置的参数θ:
固定θ,找到一个最好的函数γ
20000
,使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
l(θ)=∑mi=1log∑z(i)p(x(i),z(i);θ)
=∑mi=1log∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))
≥∑mi=1∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
(对于log函数的Jensen不等式)
对于EM的目标来说:应该使得log函数的自变量恒为常数,即:
p(x(i),z(i);θ)Qi(z(i))=C
也就是分子的联合概率与分母的z的分布应该成正比,而由于Q是z的一个分布,所以应该保证∑zQi(z(i))=1
故Q=pp对z的归一化因子
Qi(z(i))=p(x(i),z(i);θ)∑zp(x(i),z(i);θ)
=p(x(i),z(i);θ)p(x(i);θ)=p(z(i)|x(i);θ)
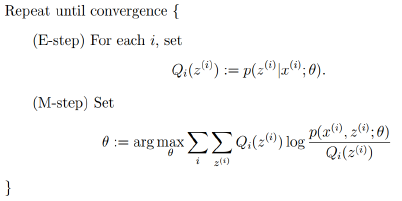
回到最初的思路,寻找一个最好的γ函数来逼近目标函数,然后找γ函数的最大值来更新参数θ:
* E-step: 根据当前的参数θ找到一个最优的函数γ能够在当前位置最好的逼近目标函数;
* M-step: 对于当前找到的γ函数,求函数取最大值时的参数θ的值。
J(μ1,μ2,...,μk)=12∑Kj=1∑Ni=1(xi−μj)2
γnk={1,0,if k=argminj||xn−μj||2 otherwise
μk=∑nγnkxn∑nγnk
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数γ;在M-step时,固定函数γ,更新均值μ(找到当前函数下的最好的值)。所以一定会收敛了~
(最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性。在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。。)
EM算法的收敛性
1.通过极大似然估计建立目标函数:
l(θ)=∑mi=1log p(x;θ)=∑mi=1log∑zp(x,z;θ)通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数θ,能够使最大似然目标函数取最大值。但是直接计算 l(θ)=∑mi=1log∑zp(x,z;θ)比较困难,所以我们希望能够找到一个不带隐变量z的函数γ(x|θ)≤l(x,z;θ)恒成立,并用γ(x|θ)逼近目标函数。
如下图所示:
在绿色线位置,找到一个γ函数,能够使得该函数最接近目标函数,
固定γ函数,找到最大值,然后更新θ,得到红线;
对于红线位置的参数θ:
固定θ,找到一个最好的函数γ
20000
,使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
2. 从Jensen不等式的角度来推导
令Qi是z的一个分布,Qi≥0,则:l(θ)=∑mi=1log∑z(i)p(x(i),z(i);θ)
=∑mi=1log∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))
≥∑mi=1∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
(对于log函数的Jensen不等式)
3.使等号成立的Q
尽量使≥取等号,相当于找到一个最逼近的下界:也就是Jensen不等式中,f(x1)+f(x2)2≥f(x1+x22),当且仅当x1=x2时等号成立(很关键)。对于EM的目标来说:应该使得log函数的自变量恒为常数,即:
p(x(i),z(i);θ)Qi(z(i))=C
也就是分子的联合概率与分母的z的分布应该成正比,而由于Q是z的一个分布,所以应该保证∑zQi(z(i))=1
故Q=pp对z的归一化因子
Qi(z(i))=p(x(i),z(i);θ)∑zp(x(i),z(i);θ)
=p(x(i),z(i);θ)p(x(i);θ)=p(z(i)|x(i);θ)
4.EM算法的框架
由上面的推导,可以得出EM的框架:回到最初的思路,寻找一个最好的γ函数来逼近目标函数,然后找γ函数的最大值来更新参数θ:
* E-step: 根据当前的参数θ找到一个最优的函数γ能够在当前位置最好的逼近目标函数;
* M-step: 对于当前找到的γ函数,求函数取最大值时的参数θ的值。
K-Means的收敛性
通过上面的分析,我们可以知道,在EM框架下,求得的参数θ一定是收敛的,能够找到似然函数的最大值。那么K-Means是如何来保证收敛的呢?目标函数
假设使用平方误差作为目标函数:J(μ1,μ2,...,μk)=12∑Kj=1∑Ni=1(xi−μj)2
E-Step
固定参数μk, 将每个数据点分配到距离它本身最近的一个簇类中:γnk={1,0,if k=argminj||xn−μj||2 otherwise
M-Step
固定数据点的分配,更新参数(中心点)μk:μk=∑nγnkxn∑nγnk
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数γ;在M-step时,固定函数γ,更新均值μ(找到当前函数下的最好的值)。所以一定会收敛了~

相关文章推荐
- 再论EM算法的收敛性和K-Means的收敛性
- what's RC means
- 英文版-Praise Baby Collection-That's What Christmas Means to Me
- Fuzzy c-means (FCM)聚类算法
- what does it means for MODULE_LICENSE in linux kernel
- 基于K-Means的文本聚类
- 数据挖掘十大算法之—K-Means
- [转]Mahout聚类算法Canopy+K-means测试实例
- 聚类算法的实现 k-means(一)
- k-means的简化版本
- This generally means that another instance of this process was already running or is hung in the deb
- 机器学习-k-means
- Study notes for Clustering and K-means
- 聚类算法初探(四)K-means
- K-Means 算法
- GMM&K-means&EM
- 斯坦福ML公开课笔记12——K-Means、混合高斯分布、EM算法
- k-means
- 【数据挖掘】聚类之k-means
- k-means聚类原理 代码分析