日常笔记:Python(1)
2016-07-14 20:02
721 查看
Preface
Code Zoo,就是想把我平时写的一些代码,如脚本工具啊什么的,整理集中起来。供以后参考,也给需要的同学一点线索。统计文件夹下的文件数量:
import os import os.path dir = "/home/chenxp/Documents/vehicleID/train/font_vehicleID" i = 0 for root, dirs, files in os.walk(dir): for name in files: i = i + 1 print i
读取 XML 文件内容
最近在忙一个比赛,主办方给我们一个 XML 文件,我们需要根据这个 XML 文件读取图像的文件名这类信息。如下: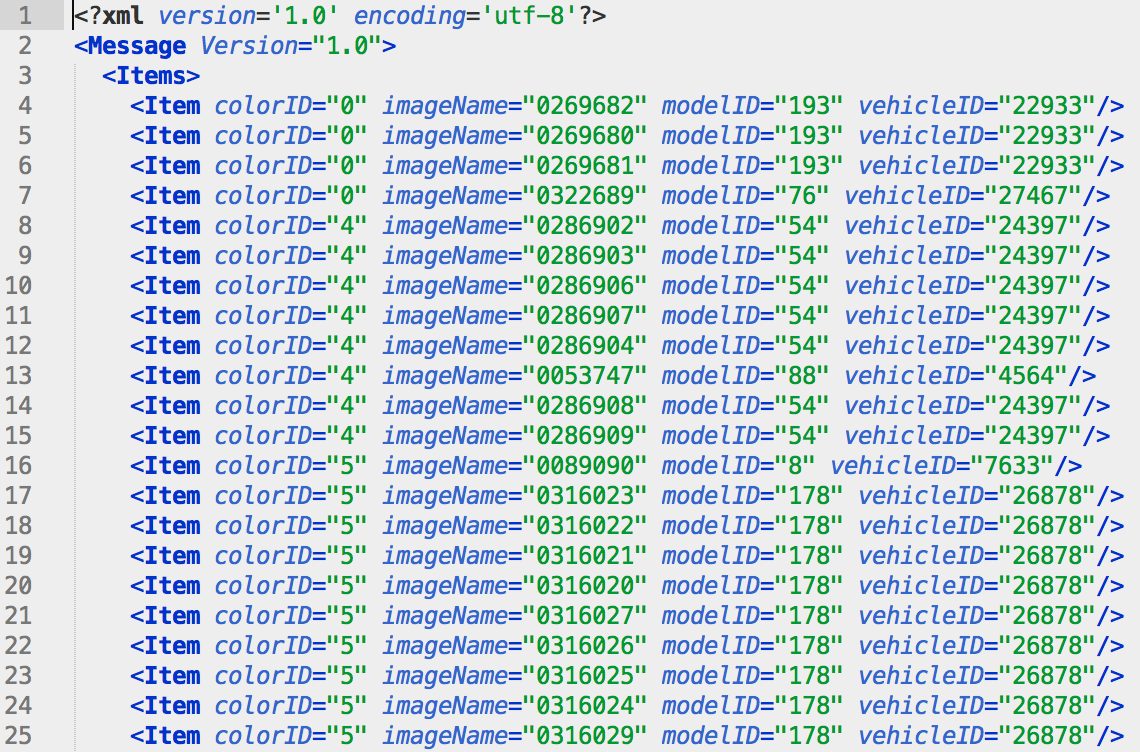
根据这个文件,再结合主办方给的数据集,就可以根据
modelID或者
vehicleID标签,把给的数据集进行分类。比如,我要根据
vehicleID标签把数据集按照这个
vehicleID分类,就是把具有相同的
vehicleID归类到一个文件夹中。主办方给的数据集如下:

下面就是读取 XML 文件里的属性数据了,代码如下:
# !/usr/bin/env python
# encoding-utf:8
from xml.dom.minidom import parse, parseString
import os
import glob
from PIL import Image
#outDir1 = os.path.abspath('/Users/chenxinpeng/Desktop/train/vehicleID/')
# read the images into the imglist, get the basename of images
imgNames = []
imglists = glob.glob('/home/chenxp/Documents/vehicleID/train/images/*.jpg')
for img in imglists:
imgNames.append(os.path.basename(img))
# test
print imglists[0]
# 进行 XML 文件的解析
# begin parse the xml file
dom = parse('train_gt.xml') # parse an XML file by name
# get document object
# 得到根结点
root = dom.documentElement
# 根据标签名 Item ,得到 Item 所有的属性及其属性值
# 比如属性 colorID、imageName、modelID、vehicleID
# 及这几个属性对应的属性值,放入到 itemlist 中
itemlist = root.getElementsByTagName("Item")
XML_imageNames = []
XML_colorIDs = []
XML_modelIDs = []
XML_vehicleIDs = []
# 根据属性,得到这个属性的所有元素值,放入到 list 中
for item in itemlist:
XML_imageNames.append(item.getAttribute("imageName"))
XML_colorIDs.append(item.getAttribute("colorID"))
XML_modelIDs.append(item.getAttribute("modelID"))
XML_vehicleIDs.append(item.getAttribute("vehicleID"))
# test
print XML_imageNames[0]
print XML_colorIDs[0]
print XML_modelIDs[0]
print XML_vehicleIDs[0]
# 用 set 去除掉 XML_vehicleIDs 中所有重复的 vehicleID
shrink_XML_vehicleIDs = sorted(set(XML_vehicleIDs), key = XML_vehicleIDs.index)
print len(shrink_XML_vehicleIDs)
# 遍历不重复的 vehicleID
for item in shrink_XML_vehicleIDs:
# 创建 vehicleID 文件夹, 里面存放所有具有相同 vehicleID 的图片
os.mkdir("/home/chenxp/Documents/vehicleID/vehicleID/" + item)
outDir1 = os.path.abspath('/home/chenxp/Documents/vehicleID/vehicleID/' + item)
# 用 enumerate 遍历 XML_vehicleIDs 中所有与当前遍历的item(vehicleID)相同的元素, 及其元素的索引
indexImg = [i for (i, v) in enumerate(XML_vehicleIDs) if v == item]
# 根据索引 list, 保存这些图片
for imgItem in indexImg:
indexTemp = imgNames.index(XML_imageNames[imgItem]+'.jpg')
dir = imglists[indexTemp]
imgTemp = Image.open(dir)
t = os.path.basename(dir)
imgTemp.save(os.path.join(outDir1, t))若想根据之前 XML 中的
modelID来归类,将具有相同
modelID的图像归到一个文件夹中,代码如下:
# !/usr/bin/env python
# encoding-utf:8
from xml.dom.minidom import parse, parseString
import os
import glob
from PIL import Image
# read the images into the imglist, get the basename of images
imgNames = []
imglists = glob.glob('/home/chenxp/Documents/vehicleID/train/images/*.jpg')
for img in imglists:
imgNames.append(os.path.basename(img))
# test
print imglists[0]
# begin parse the xml file
dom = parse('train_gt.xml') # parse an XML file by name
# get document object
root = dom.documentElement
itemlist = root.getElementsByTagName("Item")
XML_imageNames = []
XML_colorIDs = []
XML_modelIDs = []
XML_vehicleIDs = []
for item in itemlist:
XML_imageNames.append(item.getAttribute("imageName"))
XML_colorIDs.append(item.getAttribute("colorID"))
XML_modelIDs.append(item.getAttribute("modelID"))
XML_vehicleIDs.append(item.getAttribute("vehicleID"))
# test
print XML_imageNames[0]
print XML_colorIDs[0]
print XML_modelIDs[0]
print XML_vehicleIDs[0]
shrink_XML_modelIDs = sorted(set(XML_modelIDs), key = XML_modelIDs.index)
print len(shrink_XML_modelIDs)
for item in shrink_XML_modelIDs:
os.mkdir("/home/chenxp/Documents/vehicleID/attributeSame/" + item)
outDir2 = os.path.abspath('/home/chenxp/Documents/vehicleID/attributeSame/' + item)
indexModel = [i for (i, v) in enumerate(XML_modelIDs) if v == item]
for modelItem in indexModel:
indexTemp = imgNames.index(XML_imageNames[modelItem] + '.jpg')
dir = imglists[indexTemp]
imgTemp = Image.open(dir)
t = os.path.basename(dir)
imgTemp.save(os.path.join(outDir2, t))用 python 将 TXT 文件内容写入 XML
若我有一些txt文本文件,如下所示:
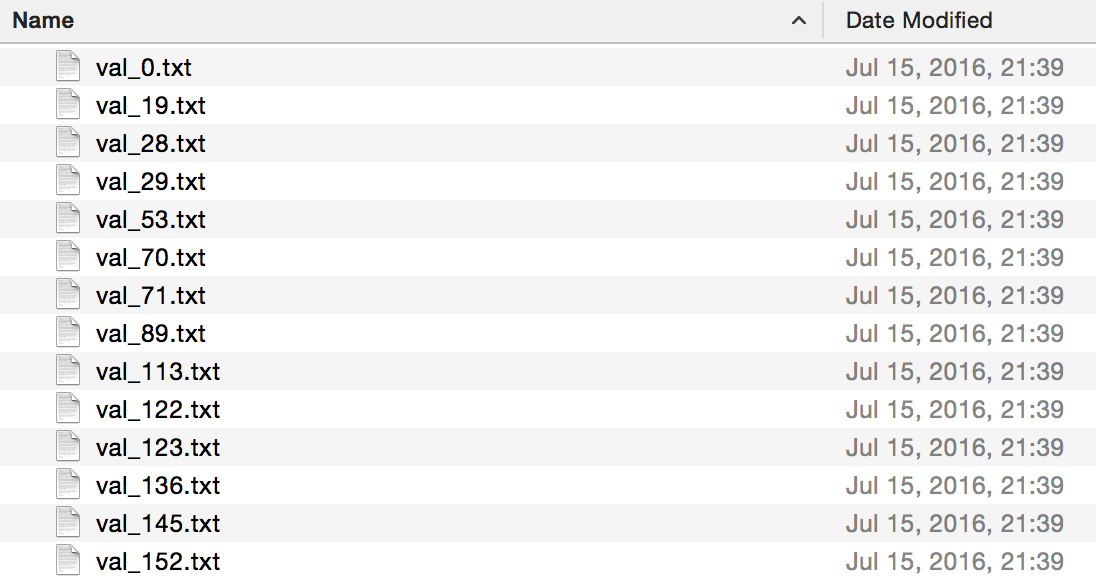
每个
txt文件内容,如下内容:
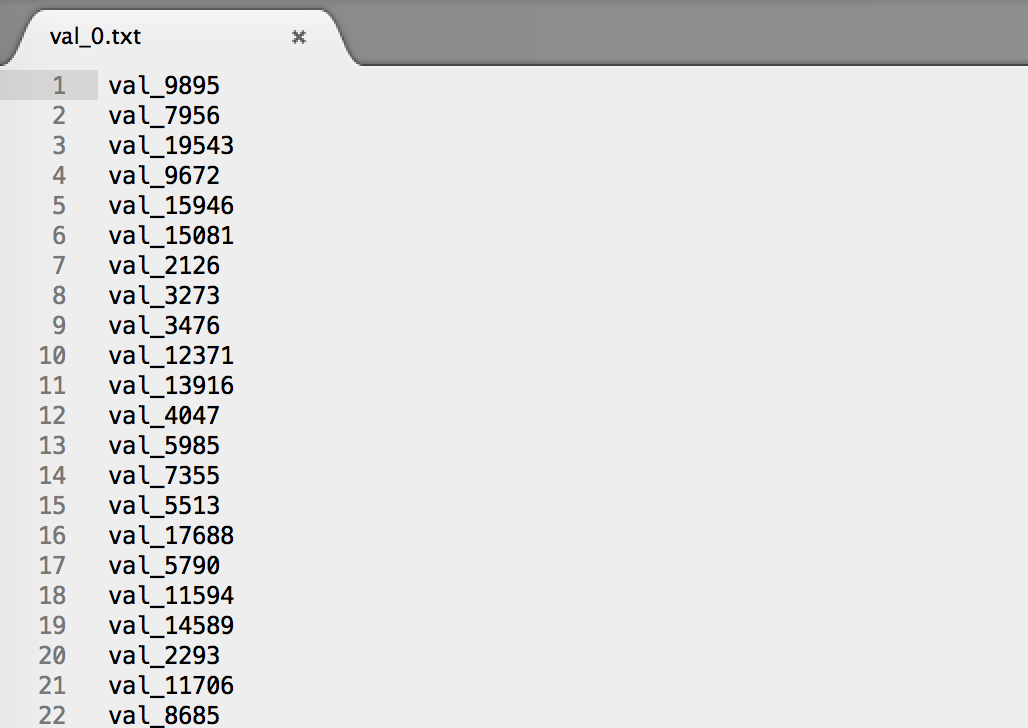
现在的任务是,以这些
txt文件的文件名为 XML 文件里的属性名称,以属性值为对应的
txt文本中的所有值,用空格隔开这些值。主办方示例如下:
<?xml version="1.0" encoding="gb2312"?> <Message Version="1.0"> <Info evaluateType="6" mediaFile="vehicle_retrieval_val" /> <Items> <Item imageName="012321 "> 0292851 0110741 0173591 0092564 0286241 0192567 0340982 ... </Item> <Item imageName="003467 "> 0387241 0023986 0283751 0230114 9806431 8823012 2389102 ... </Item> <Item imageName="13169 "> 3727192 0387654 0007942 0009866 0120397 0485764 1200341 ... </Item> ...... </Items> </Message>
生成这段 XML 的代码如下:
import os
import os.path
import xml.etree.cElementTree as ET
srcDir = "/Users/chenxinpeng/Desktop/today/txtFile"
# 遍历 txtFiles 文件夹下, 所有的 .txt 文件
# 将文件名放入列表: txtFiles
txtFiles = []
for root, dirs, txtNames in sorted(os.walk(srcDir)):
for txtName in txtNames:
txtFiles.append(txtName)
# 去掉 TXT 文件名的后缀(.txt)
txtFilesBase = []
for item in txtFiles:
a, b = os.path.splitext(item)
txtFilesBase.append(a)
# test
print(txtFiles)
print(txtFilesBase)
root = ET.Element("Message")
root.set('Version', '1.0')
subRoot = ET.SubElement(root, "Items")
for eachTxtFile in txtFiles:
refImgs = []
allNames = '' # 预先定义好大的字符串
# 用 with open() as f 的方式来打开文件夹
# 这样不需要自己去 f.close(), 关闭文件
with open(os.path.join(srcDir, eachTxtFile)) as f:
# 按行读取, 用 strip() 函数去除: '\n'
for line in f.readlines():
line = line.strip('\n')
refImgs.append(line)
# 将 refImgs 这个 list 中的元素,合并成一个大的字符串
# 并用 空格(' ') 隔开
length = len(refImgs)
for i in range(0, length):
allNames = refImgs[i] + ' ' + allNames
ET.SubElement(subRoot, "Item", imageName = txtFilesBase[txtFiles.index(eachTxtFile)]).text = allNames
tree = ET.ElementTree(root)
tree.write('vehicleID.xml')这里补充一下:
1. 打开文件夹的方式可以参考 stackoverflow 上的这篇回答:http://stackoverflow.com/questions/8009882/how-to-read-large-file-line-by-line-in-python
2. python 按行读取文件,如何去掉换行符
\n,可以参考:http://blog.csdn.net/jfkidear/article/details/7532293
3. 用 python 写入 XML 文件,可以参考:http://stackoverflow.com/questions/3605680/creating-a-simple-xml-file-using-python,以及:https://pymotw.com/2/xml/etree/ElementTree/create.html
用 python 重命名文件
如何给一堆 TXT 文件重命名?如下,有一堆 TXT 文件:
现在我要对这些 TXT 文件,在其文件名后,加 1。即,如果文件名为:
begin56list.txt,加 1 变成:
begin56list1.txt。
这个用 python 的
os.rename或者 shutil 模块可以很快的完成,如下:
import os import sys import shutil Dir = '/Users/chenxinpeng/Desktop/list' for root, dirs, files in Dir: for item in files: temp1, temp2 = os.path.splitext(item) shutil.move(item, temp1 + '1.txt')
这样就完成了,我用的是 shutil 的
shutil.move()命令,参考 stackoverflow 的这个问答里:http://stackoverflow.com/questions/2491222/how-to-rename-a-file-using-python
判断文件、文件夹是否存在
python 判断文件、文件夹是否存在就一句:import os
os.path.isfile("test.txt") # 如果不存在就返回 False
os.path.exists("/home/chenxp/*") # 如果不存在就返回 False去除 lists 中重复元素
现在我有一个 lists,怎样去除其中重复的元素呢?x = [0, 2, 2, 4, 3, 5, 6, 5, 0, 2] # shrink_x 代表去除重复元素后的 x shrink_x = list(set(x)) print(shrink_x)
结果见下:

不过上面的这种去除重复元素,是排序过了的。如果要想保持原来的次序:
x = [0, 2, 2, 4, 3, 5, 6, 5, 0, 2] # shrink_x 代表去除重复元素后的 x shrink_x = sorted(set(x), key = x.index) print(shrink_x) # 或者 shrink_x.sort(key = x.index)

也可以使用遍历:
x = [0, 2, 2, 4, 3, 5, 6, 5, 0, 2] y = [] for item in x: if not item in y: y.append(item) print(y)
车辆精确检索之 modelID、 vehicleID 问题
还是那个车辆精确检索的任务,这回是想,将训练图像中 modelID 相同的同一类车,先新建一个 modelID 文件夹,然后再在 modelID 下,根据每辆车的 vehicleID ,新建 vehicleID,并将 vehicleID 相同的保存在这个文件夹。最后的目录结构如下:总的是叫做 train_modelID_vehicleID。之下,则是 0、1、2、4、6、7、8、10、11、12 …… 这类 modelID 文件夹,里面的车辆都是 modelID 相同的。相同 modelID 之下,如 modelID = 6,这个 modelID 之下,有许多不同的车辆,每个文件夹名称代表了 vehicleID,如:2413、8368、16447、26525 。
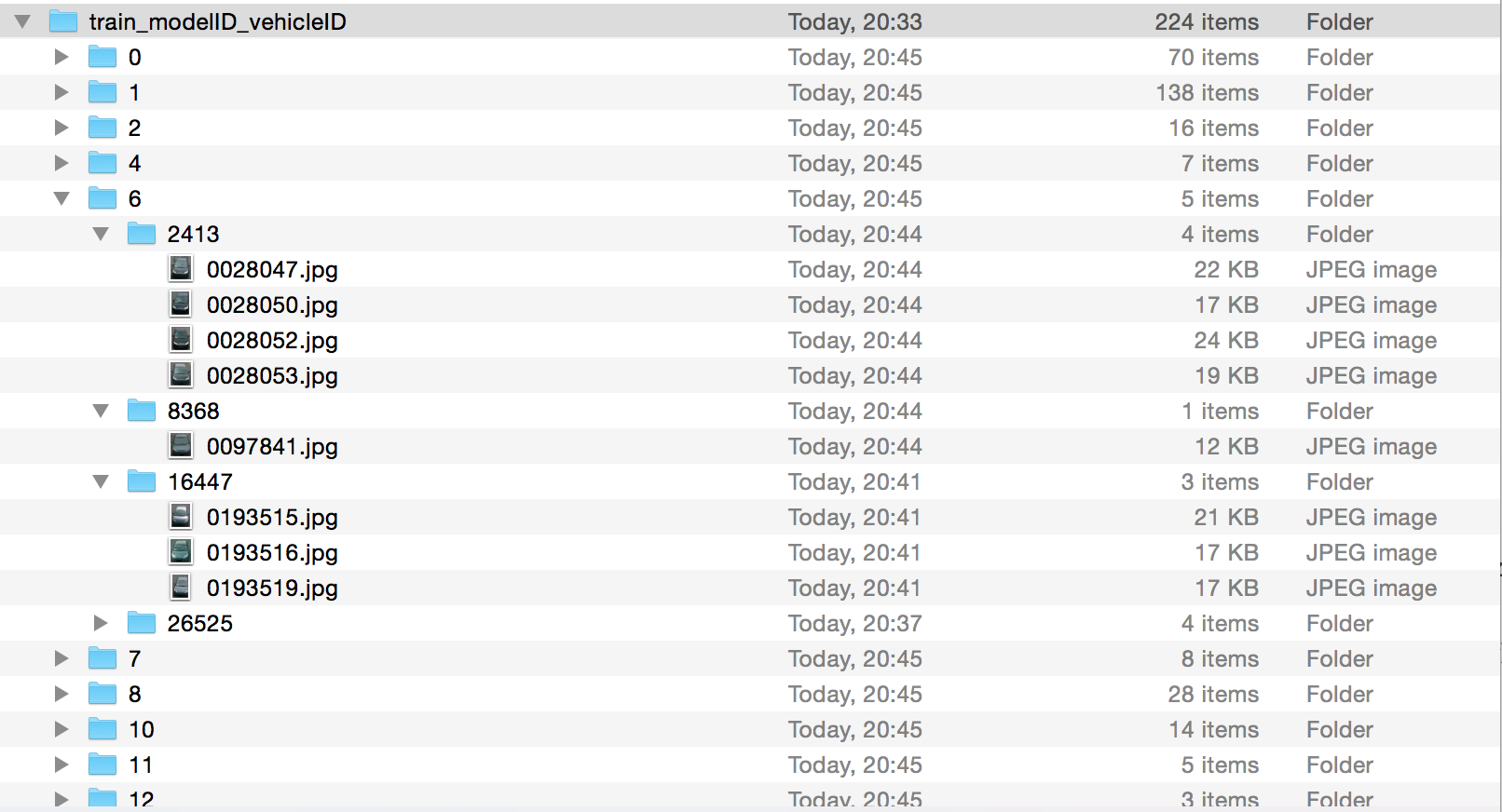
给的 XML 文件如下,里面有 modelID、vehicleID 的信息:

那这个任务怎么实现呢?虽然很简答,但我相岔了,耗费了不少时间…在这里记录下来:
from xml.dom.minidom import parse, parseString
import os
import glob
from PIL import Image
outDir1 = os.path.abspath("/Users/chenxinpeng/Desktop/today/vehicleID/train_modelID_vehicleID")
# read the images into the imglist, get the basename of images
imgNames = []
imglists = glob.glob('/Users/chenxinpeng/Desktop/today/train_font/*.jpg')
for img in imglists:
imgNames.append(os.path.basename(img))
backNames = []
imglists2 = glob.glob('/Users/chenxinpeng/Desktop/train_back/*.jpg')
for img in imglists2:
backNames.append(os.path.basename(img))
# begin parse the xml file
dom = parse('train_gt.xml') # parse an XML file by name
# get document object
root = dom.documentElement
itemlist = root.getElementsByTagName("Item")
XML_imageNames = []
XML_colorIDs = []
XML_modelIDs = []
XML_vehicleIDs = []
for item in itemlist:
if (item.getAttribute("imageName") + '.jpg') in backNames:
continue
XML_imageNames.append(item.getAttribute("imageName"))
XML_colorIDs.append(item.getAttribute("colorID"))
XML_modelIDs.append(item.getAttribute("modelID"))
XML_vehicleIDs.append(item.getAttribute("vehicleID"))
shrink_XML_modelIDs = sorted(set(XML_modelIDs), key = XML_modelIDs.index)
shrink_XML_vehicleIDs = sorted(set(XML_vehicleIDs), key = XML_vehicleIDs.index)
# 新建 modelID 文件夹,防止后面出现 ‘no such file or directory‘ 的情况
for item in shrink_XML_modelIDs:
os.mkdir(outDir1 + item)
# 对于 每一个 vehicleID 进行遍历
for vehicleID_item in shrink_XML_vehicleIDs:
# 找出 vehicleID 相同的所有图像,返回它们的索引
indexVehicleID = [i for (i, v) in enumerate(XML_vehicleIDs) if (v == vehicleID_item)]
# vehicleID 相同的,其 modelID 也一定相同
# 加上 XML_vehicleIDs、XML_modelIDs 顺序一样
# 所以找到这辆车的 modelID,在这个 modelID 下新建文件夹
# 这里的 kk 名字是随意取的
kk = XML_vehicleIDs.index(vehicleID_item)
outDir3 = ourDir1 + XML_modelIDs[kk] + '/' + vehicleID_item
os.mkdir(outDir3)
# 对于每一张 vehicleID 相同的图像,进行读取并保存
for imgItem in indexVehicleID:
# vehicleID 与 图像的 imageName 是一一对应的
indexTemp = imgNames.index(XML_imageNames[imgItem] + '.jpg')
dirTemp = imglists[indexTemp]
imgTemp = Image.open(dirTemp)
t = os.path.basename(dirTemp)
imgTemp.save(os.path.join(outDir3, t))用 python 生成 Triplet Loss 所需要的训练数据
Triplet Loss 生成数据需要一张 Anchor 图像、一张 Positive 图像、一张 Negative 图像。如何从给定的训练数据中自动生成呢?from xml.dom.minidom import parse, parseString
import os
import glob
import random
from PIL import Image
#outDir1 = os.path.abspath('/Users/chenxinpeng/Desktop/train/vehicleID/')
backLists = glob.glob('/home/chenxp/Documents/vehicleID/train/train_back/*.jpg')
backNames = []
for item in backLists:
backNames.append(os.path.basename(item))
# read the images into the imglist, get the basename of images
imgNames = []
imglists = glob.glob('/home/chenxp/Documents/vehicleID/train/train_font/*.jpg')
for img in imglists:
imgNames.append(os.path.basename(img))
# test
print len(imglists)
# begin parse the xml file
dom = parse('train_gt.xml') # parse an XML file by name
# get document object
root = dom.documentElement
itemlist = root.getElementsByTagName("Item")
XML_imageNames = []
XML_colorIDs = []
XML_modelIDs = []
XML_vehicleIDs = []
for item in itemlist:
if (item.getAttribute("imageName") + '.jpg') in backNames:
continue
XML_imageNames.append(item.getAttribute("imageName"))
XML_colorIDs.append(item.getAttribute("colorID"))
XML_modelIDs.append(item.getAttribute("modelID"))
XML_vehicleIDs.append(item.getAttribute("vehicleID"))
# test
print len(XML_imageNames)
print len(XML_colorIDs)
print len(XML_modelIDs)
print len(XML_vehicleIDs)
shrink_XML_vehicleIDs = sorted(set(XML_vehicleIDs), key = XML_vehicleIDs.index)
print(len(shrink_XML_vehicleIDs))
openDir = '/home/chenxp/Documents/vehicleID/train/font_vehicleID'
fd = open('/home/chenxp/Documents/vehicleID/train/tripletImg.txt', 'w')
numFiles = []
for item in shrink_XML_vehicleIDs:
numFiles[:] = []
openDir2 = openDir + '/' + item
for root, dirs, files in os.walk(openDir2):
for itemFile in files:
numFiles.append(itemFile)
negImgTemp = []
posImgTemp = []
if len(numFiles) >= 2:
temp_shrink_XML_vehicleIDs = []
temp_shrink_XML_vehicleIDs = shrink_XML_vehicleIDs
temp_shrink_XML_vehicleIDs.remove(item)
#posImgTemp = random.sample(numFiles, 2)
negImgTemp = random.sample(temp_shrink_XML_vehicleIDs, 100)
for item2_neg_vehicleID in negImgTemp:
numFiles2 = []
numFiles2[:] = []
for root2, dirs2, files2 in os.walk(openDir + '/' + item2_neg_vehicleID):
for itemFile2 in files2:
numFiles2.append(itemFile2)
negImgTemp2 = random.sample(numFiles2, 1)
posImgTemp = random.sample(numFiles, 2)
temp1 = openDir2 + '/' + posImgTemp[0]
temp2 = openDir2 + '/' + posImgTemp[1]
fd.write(temp1)
fd.write(' ')
fd.write(temp2)
fd.write(' ')
temp3 = openDir + '/' + item2_neg_vehicleID + '/' + negImgTemp2[0]
fd.write(temp3)
fd.write('\n')
fd.close()最后生成的 TXT 文件,其中每一行,先存储 Anchor 图像的绝对路径,再存储 Positive 图像的绝对路径,再存储一张 Negative 图像的绝对路径。示例图如下:

之后,生成训练数据时,从上面的这个 TXT 文件中读取图像,再存储为 Tensor(因为我是用的 Torch)。
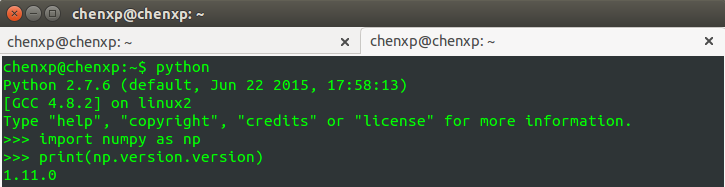
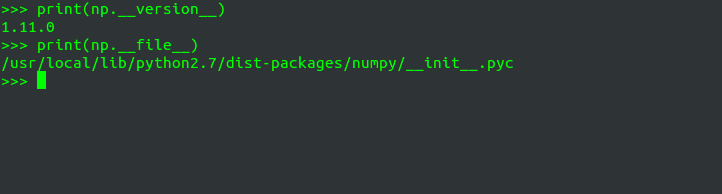
查看 numpy 版本、安装位置
2016.07.29 更新import numpy as np print(np.version.version) # 或者 print(np.__version__) # 显示安装位置: print(np.__file__)
显示如下:
反转字符串
Python 中反转字符串很简单,用切片的方式一句话解决:s = "hello world" print(s[::-1])
输出:

切片的语法,参考:https://docs.python.org/2/whatsnew/2.3.html#extended-slices,如下:
[begin:end:step]
如:
s = "hello world" print s[0:4:2]
输出为:

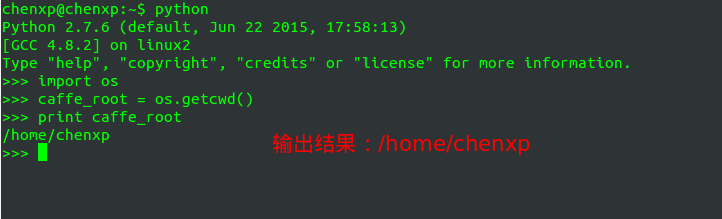
通过 os 模块获取当前路径
2016.09.11 更新通过
os模块中的
getcwd函数获取当前路径:
import os root = os.getcwd() print root
输出如下:
lambda 表达式
2016.09.12 更新lambda 表达式就是一个 匿名函数,通常 python 中定义一个函数,需要用如下方式:
def function_name(parameters) ......
但是有时候,这个定义的函数,我们仅仅使用一次。那为了这一次的使用,而去再定义一个函数,就显得很麻烦,多定义了一个(污染环境的)函数。
这种情况下,python 中通过
lambda表达式支持 匿名函数 的创建。但是,Python对匿名函数的支持有限,只有一些简单的情况下可以使用匿名函数
如下:
a = lambda x, y: x+y print a(1,2)
还可以通过
map做稍复杂的事情:
a = [1, 2, 3, 4, 5] b = map(lambda x: x + 1, a) print b
上面的两个例子输出结果如下:

给一个知乎上大神的回答作为参考,写得很棒很清晰:Lambda 表达式有何用处?如何使用?
python 的 GUI 编程
2016.09.26 更新早上看到这篇文章:Python 的图形界面(GUI)编程?,讲了几个 python 中可实现 GUI 编程的几个框架:
PyQt
wxPython
Tkinter模块
PySide
查看 h5py 文件
2016.10.06 更新import h5py
db = h5py.File('.../results/SynthText.h5', 'r')
dsest = db.keys()
print dsets输出为:

这样就能查看
h5文件中的 keys 了。
用 OS 模块新建 txt 文件
2016.10.12 更新import os
#新建 txt 文件
os.mknod("***.txt")用 pip 升级 python 模块
2016.10.21 更新如要升级
Cython模块,从 0.20 版本升级到最新的版本:
sudo pip install cpthon --upgrade

s升级完成后:

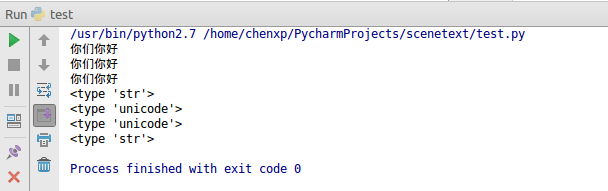
中文字符编码与转换问题
2016.11.03 更新来源:Python普通字符串和Unicode相加问题?
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# tankywoo@2013-02-24
name = '你好'
s = u'你们'
print s + unicode(name, 'utf-8')
print s + name.decode('utf-8')
print s.encode('utf-8') + name
print type(name)
print type(s)
print type(name.decode('utf-8'))
print type(s.encode('utf-8'))输出结果:
在循环中获取索引(数组下标)
2016.11.04 更新ints = [8, 23, 45, 12, 78],当我循环这个列表时如何获得它的索引下标?
如果像C或者PHP那样加入一个状态变量那就太不pythonic了.
最好的选择就是用内建函数 enumerate:
for idx, val in enumerate(ints): print idx, val

相关文章推荐
- 【Python】winpython下的包安装
- python decode-encode
- python点滴:读取和整合文件夹下的所有文件
- phthon 入门1
- python 复杂表达式
- python 简易ftp服务器开启
- python 生成列表
- python迭代dict的key和value
- python 迭代dict的value
- Python-OpenCV 处理图像(三):图像像素点操作
- python 索引迭代
- 在用python数据分析时一些应用
- python 切片
- python 学习笔记
- python基础语法
- Python最好用的模板引擎Jinja
- Python机器登陆新浪微博代码示例
- Python yield
- python传说中的验证码识别
- python 模块学习_os